TDP v4.3.0 Release Notes
Release date: 28 May 2025
TetraScience has released its next version of the Tetra Data Platform (TDP), version 4.3.0. This release makes the new Data Lakehouse Architecture generally available. The new, customer-controlled data storage and management architecture provides customers 50% to 300% faster SQL query performance and an AI/ML-ready data storage format that operates seamlessly across all major data and cloud platform vendors.
This release also introduces lower latency pipelines, makes Snowflake data sharing generally available, adds AWS WAF rule support, and includes other functional and performance improvements.
Here are the details for what’s new in TDP v4.3.0.
New Functionality
Last updated: 19 Feburary 2026
New functionalities are features that weren’t previously available in the TDP.
GxP Impact AssessmentAll new TDP functionalities go through a GxP impact assessment to determine validation needs for GxP installations.
New Functionality items marked with an asterisk (*****) address usability, supportability, or infrastructure issues, and do not affect Intended Use for validation purposes, per this assessment.
Enhancements and Bug Fixes do not generally affect Intended Use for validation purposes.
Items marked as either beta release or early adopter program (EAP) are not validated for GxP by TetraScience. However, customers can use these prerelease features and components in production if they perform their own validation.
Data Access and Management New Functionality
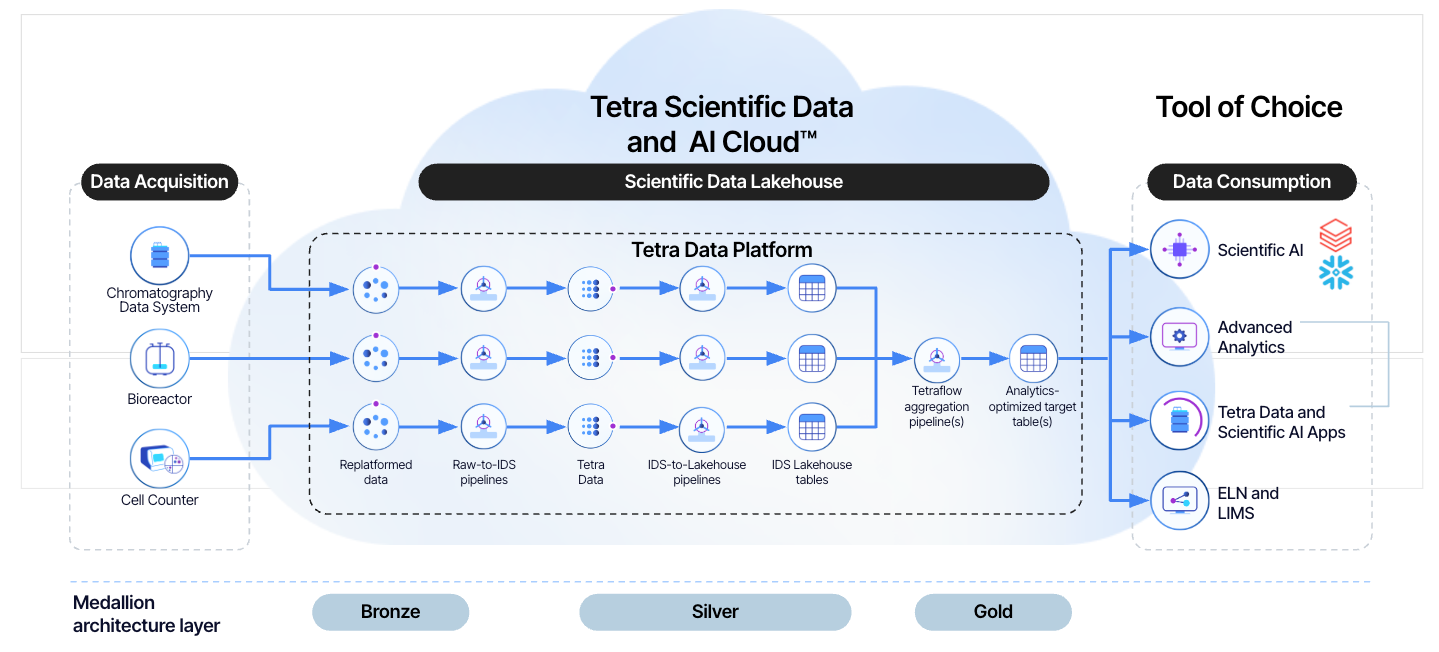
Data Lakehouse Architecture is Now Generally Available
Previously available as part of an early adopter program (EAP), the Data Lakehouse Architecture is now generally available to all customers. The new data storage and management architecture provides 50% to 300% faster SQL query performance and an AI/ML-ready data storage format that operates seamlessly across all major data and cloud platform vendors.
