Create IDSs Programmatically
You can create your own Intermediate Data Schemas (IDSs) programmatically, and in a way that keeps data structures consistent across your organization's schemas, by using the Tetra Data Core Schemas Python library (package name: ts-ids-core).
Tetra Data Core Schemas are built on top of Pydantic, a Python package designed for data quality and verification. Accompanied with a growing set of domain-specific components (ts-ids-components), the package provides built-in rules that make sure the IDSs you create align with TetraScience data model best practices and ultimately allow you to create production-ready Self-Service Tetra Data Pipelines (SSPs) faster.
The ts-ids-core and ts-ids-components packages are privately hosted Python packages owned by TetraScience and published under the CC BY-NC-ND 4.0 license. To access the packages, contact your customer success manager (CSM).
Use Cases
You can use Tetra Data Core Schemas to do any of the following:
-
Create a Custom IDS: Define your own programmatic IDS by inheriting from one of the top-level IDS classes in the
ts_ids_core.schema.ids_schemamodule:IdsSchema: Contains the required metadata fields for each IDS (@idsNamespace,@idsType,@idsVersion,$id, and$schema) and provides the minimum required validation to make an IDS compliant with the Tetra Data Platform (TDP).TetraDataSchema: Inherits fromIdsSchema, providing all the functionality of theIdsSchemaschema class, while also enforcing internal TetraScience modeling conventions.
-
Use Domain-Specific Components:
ts-ids-componentsis home to domain-specific common components for use in programmatic IDSs. These components can be used in any IDS as a way to build upon existing data models. When multiple IDSs use the same common components, accessing data becomes more consistent by enabling reuse of search queries and application code. -
Modify an Existing IDS: Migrate from an existing JSON Schema to a programmatic IDS definition by using
ts-ids-coreand the provided code generation tool. This tool is exposed as the CLI scriptimport-schema.
Architecture
The following diagram shows an example workflow of how Tetra Data Core Schemas work with SSPs:
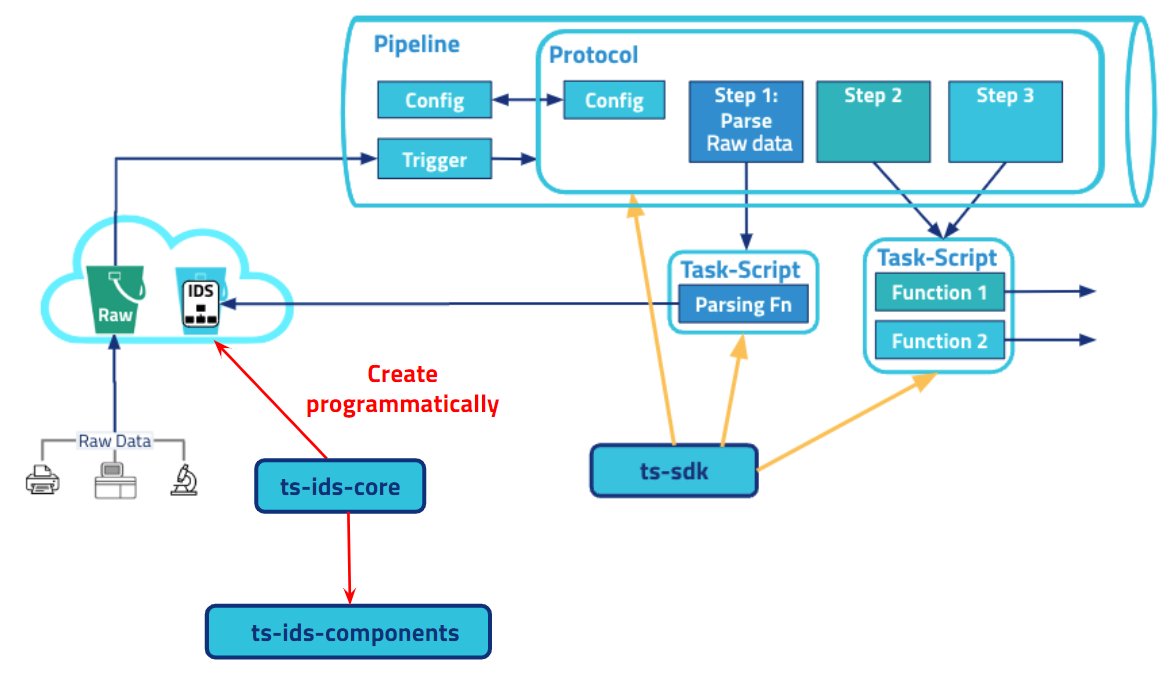
The diagram shows the following workflow:
- An IDS is programmatically created by using
ts-ids-coreandts-ids-components, which is then applied to raw instrument data or report files and used to map vendor-specific information (like the name of a field) to vendor-agnostic information. - Task scripts, which are the building blocks of protocols, contain the code for the business logic needed to process data. These task scripts are written in Python.
- Protocols are written in a YAML file (
protocol.yml), which specifies configuration elements and outlines the execution order of task script functions. - Task scripts and protocols are deployed to the TDP by using the TetraScience Software Development Kit (SDK) 2.0.
- Once these artifacts are on the TDP, you can create an SSP to automatically process ingested files by doing the following:
- Specifying trigger conditions
- Providing configuration values
- Leveraging the protocol that you’ve created by using either commonly available task scripts or ones you’ve created yourself
Installation
Prerequisites
- Familiarity with Git, Python, Pydantic, and SSPs
Request the Packages from TetraScience
TetraScience provides access to an authenticated private package feed (ts-pypi-external) to integrate into your own internal package source. For access, contact your CSM.
Documentation
For detailed instructions on how to use the Tetra Data Core Schemas Python library, run the following command on the ts-ids-core package: ts-ids docs
Updated 29 days ago