Tetra Data & AI Workspace
Tetra Data & AI Workspace helps you colocate your replatformed and engineered scientific data with analysis applications, and then correlate analysis results through Tetra Data Apps—all while maintaining a source of record in the Tetra OS.
By using the Tetra Data & AI Workspace, you can do any of the following:
- Visualize and analyze scientific data to generate analysis results
- Verify the data as part of the automated scientific workflow
- Easily associate primary data with analysis output
- Annotate scientific data to support AI/ML model training
- Generate predictions and performance AI/ML model inference and continuous learning
Access the Data & AI Workspace Page
To access the Data & AI Workspace page, do the following:
- Sign in to the Tetra Data Platform (TDP).
- In the left navigation menu, choose Data & AI Workspace. The Data & AI Workspace page appears.
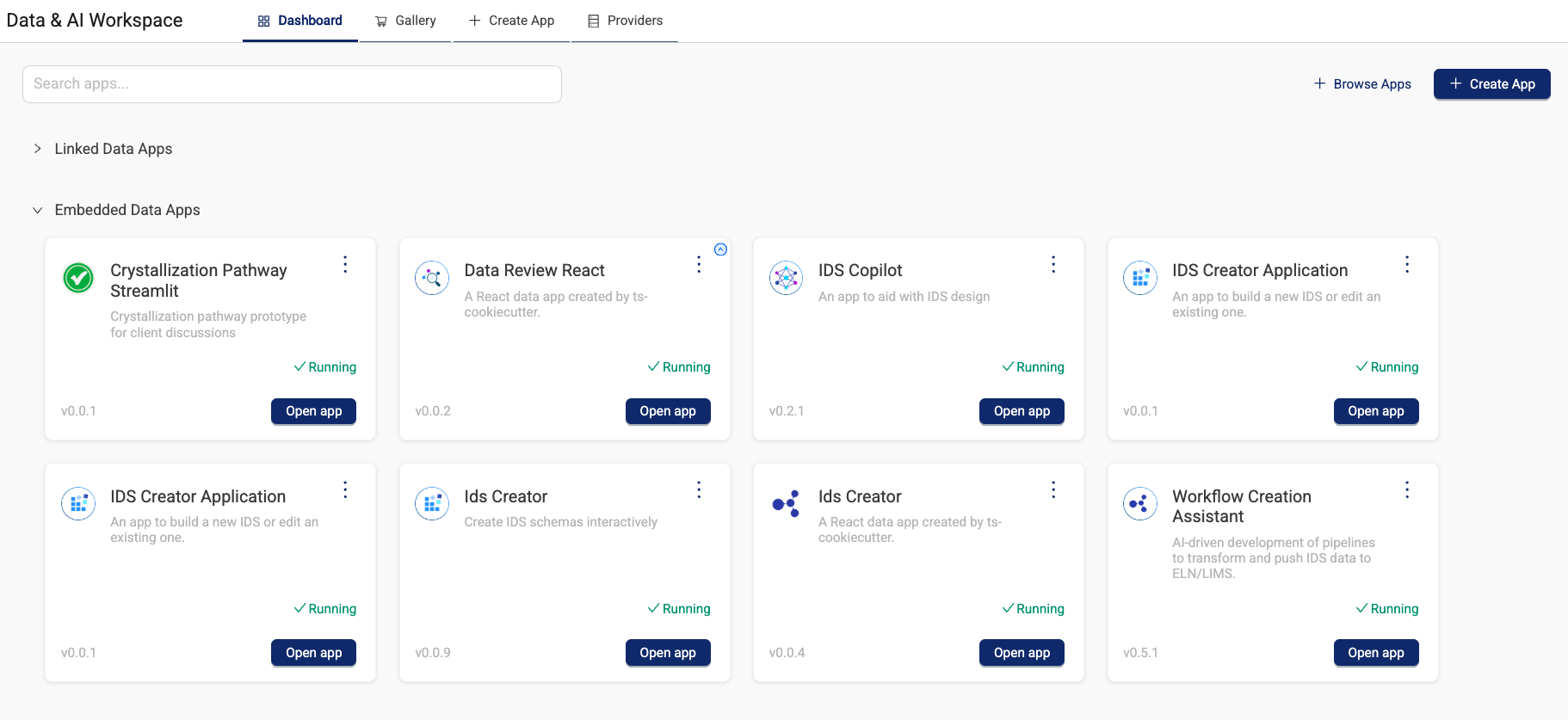
Data & AI Workspace Tabs
The Data & AI Workspace page has four tabs:
- Dashboard shows all running apps in your organization, including their Running or Starting status.