Key Benefits
- Share data directly with any Databricks and Snowflake account
- Run SQL queries faster and more efficiently
- Create AI/ML-ready datasets while reducing data preparation time
- Reduce data storage costs
- Configure Tetraflow pipelines to read multiple data sources and run at specific times
What’s New in TDP v4.3.0
- Customers can convert their data to Lakehouse tables themselves: Customers can now convert their own data into Lakehouse tables by using the
ids-to-lakehouseprotocol in Tetra Data Pipelines. Previously, converting data into Lakehouse tables needed to be done in coordination with customer engineering support. - Faster, more predictable, and lower-cost data latency at scale: With lower compute cost, customers can now consistently convert their Intermediate Data Schema (IDS) data into nested IDS Lakehouse tables in about 30 minutes. Previously, converting data could take up to 45 minutes. More infrastructure improvements that will continue to reduce data latency are planned for future releases. (Updated on 4 June 2025))
- Improved schema structure: Lakehouse tables are now written to nested, IDS-specific schemas. The new nested schema structure makes it so that customers no longer have to navigate through hundreds of potential tables under one schema.
- Snowflake query performance parity: Lakehouse tables are now written to be interoperable with the Iceberg format. This ensures that Snowflake data sharing provides the same query performance as running queries against Lakehouse tables in the TDP.
How It Works
A data lakehouse is an open data management architecture that combines the benefits of both data lakes (cost-efficiency and scale) and data warehouses (management and transactions) to enable analytics and AI/ML on all data. It is a highly scalable and performant data storage architecture that breaks data silos and allows seamless, secure data access to authorized users.
TetraScience is adopting the ubiquitous Delta table format to transform data into refined, cleaned, and harmonized data, while empowering customers to create curated datasets as needed. This process is referred to as the “Medallion” architecture, which is outlined in the Databricks documentation.
For more information, see the Data Lakehouse Architecture documentation.
IMPORTANTWhen upgrading to TDP v4.3.0, keep in mind the following:
- Customers taking part in the EAP version of the Data Lakehouse will need to reprocess their existing Lakehouse data to use the new GA version of the Lakehouse tables. To backfill historical data into the updated Lakehouse tables, customers should create a Bulk Pipeline Process Job that uses an
ids-to-lakehousepipeline and is scoped in the Date Range field by the appropriate IDSs and historical time ranges.- When configuring
ids-to-lakehousepipelines, customers should always select the Run on Deleted Files checkbox. The Run on Deleted Files checkbox should not be selected for any other protocols besides theids-to-lakehouseprotocol.- For single tenant, customer-hosted deployments to upgrade to TDP v4.3.0 and higher and use the Data Lakehouse Architecture, the TetraScience Databricks integration is required.
For more information, contact your customer success manager (CSM).
Snowflake Data Sharing is Now Generally Available*
Previously available as part of an early adopter program (EAP), the ability to access Tetra Data through Snowflake is now generally available to all customers.
To access Tetra Data through Snowflake, data sharing must be set up in coordination with TetraScience. A Business Critical Edition Snowflake account is also required in the same AWS Region as your TDP deployment.
For more information, see Use Snowflake to Access Tetra Data.
