Enrich Data by Using SSPs: Add Extra Data to Files
You can create self-service Tetra Data pipelines (SSPs) to get information from other files within the Tetra Scientific Data Cloud, and then use that historical data to augment new data.
This topic provides an example setup for adding extra data to files by using an SSP.
Architecture
The following diagram shows an example SSP workflow for enriching files with extra data:
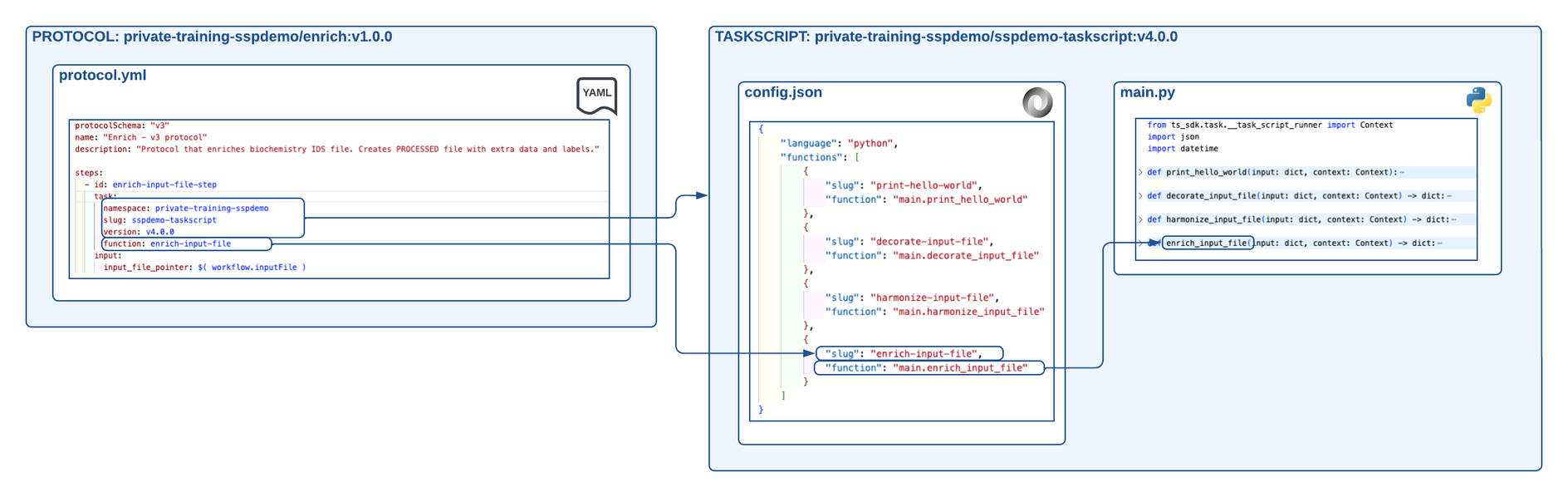
Example SSP workflow for enriching data
The diagram shows the following workflow:
- The “Hello, World!” SSP Example
sspdemo-taskscripttask script version is updated tov4.0.0. Theconfig.jsonfile has four exposed functions:- print-hello-world (
main.print_hello_world), which is theprint_hello_worldfunction found in themain.pyfile. - decorate-input-file (
main.decorate_input_file), which is thedecorate_input_filefunction found in themain.pyfile. - harmonize-input-file (
main.harmonize_input_file), which is theharmonize_input_filefunction found in themain.pyfile. - enrich-input-file (
main.enrich_input_file), which is theenrich_input_filefunction found in themain.pyfile.
- print-hello-world (
- A protocol named
enrich (v1.0.0)is created. Theprotocol.ymlfile provides the protocol name, description, and outlines one step:enrich-input-file-step. This step points to thesspdemo-taskscripttask script and the exposed function,enrich-input-file. The input to this function is the input file that kicked off the pipeline workflow.
NOTE
For an example SSP folder structure, see SSP Folder Structure in the "Hello, World!" SSP Example.
Create and Deploy the Task Script
Task scripts are the building blocks of protocols, so you must build and deploy your task scripts before you can deploy a protocol that uses them.
