Tetra Empower Agent FAQs
The following are questions that TetraScience customers frequently ask about the Tetra Empower Agent.
Question Topics
Installation
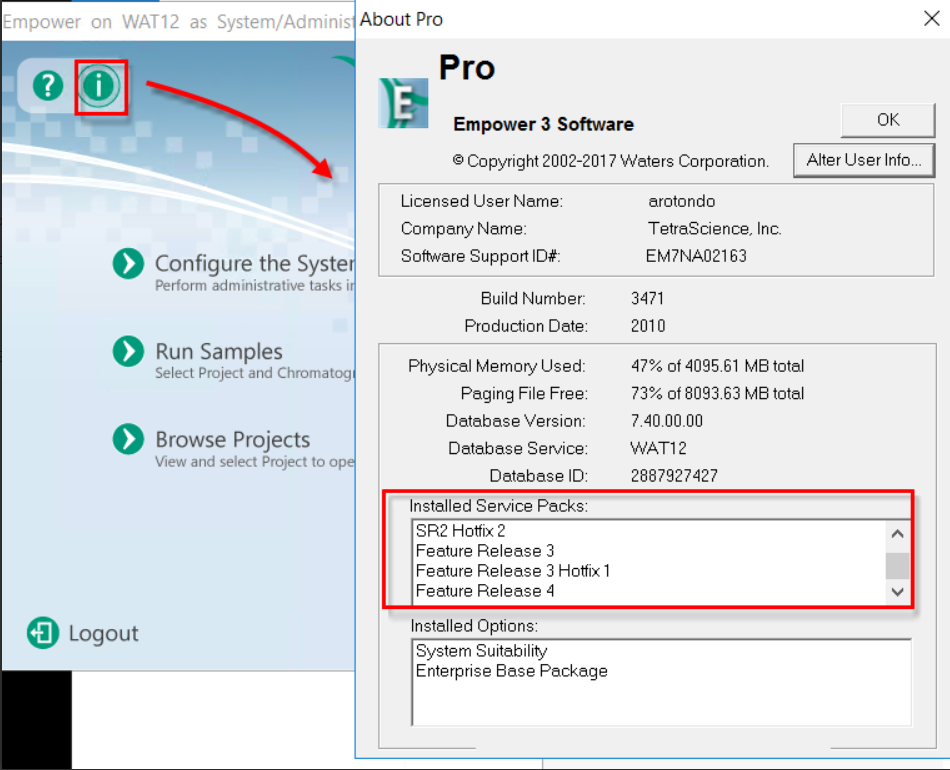
How do I find the production version of Empower?
Open Empower Client User Interface, click the Info button. The product release version can be found in Installed Service Packs section.
Which versions of Windows are supported?
The Tetra Empower Agent should be installed on the same computer as the Empower 3 Client.
The Tetra Empower Agent is compatible with Empower 3 Client Service Release 2 or higher. The latest version is Feature Release 5.
According to the Empower release notes (Empower 3 FR4 SR3), Empower Client can work on Windows 7 Professional or Enterprise SP1, 64-bit; Windows 10 Professional or Enterprise, 64 bit. The Tetra Empower Agent is compatible with all these versions of Windows.
Since Microsoft has stopped supporting some of the operating systems above, like Windows 7, TetraScience suggests installing the Empower Agent on the newest version of the Windows operating system to avoid possible unexpected behavior.
Is the Tetra Empower Agent a 32bit or a native 64bit application?
In the current version, Tetra Empower Agent contains three components: two Windows Services for scanning/ extracting Injection and generating & uploading Injection files, and a Microsoft WPF-based Management Console for configuration and progress monitoring.
The Windows service, which scans and extracts the Injection from Empower through ToolKit, is built as a 32-bit application because the Empower ToolKit is 32-bit. The other two components are 64-bit applications.
Can you specify minimum/typical/ideal hardware configurations required to run the agent?
The Tetra Empower Agent extracts the Injections from Empower and uploads them to TetraScience Data Platform.
The Agent has an option to retain the RAW files in a local drive or not.
If the RAW files are not retained, the files will be deleted once uploaded successfully. It is not required to add additional disk space.
If the RAW files are retained, the required disk space will be based on the size of the Projects and Injections.
Taking an example, for 90K injections, roughly 360 GB space is required. We recommend you allocate a separate drive for those injection files such that the Empower client application is not affected.
CPU requirements should match with the Empower client. We suggested 1X Intel E5-2620 V3 (4 cores @ 1.8 GHz). The recommended memory requirement is 16G and 8G at a minimum. Recommended network bandwidth is 1000 Mbps and 100 Mbps at a minimum.
Which version of EMPOWER is supported by the Tool?