Data Harmonization and Engineering New Functionality
Last updated: 19 Feburary 2026
Unpublish Private Namespace Artifacts
(Added on 19 Feburary 2026)
Customers can now unpublish their own self-service artifacts in the private namespace by running one of the following TetraScience CLI commands:
For artifacts that have a manifest.json file
ts-cli unpublish {artifact-folder} -c {auth-folder}/auth.jsonFor artifacts without a manifest.json file
ts-cli unpublish --type {artifact-type} --namespace private-{TDP ORG} --slug {artifact-slug} --version {vx.x.x} {artifact-folder} -c {auth-folder}/auth.jsonUnpublished artifacts will no longer appear in the Artifacts menu options in the TDP user interface.
For more information, see Unpublish Self-Service Artifacts in the Hello, World! SSP Example.
TDP System Administration New Functionality
Optional Support for AWS WAF in Customer-Hosted Environments*
Customers hosting the TDP in their own environment now have the option to add an AWS WAF (Web Application Firewall) component in front of the public-facing Application Load Balancer (ALB). This is an optional security enhancement and requires specific rule group exceptions to allow seamless operation of the platform’s APIs.
For more information, see AWS WAF Rule Exceptions.
Enhancements
Enhancements are modifications to existing functionality that improve performance or usability, but don't alter the function or intended use of the system.
Data Integrations Enhancements
Configuration Files for Tetra File-Log Agents Are Now More Comprehensive
Tetra File-Log Agent configuration files downloaded from the TDP’s Agents page now contain all of an Agent’s configuration details. These new details include proxy information, Advanced Settings, S3 Direct Upload settings, command queue settings, path configurations, and more. Configuration files for other Agent types that support the Download Configuration feature already include this information.
For more information, see Download Agent Configuration Settings.
SQL Tables Now Include Agent Details
A new {orgslug}**tss**system.agents SQL table now provides the following information about Tetra Agents in Amazon Athena :
name(string)id(string)is_enabled(boolean)type(string)org_slug(string)
This update makes these Agent details available to the new Health Monitoring App.
Agent Command Queues Are Now Enabled in the TDP by Default
To make it easier to communicate with on-premises Tetra Agents programmatically, command queues for all new Agents are now enabled in the TDP by default.
To start using the feature, customers now only need to enable the Receive Commands setting in the local Agent Management Console when installing an Agent. Customers can still turn off an Agent’s command queue at any time.