Task scripts require the following:
- A
config.jsonfile that contains configuration information that exposes and makes your Python functions accessible so that protocols can use them. - A Python file that contains python functions (
main.pyin the following examples) that include the code that’s used in file processing. - A
requirements.txtfile that either specifies any required third-party Python modules, or that is left empty if no modules are needed.
To create and deploy a task script that retrieves information from other files within the Tetra Scientific Data Cloud, and then uses that historical data to augment the processed file, do the following.
NOTE
For more information about creating custom task scripts, see Task Script Files. For information about testing custom task scripts locally, see Create and Test Custom Task Scripts.
Create a config.json File
config.json FileCreate a config.json file in your code editor by using the following code snippet:
{
"language": "python",
"runtime": "python3.11",
"functions": [
{
"slug": "print-hello-world",
"function": "main.print_hello_world"
},
{
"slug": "decorate-input-file",
"function": "main.decorate_input_file"
},
{
"slug": "harmonize-input-file",
"function": "main.harmonize_input_file"
},
{
"slug": "enrich-input-file",
"function": "main.enrich_input_file"
}
]
}
NOTE
You can choose which Python version a task script uses by specifying the
"runtime"parameter in the script'sconfig.jsonfile. Python versions 3.7, 3.8, 3.9, 3.10, and 3.11 are supported currently. If you don't include a"runtime"parameter, the script uses Python v3.7 by default.
Update Your main.py File
main.py FileUsing the task script from Harmonize Data by Using SSPs: Map RAWS Files to IDS Files, add the following elements to your task script:
# Add this new function
def enrich_input_file(input: dict, context: Context) -> dict:
# Perform elasticsearch query
# This query could also be in a configuration element and be passed to task-script
# Here it's hardcoded and there is only one file on the test platform that it finds.
elasticsearch_query = {
"query": {
"bool": {
"must": [
{
"term": { "category": "RAW" }
},
{
"nested": {
"path": "labels",
"query": {
"bool": {
"must": [
{
"term": {
"labels.name": "enrichment-file"
}
},
{
"term": {
"labels.value": "enrichment-file"
}
}
]
}
}
}
}
]
}
}
}
# Take contents of file and add a label
print("Using Elasticsearch")
eql_file_pointers = context.search_eql(payload=elasticsearch_query, returns="filePointers")
# Open the file and import json
print("Getting extra file contents")
f = context.read_file(eql_file_pointers[0], form='file_obj')
enrichfile_data = f['file_obj'].read().decode("utf-8")
# This file has some labels and then some other data
# ASSUMPTION: This extra file has a specific format and can be parsed to add data to IDS
print("Get Labels and Data")
labels, data = enrichfile_data.split('\n\ndata')
labels_to_add = [{"name": x.split(", ")[0], "value": x.split(", ")[1]} for x in labels.split('\n')]
data_to_add = [[int(y) for y in x.split(',')] for x in data.split('\n')[1:-1]]
# Get IDS input file and add to the json
print("Get IDS File info")
input_file_pointer = input["input_file_pointer"]
g = context.read_file(input_file_pointer, form='file_obj')
ids_data = g['file_obj'].read().decode("utf-8")
ids_json = json.loads(ids_data)
ids_json["extra_data"] = data_to_add
# Save this file to S3 as PROCESSED and save pointer to return
print("Saving PROCESSED file")
saved_processed = context.write_file(
content=json.dumps(ids_json),
file_name="processed_demo.json",
file_category="PROCESSED",
)
# Add labels to processed file
print("Adding labels")
added_labels = context.add_labels(
file=saved_processed,
labels=labels_to_add,
)
print("'enrich_input_file' completed")
return saved_processed
Context API
In the Python code provided in this example setup, the Context API is used by importing it in the main.py file (from ts_sdk.task.__task_script_runner import Context). The Context section provides the necessary APIs for the task script to interact with the TDP.
This example setup uses the following Context API endpoint:
- context.search_eql: Searches files by using Elasticsearch Query Language (EQL)
NOTE
When using the
context.search_eqlendpoint, keep in mind the following:
- To have the file pointer parameter read file contents, make sure that you supply
returns = "filePointers"in the API request.- Inefficient EQL searches can cause performance issues. When initially testing this setup, make sure that your query returns one file only.
