Self-Service Tetra Data Pipelines
TetraScience provides many pre-built pipelines that can help you create queryable, harmonized Tetra Data, and then enrich and push that data to downstream systems. To extend the capabilities of these pipelines and the Tetra Data Platform (TDP), you can also create your own custom self-service Tetra Data pipelines (SSPs).
NOTEFor simple custom pipeline setups that aren't complex (Python scripts with less than 12,000 characters), it's recommended that you configure your own protocol by using a custom Python script and the
python-execprotocol. You can also try out our new Workflow Creation Assistant to quickly design, develop, test, and deploy your own lab data automation pipelines for selected ELNs using an AI-powered workflow.
For example, you can use SSPs to do any of the following:
- Create new parsers for scientific instrument data.
- Add labels to your data to make it findable, and then discover use patterns.
- Enrich your data by combining it with other third-party data on the TDP.
- Automate the manual work of data preprocessing for analytics software or other proprietary processes.
- Send processed data to other applications, such as machine learning tools, electronic lab notebooks (ELNs), or laboratory information management systems (LIMS).
For more information about example SSP use cases, see Example Use Cases for SSPs. For best practices, see Data Engineering and Tooling and Automation in the TetraConnect Hub. For access, see Access the TetraConnect Hub.
SSP Architecture
The following diagram shows an example SSP workflow:
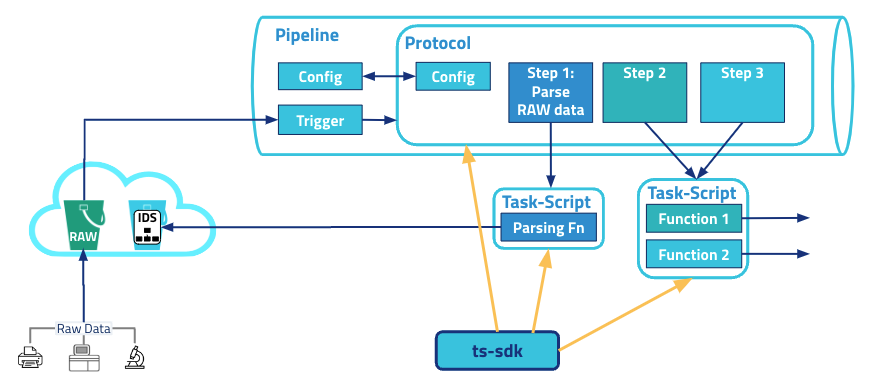
SSP architecture diagram
The diagram shows the following workflow:
- Task scripts, which are the building blocks of protocols, contain the code for the business logic needed to process data. These task scripts are written in Python.
- Protocols are written in a YAML file (
protocol.yml), which specifies configuration elements and outlines the execution order of task script functions. - Task scripts and protocols are deployed to the TDP by using the TetraScience Software Development Kit (SDK) 2.0.
- Once these artifacts are on the TDP, you can create an SSP by doing the following:
- Specifying trigger conditions
- Providing configuration values
- Leveraging the protocol that you’ve created by using either commonly available task scripts, or ones you’ve created yourself
IMPORTANTAll files uploaded by SSPs must be less than 50 MB.
CI/CD Workflows for SSPs
To help manage your SSPs, you can build your own continuous integration and continuous delivery (CI/CD) process by using whatever source code version control system you want.