The TetraScience Agent requires Empower 3 Client Service Release 2 or higher (SR 2 Hotfix 1, SR 2 Hotfix 2, FR 3, FR 3 Hotfix 1, FR 4, SR 3). Once Empower FR5 is released, the Empower Agent will be compatible with that release as well.
Does the agent need any change to be implemented at the Empower Acquisition Server?
No. The Agent performs standard operations through Empower Toolkit. No change is required for the Empower Acquisition Server.
Must Empower Client to be installed on the same machine?
Yes, the Agent extracts Injection through Empower ToolKit, which is part of Empower Client installation. Tetra Empower Agent will use Empower Client’s component to make the connection.
Must the agent software package be installed on each server in a CITRIX Farm if EMPOWER is running in CITRIX?
The TetraScience Agent only needs to be installed on one computer that runs the Empower Client. You can install multiple agents to spread the workload, for example, each agent targets certain projects.
Can a dedicated machine be used where no users to log in?
Yes, using a dedicated machine is highly recommended.
How are cultural markers, like commas or decimals for times and dates handled?
The Empower Installation guide (Empower 3 FR5), indicates that Empower software should be installed on the machine on the server with region setting as English-US.
If the Tetra Agent is installed on the server with region setting other than that, it might have unexpected behavior, e.g. the values of date, time or the decimal are not formatted correctly. Cultural markers for decimal places and units reflect US standards.
Performance
How is project data extracted from Waters Empower?
Data from Empower is extracted via the TetraScience agent. The TetraScience agent is a software that is installed with the Empower client, and it is responsible for extracting project data.
How does the Agent identify which injections have to be exported?
An internal SQLite database stores the Injection identifier by using the Empower Database Name, Project Name, and Injection ID.
The default logic is that, for every scan, the Agent scans all projects to detect new injections. This is due to the limitation of Empower ToolKit, since there is currently no indicator on the Project level that a new injection has been created, or that an existing injection has been reprocessed.
However, there are two mechanisms to avoid scanning all of the projects:
-
The customer can configure the Tetra Empower Agent to only re-scan the projects that are not locked. The assumption is that there will not be any changes to the locked projects.
-
Customers can enable Empower Audit Trail for their projects. Then, the Tetra Empower Agent will detect what projects and injections have been changed since the last scan.
If the export is executed the very first time: Are there any measures in place preventing the system from being impacted by high load due to a large amount of to be exported data?
Yes, the Empower Agent will scan all of the projects with which the Empower DB Account running the Agent has the permission to access. Users can configure the Agent to only scan certain projects.
To minimize the impact on the Empower system due to the extra load, several measures can be adopted
-
Configure the Tetra Empower Agent scanning to only take place during off-hours, for example, during the 9 pm to midnight in the Pacific time zone.
-
Configure the Tetra Empower Agent to only scan the projects that need to be analyzed.
-
Configure the Tetra Empower Agent to only re-scan the projects that are not locked. The assumption is that there will not be any changes to the locked projects.
-
Leverage Empower audit trail to detect what projects and injections have been changed since the last scan.
-
Create a separate drive for the Agent to store the extracted injection files or choose the option to not save injections.
Can the Tetra Empower Agent detect injections that are updated?
Yes, the Empower Agent can detect what projects and injections have been changed since the last scan. To enable this, there are two things you must do:
- The project must have the full audit trail enabled when it is created.
- The Empower Database User must have permission to view the Project Audit Trail.
When those conditions are met, the following example changes to a project will be detected:
-
Result/Result Set
Created Result Set
Created Manual Result
Created Result
Copied Result Set
Copied Result
Imported Result
Sign Off1 Result
Sign Off2 Result -
Sample Set/Sample
Run Sample Set
Altered Sample Set
Altered Running Sample Set
Resumed Paused Sample Set
Renamed Sample Set
Copied Sample Set
Created Process Only Sample Set
Altered Process Only Sample Set
Altered Sample -
Injection
Run Single Injection
Imported Injection
The reprocessed files create a new version of the files in the Data Platform. The Data Platform will mark the previous version as outdated, but will still keep the previous versions in the Data Platform.
Change detection on copied injectionsIf an injection is copied from another project and does not have an associated sample set in the target project, changes to that injection will not be detected. For example, when a sample is altered in the copied injection and the audit trail message includes "Sample Set ID: 0" (an invalid ID) then the injection will not be regenerated. For a change to be detected, the audit trail message should contain a valid "Result ID," "Result Set ID," "Sample Set ID," or "Injection ID" value.
What events trigger the Agent to regenerate/reupload the Project/User access permission data
The Tetra Empower Agent generates a JSON file containing the information of Empower User, User Types, User Group, and the list of the Projects associated with the User Group.