For more information, see Command Service.
Data Harmonization and Engineering Enhancements
Lower Latency Pipelines
To help support latency-sensitive lab data automation use cases, customers can now select a new Instant Start pipeline execution mode when configuring Python-based Tetra Data Pipelines.
This new compute type offers ~1-second startup time after the initial deployment, regardless of how recently the pipeline was run. Customers can also select from a range of instance sizes in this new compute class to handle data at the scale their use case requires. There’s little to no additional cost impact.
For more information, see Memory and Compute Settings.
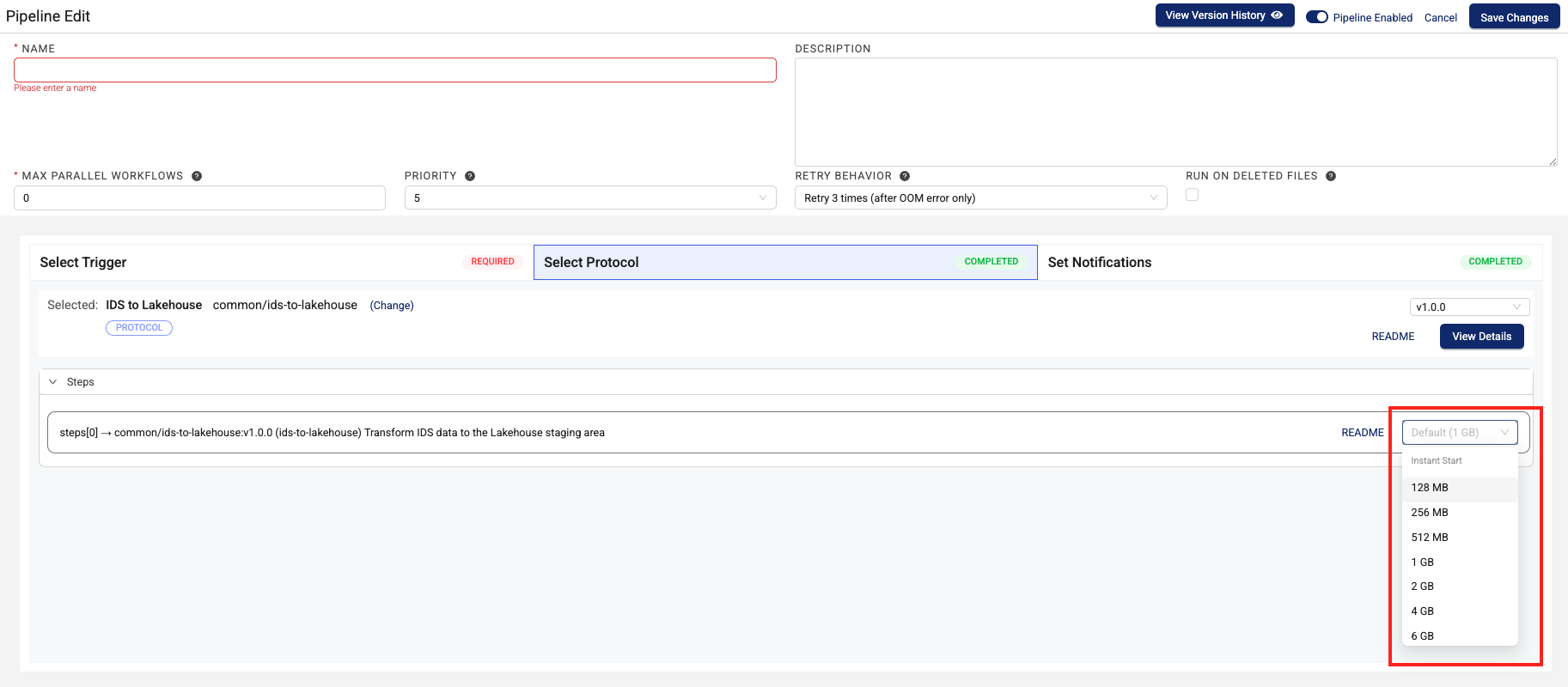
Instant Start pipeline memory setting
🚧 IMPORTANT
Task scripts for the associated protocol steps must be on the latest compatible version to use the new
Instant Startcompute type. If a targetedcommonorclientprotocol doesn't have the new compute options, customers should contact their customer success manager (CSM). For task scripts in theprivatenamespace, customers can publish and deploy a new version of the task scripts for their Self-service pipeline (SSP) protocol. (Updated on 4 June 2025))
Increased Bulk Label Operations Limit
Customers can now run up to 200 operations when editing labels in bulk. Previously, only five operations were allowed for each bulk label change job.
For more information, see Edit Labels in Bulk.
Data Access and Management Enhancements
New optimizerResult Field for /searchEql API Endpoint Responses
optimizerResult Field for /searchEql API Endpoint ResponsesA new, optional optimizerResult field appears as part of the /searchEql API endpoint response. The field displays an optimized query and index string that customers can either choose to use or not. Customers' original queries are not modified. The new field provides query optimization suggestions only.
For more information, see the Search files via Elasticsearch Query Language API documentation.
Data App Configurations Now Persist When Upgrading to New App Versions
Any changes made in a Tetra Data App configuration now persist when customers upgrade to a new app version. This enhancement is enabled by the addition of Amazon Elastic File System (Amazon EFS) storage. Amazon EFS offers persistent storage for configurations, so any changes made are not lost when upgrading Data App versions.
Amazon EFS is not enabled by default. Only data apps that explicitly request storage support now have Amazon EFS storage.
For more information, see AWS Services.
