Disaster Recovery
Disaster recovery sites (DR sites) provide the infrastructure required for resuming operations on a secondary site following a disaster that has greatly impaired the main production site. To preserve data and restore service following a catastrophic event that renders a TDP production site inoperable, TetraScience creates DR sites in a second AWS Region in a different geography (DR Region) for each Tetra-hosted multi-tenant deployment. Data within each TDP environment, including user files and platform state, is replicated to the DR Region.
For deployments in the European Union (EU), data is not replicated in AWS Regions outside of the EU. For US deployments, data is not replicated in Regions outside of the United States.
IMPORTANTThe following legacy deployment types have different disaster recovery availability:
- Legacy customer-hosted TDP deployments require customers to create and manage their own DR sites for disaster recovery services to be available.
- Legacy single-tenant Tetra hosted deployments can request disaster recovery services for an additional cost, but DR is not available by default.
For more information, contact your customer account leader and see Disaster Recovery for Customer Hosted Deployments in the TetraConnect Hub. For access, see Access the TetraConnect Hub.
Disaster Recovery Service Objectives
The Recovery Time Objective (RTO) for TDP deployments with DR sites configured is 12 hours. This is the maximum likely time period in which the production environment is unavailable because of a disaster.
The Recovery Point Objective (RPO) for TDP deployments with DR sites configured varies between 15 minutes and 12 hours, depending on the data type. This is the maximum likely time period in which your data may be lost because of a disaster.
Standard RPO Time Frame for TDP Data Types
The following table shows the standard RPO time frame for each TDP data type:
| Data Type | Underlying AWS Service | RPO Values |
|---|---|---|
| Raw and processed files in the TDP | Amazon Simple Storage Service (Amazon S3) | 15 minutes |
| Configurations such as pipeline settings, user permissions, and event history | Amazon Relational Database Service (Amazon RDS) and Amazon Elastic Container Service (Amazon ECS) | 12 hours |
| File indexing and search functionality | Amazon OpenSearch Service | 6 hours |
Architecture for TDP Disaster Recovery
During disaster recovery, a TDP environment is restored from a geo-replicated, automated backup. File stores are available in read-only configuration in the secondary DR site. Connectivity settings from the primary production site are mirrored in the DR site.
The following diagram shows an example TDP disaster recovery configuration:
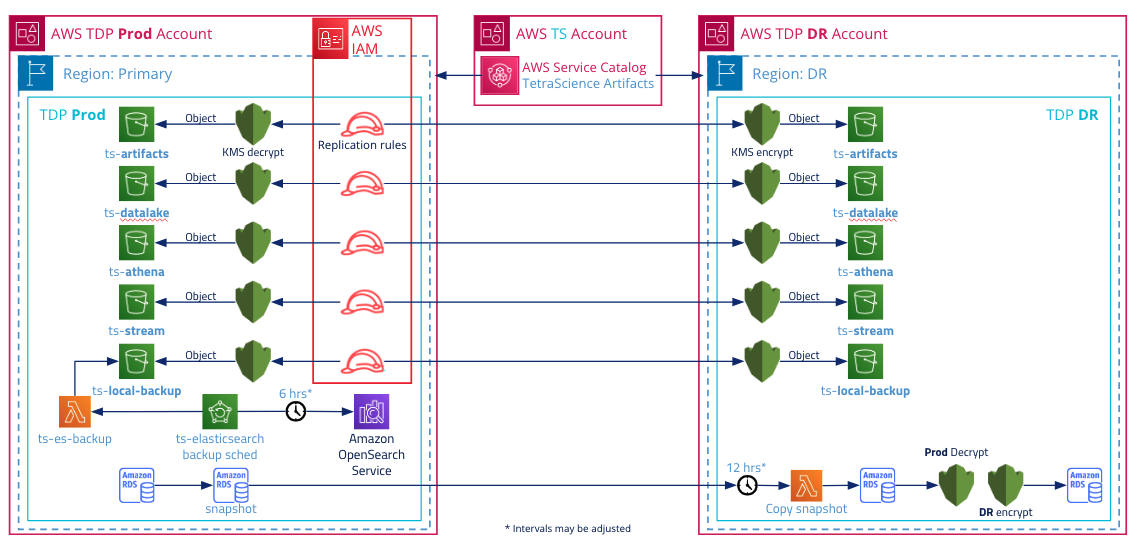
For more information about data backups, see TDP Availability and Resilience.
Recovery Actions
The TDP installation process is fully automated by using Infrastructure as Code (IaC). The recovery procedure, performed in the DR Region, is similar to a new TDP installation for all stateless components. Once the recovery environment has been created, the recovery procedure uses the replicated data that is available in the DR Region.
| Recovery Action | Initiated By | Description |
|---|---|---|
| Stop data replication from PROD environment to DR site | TetraScience | Make sure that data is no longer replicated from the PROD environment to the DR site by deactivating data replication from the source Amazon S3 bucket. |
| Perform a new deployment of the TDP based on the data and configurations in the DR site | TetraScience | The TDP is deployed in a newly provisioned environment and linked with the persisted data and configurations from the DR site. |
| Reinstall any Tetra Hubs and Data Hubs along with their Agents and Connectors | Customer | Any existing, on-premises Tetra Hubs and Data Hubs along with their Agents and Connectors must be reinstalled by the customer |
Disaster Recovery Testing
A disaster recovery test is performed for each major and minor TDP release.
The disaster recovery test consists of recovering a TDP environment in the DR Region from the replicated data, and then performing data validation with the data in the Tetra hosted production environment.
NOTEAll TDP environments continue to run normally and are not affected by the disaster recovery test in any way.
Documentation Feedback
Do you have questions about our documentation or suggestions for how we can improve it? Start a discussion in TetraConnect Hub. For access, see Access the TetraConnect Hub.
NOTEFeedback isn't part of the official TetraScience product documentation. TetraScience doesn't warrant or make any guarantees about the feedback provided, including its accuracy, relevance, or reliability. All feedback is subject to the terms set forth in the TetraConnect Hub Community Guidelines.
Updated 2 months ago