The Agent regenerates the JSON file when the following conditions happen:
- Add or delete Empower Projects
- Add or delete Empower Users
- Add or remove User Group to the Projects
- Delete User Group which has been assigned to a Project
- Add or remove users from the User Group which is assigned to a Project
The regenerated JSON file will be uploaded to Tetra Data Platform as a new version file.
How Does the Agent Generate the Injections with the Result Sign Off Options?
The Injection generation and the content included is based on the Result Sign Off option selected by the user. The option is selected based on the individual project.
| Option | Injection | Result | Sign Off |
|---|---|---|---|
| Not Required | All of the Injections in the Project | All of the Results associated with the Injections | All of the Sign Offs included in the output Result |
| Level One | Only the Injection containing Result with Level One Sign Off If the injection has no Result containing Level One Sign Off. That injection should not be outputted | The Result containing Level One Sign Off | All of the Sign Offs included in the qualified output Result |
| Level Two | Only the Injection containing Result with Level Two Sign Off If the Injection has no Result having Level Two Sign Off, that injection should not be outputted. | The Result containing Level Two Sign Off | All of the Sign Offs included in the qualified output Result |
Can the export be directed to already existing “in-house” data lakes?
Yes, TetraScience can leverage its APIs or a configured Data Pipeline to push data to the client’s “in-house” data lakes.
The destination can be both cloud or on-premise databases.
How long it would take for a project to be available in TetraScience Data Platform once they are in the Empower server?
It depends on two things.
-
The size of the newly added project, namely how many injections is in the project. It typically takes less than a second to collect and then normalizes the data for one injection, thus the lag is on the order of hours for a typical project.
-
System Capacity, high-performance CPU and enough RAM (at least 8G) help improve overall performance.
How to make Tetra Empower Agent scale up?
The client can take advantage of a feature that Tetra Empower Agent allows to select the Projects to be generated. So multiple Tetra Empower Agents can be deployed. One Agent per one Empower Client.
Selecting different Projects for each Agent, this way the entire processes are running in parallel. It will largely increase the overall throughput.
What happens when the same project is renamed/moved?
If the project is renamed or moved to a different location in the same Empower instance, their injections will be treated as new injections since TetraScience uses the project name and project path to form the unique key to identify new injections.
What happens when the project is created/added?
If a new project is added or imported to the Empower instance, that project will be shown in the Projection selection tab. The System Administrator selects the project manually and saves the change to have the Agent output the RAW files.
What happens when the project is removed/deleted?
If a project is deleted or moved from the Empower instance, the extracted injection data in Data Platform still remains.
How big are the JSON files compared to the original Empower projects?
As of Q3 2018, for a project that is ~13GB large, the combined size of the JSON representation is ~24GB. TetraScience is actively working on leveraging more advanced technology to reduce the size of the extracted data.
How does "Continue on Toolkit Error" setting in Empower Agent Management Console impact Injection RAW JSON generation and what toolkit errors are tracked?
The "Continue on Toolkit Error" setting is available in Empower Agent v5.0.0 and above. The default setting for this is "No".
When the "Continue on Toolkit Error" toggle is set to "No", the Agent will log any toolkit errors it encounters during the Injection RAW JSON generation and will not generate the RAW JSON if following toolkit errors are found:
- 105 - Error fetching Channel Chromatography data
- 408 - Method could not be opened in the Project
- 42F - An option is required in order to access this interface
- 267 - An option is required to open this method. Please make sure this option is enabled in the project
- 40e - Cannot open Method because it is being edited by another user
- 214 - Could not fetch requested method
- 215 - Method is permanently locked
- 216 - Method is currently being edited by another user
- 217 - Method is too big
- 232 - Chrom: Invalid Chromatogram type.
- 233 - Chrom: There are too may IDs to be fetched
- 234 - Chrom: Cannot open file
When the "Continue on Toolkit Error" toggle is set to "Yes", the Agent will log any toolkit errors it encounters during Injection RAW JSON generation, but continue to generate the RAW JSON file.
Administration
Is the agent configurable to export only injections from pre-defined projects/user groups?
Yes. First, user accounts assigned to the agent will determine which projects the Tetra Empower Agent can access. This can be configured at setup/installation while creating the Empower user account that the Agent can use. Second, the Agent can be configured to only scan and extract injections from selected projects. This can be configured via the Agent Management Console
Is something like a management console existing that will enable easy management of the entire solution.
Yes, management exists in two places corresponding to specific functionality. The Empower Agent has its own Management Console for configuration settings, project selection, backup/export schedule, status and setup configuration functions. The Tetra Hub and integration can be managed from the web UI of the Tetra Data Platform.
Is the exported data a true copy?