TDP System Administration Enhancements
Last updated: 5 June 2025 (backported thenew description field for service users enhancement to the TDP v4.2.1 Release Notes, when it was introduced)
Automatic Notifications for Service User Tokens
System administrators now have the option to create automated email notifications to inform specific users when one of their organization’s Service User JSON Web Tokens (JWTs) is about to expire.
For more information, see Add a Service User and Edit a Service User.
Beta Release and EAP Feature Enhancements
New Infrastructure to Support Self-Service Connectors EAP
With the upcoming release of the TetraScience Connectors SDKs planned for June 2025, customers will be able to create their own self-service Tetra Connectors as part of an early adopter program (EAP).
TDP v4.3.0 introduces the required infrastructure to support self-service Connectors once the new Connector SDKs are available.
Improved Accuracy for Data Retention Policies
Files deleted by Data Retention Policies are now deleted based on when they became available for search in the TDP (uploaded_at), rather than when they were initially uploaded (inserted_at).
This update resolves an issue where some files were not deleted as expected because of the delay between when files are uploaded and when they’re indexed for search.
Infrastructure Updates
The following is a summary of the TDP infrastructure changes made in this release. For more information about specific resources, contact your CSM or account manager.
New Resources
- AWS services added: 0
- AWS Identity and Access Management (IAM) roles added: 12
- IAM policies added: 12 (inline policies within the roles)
- AWS managed policies added: 1 (AWSLambdaBasicExecutionRole)
Removed Resources
- IAM roles removed: 3
- IAM policies removed: 3 (inline policies within removed roles)
- AWS managed policies removed: 0
New VPC Endpoints for Customer-Hosted Deployments
For customer-hosted environments, if the private subnets where the TDP is deployed are restricted and don't have outbound access to the internet, then the VPC now needs the following AWS Interface VPC endpoints enabled:
com.amazonaws.<REGION>.servicecatalog: enables AWS Service Catalog, which is used to create and manage catalogs of IT services that are approved for AWScom.amazonaws.<REGION>.states: enables AWS Step Functions workflows (State machines), which are used to automate processes and orchestrate microservicescom.amazonaws.<REGION>.tagging: enables tagging for AWS resources, which hold metadata about each resource
These new endpoints must be enabled along with the other required VPC endpoints.
For more information, see VPC Endpoints.
Bug Fixes
The following bugs are now fixed.
Data Access and Management Bug Fixes
- Files with fields that end with a backslash (
\) escape character can now be uploaded to the Data Lakehouse with the newids-to-lakehouseingestion process. (Updated on 4 June 2025))
Data Harmonization and Engineering Bug Fixes
- On the Pipeline Edit page, in the Retry Behavior field, the
Always retry 3 times (default)value no longer appears as a null value.
TDP System Administration Bug Fixes
- Error messages that appear when an Admin tries to generate SQL credentials for a TDP user that doesn’t have SQL Search permissions now indicate what’s causing the error.
Deprecated Features
There are no new deprecated features in this release.
For more information about TDP deprecations, see Tetra Product Deprecation Notices.
Known and Possible Issues
Last updated: 3 March 2026
The following are known and possible issues for TDP v4.3.0.
Data Integrations Known Issues
Last updated: 16 June 2025
-
When configuring Tetra File-Log Agent paths in the TDP user interface, there are three known issues:
- The End Date field can’t be the same value as the Start Date field. The UI indicates that the End Date can be “on or after the Start Date”. (Added on 11 June 2025)
- After a filter action is cleared, the Labels field's Value dropdown displays an incorrect list of customers' available labels for new scan paths. As a workaround, customers should cancel the scan path if this issue occurs. Then, create a new scan path with the correct label values selected, without clearing any filter fields. (Added on 16 June 2025)
- Path configuration options incorrectly appear to be enabled for Agents that have their queues disabled. Any configuration changes made through the TDP UI to an Agent that has its queue disabled won't be applied to the Agent. (Added on 16 June 2025)
A fix for these issues is in development and testing and is scheduled for a future release.