The following diagram shows an example GitHub-based CI/CD workflow for managing SSPs:
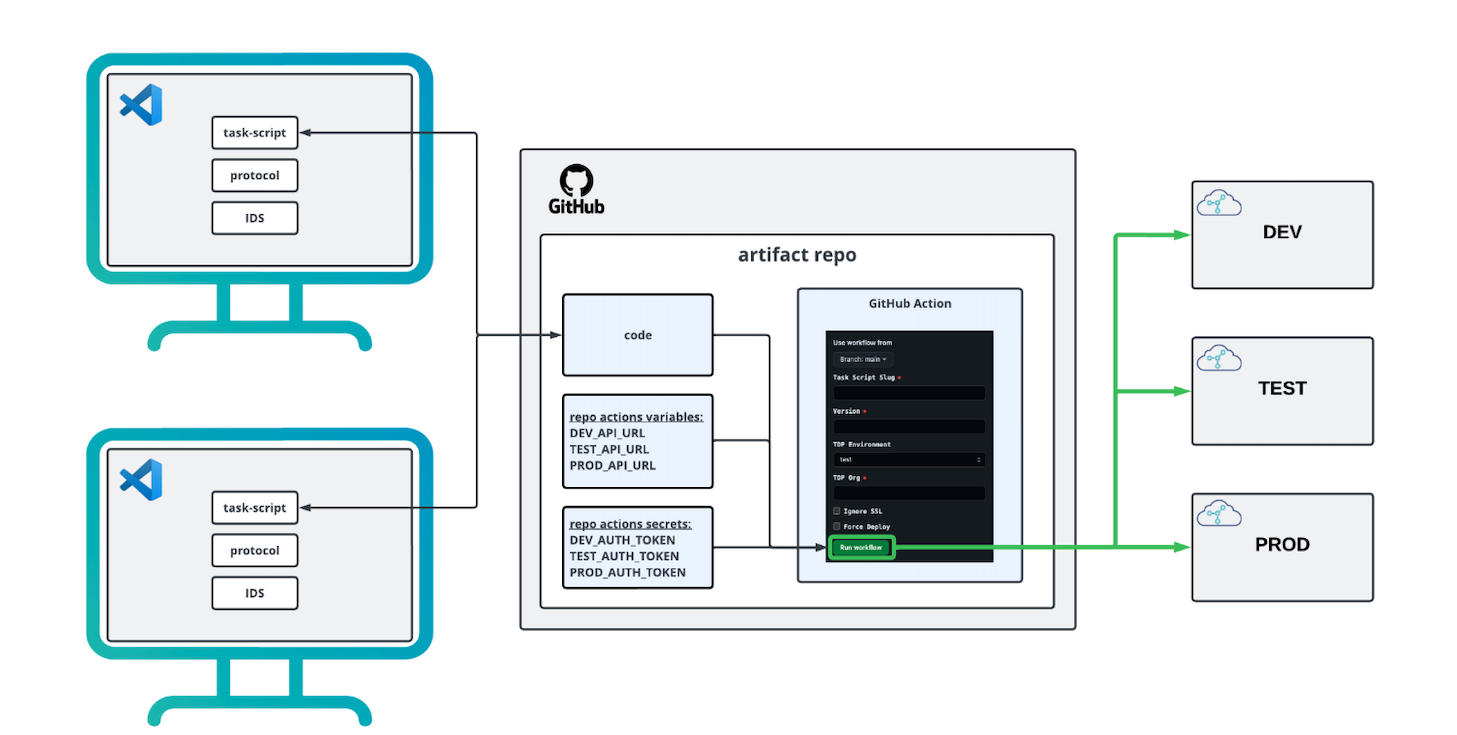
Create SSPs
To learn more about how to create your own SSPs, see the following:
- Example Use Cases for SSPs
- SSP Setup and Prerequisites
- Hello, World! SSP Example
- Task Script Files
- Protocol YAML Files
- Create and Test Custom Task Scripts
- Context API
Documentation Feedback
Do you have questions about our documentation or suggestions for how we can improve it? Start a discussion in TetraConnect Hub. For access, see Access the TetraConnect Hub.
NOTEFeedback isn't part of the official TetraScience product documentation. TetraScience doesn't warrant or make any guarantees about the feedback provided, including its accuracy, relevance, or reliability. All feedback is subject to the terms set forth in the TetraConnect Hub Community Guidelines.
Updated 2 months ago