IMPORTANT
The task script example provided in this procedure includes a hardcoded EQL query for demonstration purposes.
Instead of hardcoding an EQL query in your production environment, it’s a best practice to create a configuration element in your
protocol.ymlfile instead. This config context allows users to input an EQL query as an input when creating a pipeline by using the protocol. Then, yourprotocol.ymlfile can use that query as an input to the protocol step, which then runs the task script function.
Create a Python Package
Within the task script folder that contains the config.json and main.py files, use Python Poetry to create a Python package and the necessary files to deploy them to the TDP.
Poetry Command Example to Create a Python Package
poetry init
poetry add datetime
poetry export --without-hashes --format=requirements.txt > requirements.txt
NOTE
If no packages are added, this
poetry exportcommand example produces text inrequirements.txtthat you must delete to create an emptyrequirements.txtfile. However, for this example setup, there’s adatetimepackage, sorequirements.txtshouldn't be empty. Arequirements.txtfile is required to deploy the package to the TDP.
Deploy the Task Script
To the deploy the task script, run the following command from your command line (for example, bash):
ts-sdk put task-script private-{TDP ORG} sspdemo-taskscript v4.0.0 {task-script-folder} -c {auth-folder}/auth.json
NOTE
Make sure to replace
{TDP ORG}with your organization slug,{task-script-folder}with the local folder that contains your protocol code, and{auth-folder}with the local folder that contains your authentication information.Also, when creating a new version of a task script and deploying it to the TDP, you must increase the version number. In this example command, the version is increased to
v4.0.0.
Add a File to the TDP to Use When Enriching Data
NOTE
The EQL query that’s used in the the example task script searches the TDP for a RAW file that has an
enrichment-filelabel name and a value ofenrichment-file.
To add a file to the TDP, which you’ll use to enrich existing files, do the following:
- Create a text file that includes your enrichment data. For this example setup, add the following contents to the file:
experiment, example-experiment
lab, example-lab
location, example-location
data
1,2,3,4
5,6,7,8
- Upload the file to the TDP and provide the required label. Then when running your pipeline with the protocol and task script, your pipeline will now search the TDP for this file and use its contents.
Create and Deploy a Protocol
Protocols define the business logic of your pipeline by specifying the steps and the functions within task scripts that execute those steps. For more information about how to create a protocol, see Protocol YAML Files.
In the following example, there’s one step: enrich-input-file-step. This step uses the enrich-input-file function that’s in the sspdemo-taskscript task script, which is v4.0.0 of the task script.
Create a protocol.yml File
protocol.yml FileCreate a protocol.yml file in your code editor by using the following code snippet:
protocolSchema: "v3"
name: "Enrich - v3 protocol"
description: "Protocol that enriches biochemistry IDS file. Creates PROCESSED file with extra data and labels."
steps:
- id: enrich-input-file-step
task:
namespace: private-training-sspdemo
slug: sspdemo-taskscript
version: v4.0.0
function: enrich-input-file
input:
input_file_pointer: $( workflow.inputFile )
NOTE
When using a new task script version, you must use the new version number when we’re calling that task script in the protocol step. This example
protocol.ymlfile refers tov4.0.0.
Deploy the Protocol
To the deploy the protocol, run the following command from your command line (for example, bash):
ts-sdk put protocol private-{TDP ORG} enrich v1.0.0 {protocol-folder} -c {auth-folder}/auth.json
NOTE
Make sure to replace
{TDP ORG}with your organization slug,{protocol-folder}with the local folder that contains your protocol code, and{auth-folder}with the local folder that contains your authentication information.
NOTE
To redeploy the same version of your code, you must include the
-fflag in your deployment command. This flag forces the code to overwrite the file. The following are example protocol deployment command examples:
ts-sdk put protocol private-xyz hello-world v1.0.0 ./protocol -f -c auth.jsonts-sdk put task-script private-xyz hello-world v1.0.0 ./task-script -f -c auth.jsonFor more details about the available arguments, run the following command:
ts-sdk put --help
Create a Pipeline That Uses the Deployed Protocol
To use your new protocol on the TDP, create a new pipeline that uses the protocol that you deployed. Then, upload a file that matches the pipeline’s trigger conditions.
Updated 7 months ago