-
For new Tetra Agents set up through a Tetra Data Hub and a Generic Data Connector (GDC), Agent command queues aren’t enabled by default. However, the TDP UI still displays the command queue as enabled when it’s deactivated. As a workaround, customers can manually sync the Tetra Data Hub with the TDP. A fix for this issue is in development and testing and is scheduled for a future release. (Added on 9 June 2025)
-
Customers can't edit file paths to the Tetra File-Log Agent through the TDP user interface, and shouldn't add any new paths. Any files ingested through a new path added to the Tetra File-Log Agent through the TDP UI won't have the correct, default
instrument_typelabel. Customers also won't be able to edit these files' attributes through the Add Attributes action on the File Details page. A fix for this issue is in development and testing and is scheduled for the next TDP patch release (TDP v4.3.1).As a workaround to edit or add paths, customers should do either of the following:
-
Update the Agent's Configuration via the API, and make sure the label for instrument type is
instrument_type.-or-
-
(For FLA 4.3.x or higher only) Edit or add file paths through the Agent Management Console. Saved changes are reflected in the TDP. (Added on 6 June 2025)
-
Data Harmonization and Engineering Known Issues
- The legacy
ts-sdk putcommand to publish artifacts for Self-service pipelines (SSPs) returns a successful (0) status code, even if the command fails. As a workaround, customers should switch to using the latest TetraScience Command Line Interface (CLI) and run thets-cli publishcommand to publish artifacts instead. A fix for this issue is in development and testing and is scheduled for a futurets-sdkrelease. (Added on 3 June 2025) - IDS files larger than 2 GB are not indexed for search.
- The Chromeleon IDS (thermofisher_chromeleon) v6 Lakehouse tables aren't accessible through Snowflake Data Sharing. There are more subcolumns in the table’s
methodcolumn than Snowflake allows, so Snowflake doesn’t index the table. A fix for this issue is in development and testing and is scheduled for a future release. - SQL queries run against the Lakehouse tables generated from Cytiva AKTA IDS (
akta) SQL tables aren’t backwards compatible with the legacy Amazon Athena SQL table queries. WhenaktaIDS SQL tables are converted into Lakehouse tables, the following table and column names are updated:- The source
akta_v_runAmazon Athena SQL table is replaced with anakta_v_rootLakehouse table. - The
akta_v_run.timecolumn in the source Amazon Athena SQL tables is renamed toakta_v_root.run_time. - The
akta_v_run.notecolumn in the source Amazon Athena SQL tables is renamed toakta_v_root.run_note.
These updated table and column names must be added to any queries run against the newaktaIDS Lakehouse tables. A fix for this issue is in development and testing and is scheduled for a future release.
- The source
- Empty values in Amazon Athena SQL tables display as
NULLvalues in Lakehouse tables. - File statuses on the File Processing page can sometimes display differently than the statuses shown for the same files on the Pipelines page in the Bulk Processing Job Details dialog. For example, a file with an
Awaiting Processingstatus in the Bulk Processing Job Details dialog can also show aProcessingstatus on the File Processing page. This discrepancy occurs because each file can have different statuses for different backend services, which can then be surfaced in the TDP at different levels of granularity. A fix for this issue is in development and testing. - Logs don’t appear for pipeline workflows that are configured with retry settings until the workflows complete.
- Files with more than 20 associated documents (high-lineage files) do not have their lineage indexed by default. To identify and re-lineage-index any high-lineage files, customers must contact their CSM to run a separate reconciliation job that overrides the default lineage indexing limit.
- OpenSearch index mapping conflicts can occur when a client or private namespace creates a backwards-incompatible data type change. For example: If
doc.myFieldis a string in the common IDS and an object in the non-common IDS, then it will cause an index mapping conflict, because the common and non-common namespace documents are sharing an index. When these mapping conflicts occur, the files aren’t searchable through the TDP UI or API endpoints. As a workaround, customers can either create distinct, non-overlapping version numbers for their non-common IDSs or update the names of those IDSs. - File reprocessing jobs can sometimes show fewer scanned items than expected when either a health check or out-of-memory (OOM) error occurs, but not indicate any errors in the UI. These errors are still logged in Amazon CloudWatch Logs. A fix for this issue is in development and testing.