- Gallery shows what apps are available and provides a search bar as well as the option to filter apps by namespace.
- + Create App provides a step-by-step guide to build and publish your own self-service Data App. For more information about creating your own apps, see Self-Service Data Apps in the TetraConnect Hub.
- Providers shows your organization's external data sources that have been set up to connect to Data Apps.
Start a New Data & AI Workspace Session
To start a new Data & AI Workspace session for a Tetra Data App, do the following:
- Open the Data & AI Workspace page.
- Select the app that you want to use from the Dashboard tab. The configured Data App appears. Linked Data Apps appear in a separate tab in your browser, outside of the TDP. Embedded Data Apps appear within your workspace session within the TDP.
Working With Tetra Data Apps
There are two main types of Tetra Data Apps:
- Embedded Data Apps run in the cloud and are configured for SaaS application streaming back to the TDP. TetraScience provides many pre-built Embedded Data Apps. You can also create your own custom self-service Data Apps.
- Linked Data Apps run as external SaaS applications outside of the Tetra Data Platform (TDP).
Your organization's analysis software determines the Data App type that you use. To configure and manage Tetra Data Apps for an organization, see Tetra Data Apps.
NOTEThe Tetra Data & AI Workspace and Tetra Data Apps don't use artificial intelligence (AI) or machine learning (ML) natively. Instead, both features support AI/ML model training in third-party applications that run outside of the TDP. For Embedded Data Apps based on Streamlit, TetraScience has the ability to create Python code and make it available to customers through the TDP. In the future, code may be created to help integrate customers' Tetra Data with AI/ML models on third-party applications. However, customers can't modify this code, and any code developed in this way must first go through our ISO 9001-certified Quality Management System and software development lifecycle.