Tetra Empower Agent will extract data from Empower package the data on injection level and convert that into JSON per injection. This JSON file contains all the important data that customers care about, such as peak table, method, injection, result and etc. It enables visualization, search, customer application, and ELN integration.
Is there evidence showing that the agent software is structurally validated by the vendor?
TetraScience has a quality procedure focused on Empower integration that compares data generated from the Agent with data stored in the Empower.
What will be the effort required to manage the solution in terms of error handling and monitoring?
TetraScience will manage, support, and upgrade the Tetra Data Platform (TDP) as it is deployed in its dedicated AWS account that's owned by the customer. TetraScience requires the customer to provide assistance in troubleshooting issues that are related to customer business logic.
TetraScience provides different levels of support to the following user groups:
- Tier 1, key users (TetraScience will provide runbook and documentation)
- Tier 2, customer IT (TetraScience will provide runbook and documentation) + (TetraScience)
- Tier 3, vendor
Tetra Empower Agent errors can occur at the following two levels, which is where monitoring also takes place:
-
Empower Agent Level. To monitor Empower Agent errors, status, or other parameters, the administrator must have access to the following:
- The detailed error messages that are stored in the SQLite database. They must also be able to see the errors or reprocess the failed injections in the Tetra Empower Agent console.
- The error is logged to log files, which are uploaded to the TDP periodically. The errors can be searched and trigger alerts or notifications to the TetraScience Support team at <customer-name>[[email protected]].
-
Data Pipeline Level. If data standardization fails, error logs are collected through Amazon CloudWatch. The error logs then trigger a notification to the TetraScience Support Team at <customer-name>[[email protected]]. Business logic related to who should receive error notification due to validation or other pipeline script failure can be configured to client specifications. For example, if the client chooses to enforce a validation step that requires the presence of a Sample or project ID, values can be configured to reach that USER with a notification. If the failure is due to file format/mismatch/data corruption or something else, an Administrator could receive an alert.
What are the Empower output files and archiving policies?
| Agent & Service | Output File Type | Output Folder | Archiving (folder) |
|---|---|---|---|
| Empower Agent Injection Service | Raw File | Specified by user in Management Console | Specified by the System Administrator whether the Raw files should be archived. The Agent will either keep the files in the output folder or delete the files after the files are uploaded successfully, if the System Administrator selects |
| Empower Agent Injection Service | Agent Log | Logs folder under the Agent installation folder | The Agent logs will be archived in every When succeeded, the logs will be moved to If the log files are failed to be uploaded to the Data Platform, the files will remain in the The Agent will keep the Agent log files up to 72 hours. After that, the Agent will delete the Agent Log files to save local disk space |
| Empower Agent Archive Service | Injection Description file and Project back up file | Specified by user in Management Console | When both files are successfully uploaded to S3 bucket, they will be removed from output folder. If file upload is not succeeded, the Agent will retry (The retry time is user specified in Management Console) till it reaches the max retry time If the file are still not uploaded, they will be remained in the output folder |
| Empower Agent Archive Service | Audit Trail | Upload to the CouldWatch group/stream, specified by the user in Management Console | No files written to local folder |
| Empower Agent Archive Service | Agent Log | Logs folder under Agent installation folder | Keep the Agent log files up to 72 hours. After that, the Agent will delete the Agent log files to save local disk space |
What are minimum set of privileges required for the Empower user in Agent?
This table provides the information for the minimum privileges required by the Empower User and the Empower Group User (Windows user) that are configured in the Agent.
| Agent Service | Empower User privileges | Empower Group User permissions (Windows user) | Requires Empower user access to Empower project? |
|---|---|---|---|
| Injection Service | View Audit trails | Read permission required to raw files folder on the Empower server | Yes |
| Non-Experiment Service System Audit Trail | View Audit trails | Not applicable | Not applicable |
| Non-Experiment Service Project Audit Trail | View Audit trails | Not applicable | Yes |
| Non-Experiment Service Message Center | View Message Center for All users | Not applicable | Not applicable |
| Non-Experiment Service User/Project permission | View Audit trails | Not applicable | No |
| Command Service Fetch Sample Set Method Command | None | Not applicable | Yes |
| Command Service Create Sample Set Method Command | Save Sample Set Methods | Not applicable | Yes |
Documentation Feedback
Do you have questions about our documentation or suggestions for how we can improve it? Start a discussion in TetraConnect Hub. For access, see Access the TetraConnect Hub.
NOTEFeedback isn't part of the official TetraScience product documentation. TetraScience doesn't warrant or make any guarantees about the feedback provided, including its accuracy, relevance, or reliability. All feedback is subject to the terms set forth in the TetraConnect Hub Community Guidelines.
Updated 2 months ago