- File reprocessing jobs can sometimes incorrectly show that a job finished with failures when the job actually retried those failures and then successfully reprocessed them. A fix for this issue is in development and testing.
- File edit and update operations are not supported on metadata and label names (keys) that include special characters. Metadata, tag, and label values can include special characters, but it’s recommended that customers use the approved special characters only. For more information, see Attributes.
- The File Details page sometimes displays an Unknown status for workflows that are either in a Pending or Running status. Output files that are generated by intermediate files within a task script sometimes show an Unknown status, too.
- (Added on 4 June 2025) Some historical protocols and IDSs are not compatible with the new
ids-to-lakehousedata ingestion mechanism. The following protocols and IDSs are known to be incompatible withids-to-lakehousepipelines:- Protocol:
fcs-raw-to-ids< v1.5.1 (IDS:flow-cytometer< v4.0.0) - Protocol:
thermofisher-quantstudio-raw-to-ids< v5.0.0 (IDS: pcr-thermofisher-quantstudio < v5.0.0) - Protocol:
biotek-gen5-raw-to-idsv1.2.0 (IDS:plate-reader-biotek-gen5v1.0.1) - Protocol:
nanotemper-monolith-raw-to-idsv1.1.0 (IDS:mst-nanotemper-monolithv1.0.0) - Protocol:
ta-instruments-vti-raw-to-idsv2.0.0 (IDS:vapor-sorption-analyzer-tainstruments-vti-sav2.0.0)
- Protocol:
Data Access and Management Known Issues
Last updated: 3 March 2026
- The Download selected files action replaces the following characters with an underscore (
_) if they appear before the file extension in file names:/[/\\:*?<>|.]+/gu;. As a workaround, customers should compare the names of downloaded files against the source file names in the TDP and then rename them if required. A fix for this issue is in development and testing and is scheduled for TDP v4.4.4. (Added on 3 March 2026) - The default Search page that appears after customers sign in to the TDP loads slowly (30+ seconds) in environments with a large set of distinct label values. A fix for this issue is in development and testing and is scheduled for a future release. (Added on 6 January 2026)
- The Data Lakehouse Architecture doesn't support customer-hosted environments that use a proxy to connect to the TDP. A fix for this issue is in development and testing and is scheduled for TDP v4.3.1. (Added on 17 June 2025)
- On the File Details page, related files links don't work when accessed through the Show all X files within this workflow option. As a workaround, customers should select the Show All Related Files option instead. A fix for this issue is in development and testing and is scheduled for a future release. (Added on 16 June 2025)
- The Tetra Data & AI Workspace doesn’t load for users that have only Data User policy permissions. A fix for this issue is in development and testing and is scheduled for a future release.
- When customers upload a new file on the Search page by using the Upload File button, the page doesn’t automatically update to include the new file in the search results. As a workaround, customers should refresh the Search page in their web browser after selecting the Upload File button. A fix for this issue is in development and testing and is scheduled for a future TDP release.
- Values returned as empty strings when running SQL queries on SQL tables can sometimes return
Nullvalues when run on Lakehouse tables. As a workaround, customers taking part in the Data Lakehouse Architecture EAP should update any SQL queries that specifically look for empty strings to instead look for both empty string andNullvalues. - The Tetra FlowJo Data App doesn’t load consistently in all customer environments.
- Query DSL queries run on indices in an OpenSearch cluster can return partial search results if the query puts too much compute load on the system. This behavior occurs because the OpenSearch
search.default_allow_partial_resultsetting is configured astrueby default. To help avoid this issue, customers should use targeted search indexing best practices to reduce query compute loads. A way to improve visibility into when partial search results are returned is currently in development and testing and scheduled for a future TDP release. - Text within the context of a RAW file that contains escape (
\) or other special characters may not always index completely in OpenSearch. A fix for this issue is in development and testing, and is scheduled for an upcoming release. - If a data access rule is configured as [label] exists > OR > [same label] does not exist, then no file with the defined label is accessible to the Access Group. A fix for this issue is in development and testing and scheduled for a future TDP release.