View Tetra Data App Documentation
Release notes and user guides for Embedded Tetra Data Apps are available on the Details page for each app in the Tetra Data & AI Workspace. Documentation for apps that appear as optional UI elements within other areas of the TDP is also available on developers.tetrascience.com (for example, the Workflow Creation Assistant and Visual Pipeline Builder, which can appear in the Pipelines menu option in the TDP user interface).
To access an app's documentation, do one of the following, based on if the app is activated in your organization or not.
View Documentation for Activated Apps
To view documentation for activated apps that appear on your organization's Dashboard tab, do the following:
- Open the Data & AI Workspace page.
- On the Dashboard tab, select the app's three-dot menu icon. Then, select Details.
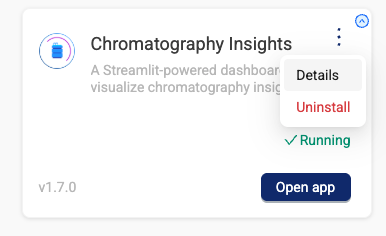
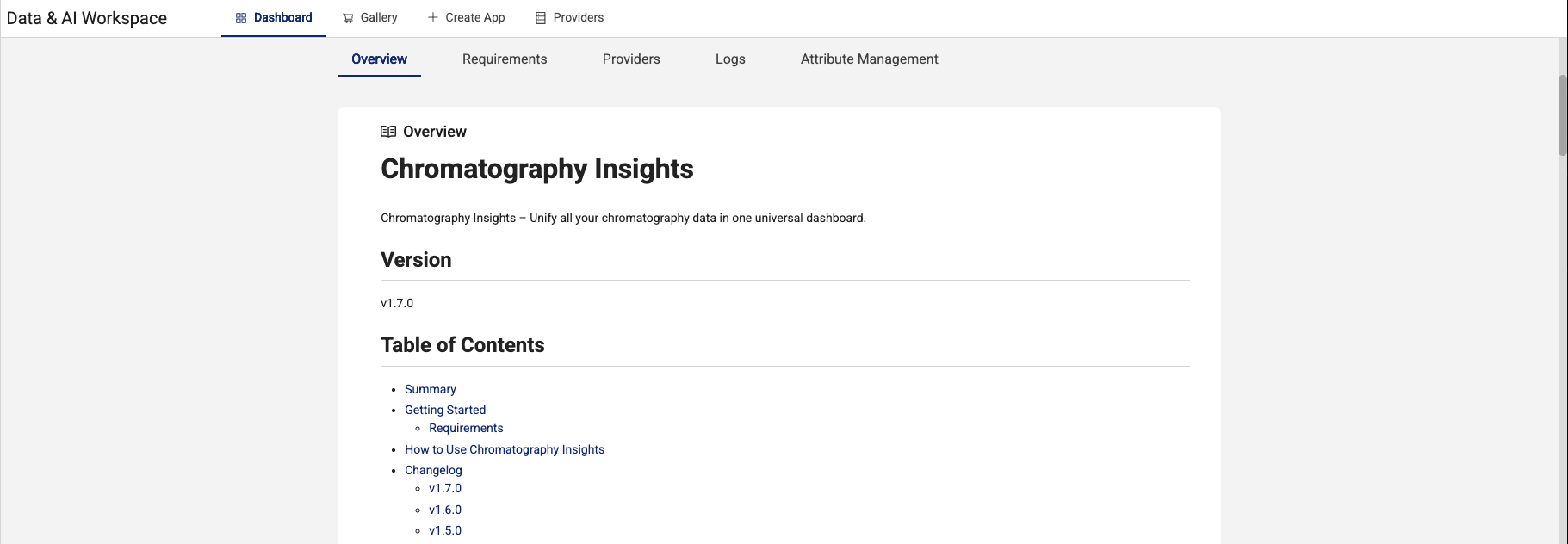
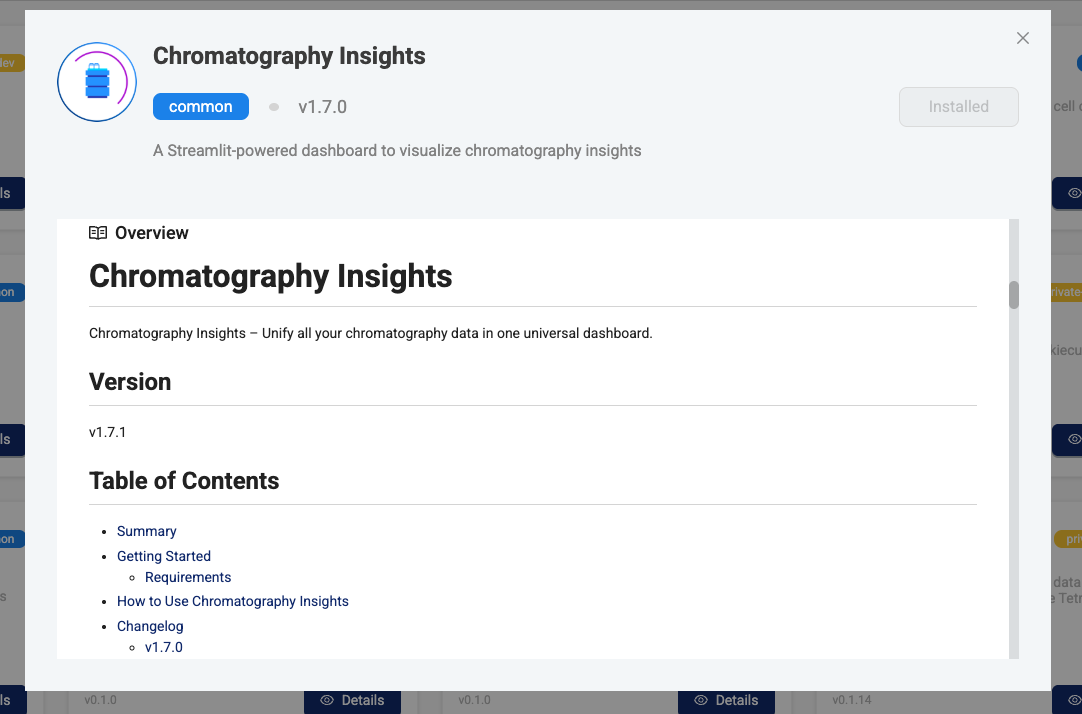
- Review the Overview tab. It displays the documentation for the app, including the user guide and change log for each app version.
View Documentation for Non-Activated Apps
To view documentation for apps that aren't activated, do the following:
- Open the Data & AI Workspace page.
- Select the Gallery tab. Then, select the Details button on the app's tile.
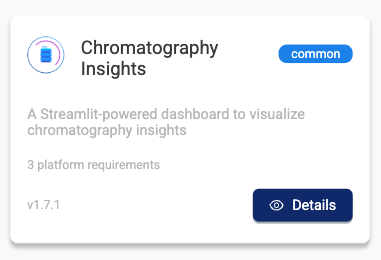
- Review the Overview section. It displays the documentation for the app, including the user guide and change log for each app version.
Documentation Feedback
Do you have questions about our documentation or suggestions for how we can improve it? Start a discussion in TetraConnect Hub. For access, see Access the TetraConnect Hub.
NOTEFeedback isn't part of the official TetraScience product documentation. TetraScience doesn't warrant or make any guarantees about the feedback provided, including its accuracy, relevance, or reliability. All feedback is subject to the terms set forth in the TetraConnect Hub Community Guidelines.
Updated 2 months ago