- File events aren’t created for temporary (TMP) files, so they’re not searchable. This behavior can also result in an Unknown state for Workflow and Pipeline views on the File Details page.
- When customers search for labels in the TDP UI’s search bar that include either @ symbols or some unicode character combinations, not all results are always returned.
- The File Details page displays a
404error if a file version doesn't comply with the configured Data Access Rules for the user.
TDP System Administration Known Issues
Last updated: 9 June 2025
-
For customers using proxy servers to access the TDP, single sign-on (SSO) login events don’t display in the System Log. As a workaround, customers can contact TetraScience to retrieve their TDP environment’s login events that don’t appear in the TDP UI. A fix for this issue is in development and testing and is scheduled for the next patch release (TDP v4.3.1). (Added on 9 June 2025)
-
The latest Connector versions incorrectly log the following errors in Amazon CloudWatch Logs:
Error loading organization certificates. Initialization will continue, but untrusted SSL connections will fail.Client is not initialized - certificate array will be empty
These organization certificate errors have no impact and shouldn’t be logged as errors. A fix for this issue is currently in development and testing, and is scheduled for an upcoming release. There is no workaround to prevent Connectors from producing these log messages. To filter out these errors when viewing logs, customers can apply the following CloudWatch Logs Insights query filters when querying log groups. (Issue #2818)
CloudWatch Logs Insights Query Example for Filtering Organization Certificate Errors
fields @timestamp, @message, @logStream, @log | filter message != 'Error loading organization certificates. Initialization will continue, but untrusted SSL connections will fail.' | filter message != 'Client is not initialized - certificate array will be empty' | sort @timestamp desc | limit 20 -
If a reconciliation job, bulk edit of labels job, or bulk pipeline processing job is canceled, then the job’s ToDo, Failed, and Completed counts can sometimes display incorrectly.
Upgrade Considerations
Last updated: 6 June 2025
During the upgrade, there might be a brief downtime when users won't be able to access the TDP user interface and APIs.
After the upgrade, the TetraScience team verifies that the platform infrastructure is working as expected through a combination of manual and automated tests. If any failures are detected, the issues are immediately addressed, or the release can be rolled back. Customers can also verify that TDP search functionality continues to return expected results, and that their workflows continue to run as expected.
For more information about the release schedule, including the GxP release schedule and timelines, see the Product Release Schedule.
For more details on upgrade timing, customers should contact their CSM.
Upgrading from the EAP version of the Data LakehouseCustomers taking part in the EAP version of the Data Lakehouse will need to reprocess their existing Lakehouse data to use the new GA version of the Lakehouse tables. To backfill historical data into the updated Lakehouse tables, customers should create a Bulk Pipeline Process Job that uses an
ids-to-lakehousepipeline and is scoped in the Date Range field by the appropriate IDSs and historical time ranges.
For customers using the Tetra File-Log AgentAdded on: 6 June 2025
Customers can't edit or add file paths to the Tetra File-Log Agent through the TDP user interface. A fix for this issue is in development and testing and is scheduled for the next TDP patch release (TDP v4.3.1).
As a workaround to edit or add paths, customers should do either of the following:
Update the Agent's Configuration via the API, and make sure the label for instrument type > is
instrument_type.-or-
(For FLA 4.3.x or higher only) Edit or add file paths through the Agent Management Console. Saved changes are reflected in the TDP.
SecurityTetraScience continually monitors and tests the TDP codebase to identify potential security issues. Various security updates are applied to the following areas on an ongoing basis:
- Operating systems
- Third-party libraries
Quality ManagementTetraScience is committed to creating quality software. Software is developed and tested following the ISO 9001-certified TetraScience Quality Management System. This system ensures the quality and reliability of TetraScience software while maintaining data integrity and confidentiality.
Other Release Notes
To view other TDP release notes, see Tetra Data Platform Release Notes.
Updated 2 months ago