Tetra OS: The Operating System for Scientific Intelligence
TetraScience is the Scientific Data and AI company and the builder of Tetra OS, the operating system for Scientific Intelligence. Tetra OS is designed to deliver on the promise of Scientific AI by converting the raw data materials of science into compounding Scientific Intelligence through four integrated capabilities: the Scientific Data Foundry, the Scientific Use Case Factory, Tetra AI, and Tetra Sciborgs.
For the first time, life sciences organizations can move beyond fragmented, bespoke data projects and build on top of a unified architecture that industrializes AI-native scientific data, scientific workflows, and scientific reasoning across discovery, development, and manufacturing.
Key Business Outcomes
- Automate the assembly, transfer, and contextualization of scientific data in a centralized, purpose-built scientific data architecture.
- Transform raw scientific data into contextualized, harmonized, large-scale, and liquid AI-native data.
- Productize scientific workflows, ontologies, and analytical applications as reusable scientific use cases.
- Achieve better scientific outcomes by enabling Scientific AI on top of high-fidelity data, reusable workflows, and embedded scientific expertise.
For use case examples, see Example Use Cases. For more information and best practices, see the TetraConnect Hub. To request access, see Access the TetraConnect Hub.
How It Works
Tetra OS's Scientific Data Foundry connects the laboratory ecosystem and eliminates manual, time-consuming data management tasks. Industrialized integrations with instruments, informatics applications, and software systems across R&D, manufacturing, and QC enable near real-time data capture, stronger data integrity, and continuous flow of scientific data into the Foundry.
Data within the Foundry is standardized in structure and semantics at the point of creation—deconstructed into atomic units (measurements, metadata, instrument telemetry), and reconstructed into machine-interpretable schemas, taxonomies, and ontologies. Then, they're reconstructed into AI-native schemas, taxonomies, and ontologies. This is the foundation that makes scientific data governable, reusable, and ready for downstream workflows, analytics, and AI.
Once data are standardized and AI-native in the Foundry, the Scientific Use Case Factory industrializes scientific intelligence by turning one-off scripts, applications, workflows, and ontologies into validated, productized, and reusable assets. Tetra AI then builds on that structure to provide scientific reasoning and agentic capabilities, while Tetra Sciborgs embed with teams to drive adoption and operational transformation.
Get Value at Every Step in the Scientific AI Journey
There is only one way to fulfill the basic needs of lab connectivity while building the foundation for Scientific AI: establish a shared architecture for AI-native scientific data, reusable scientific workflows, and scientific reasoning.
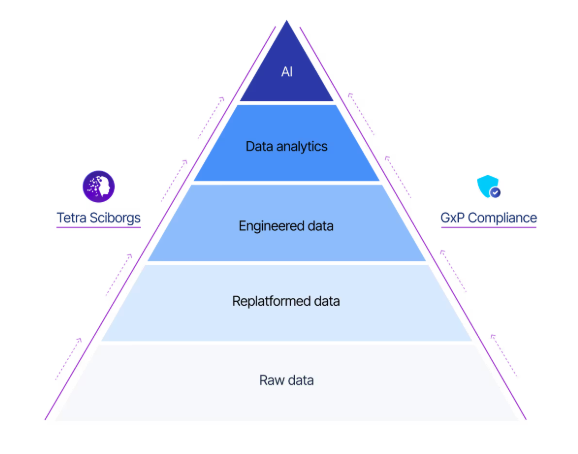
Tetra OS facilitates the following steps in the scientific data and AI journey:
- Data replatforming: Liberate scientific data from silos and centralize it in a secure, accessible environment while preserving scientific context and compliance attributes.
- Data engineering: Transform raw data into harmonized, contextualized data with consistent schemas, taxonomies, and ontologies.
- Scientific analytics and use cases: Productize scientific workflows, analytical applications, and ontology-driven use cases as reusable assets in the Scientific Use Case Factory.
- Scientific AI: Enable Tetra AI to reason across high-fidelity data and validated workflows to accelerate decisions and improve scientific outcomes.
Tetra OS Components
Tetra OS consists of the following components.
Scientific Data Foundry
The Scientific Data Foundry is the foundational data layer of Tetra OS. It deconstructs proprietary and unstructured scientific data into atomic units and reconstructs them into AI-native schemas, taxonomies, and ontologies. By standardizing structure and semantics at the point of creation, the Foundry industrializes the production of AI-native scientific data.
The Foundry provides vendor neutrality, composability, governance, lineage, and continuous improvement so data can be reused across instruments, vendors, workflows, and scientific domains without losing context.
Tetra Integrations
Tetra Integrations automatically collect and move scientific data between instruments, applications, and software systems into the Scientific Data Foundry. These industrialized integrations support broad connectivity across instruments, ELNs, LIMS, middleware, and data science tools, enabling scientific data to flow continuously into a shared architecture.
For a list of available Tetra Integrations, see Supported Tetra Integrations.
Tetra Data Pipelines
Tetra Data Pipelines automate data operations and transformations as new data are ingested and processed. These pipelines operationalize the movement from raw source data to harmonized, AI-native data in the Scientific Data Foundry and support downstream use in the Scientific Use Case Factory.
Intermediate Data Schemas
Intermediate Data Schemas (IDSs) standardize raw instrument data and report files by mapping vendor-specific information to vendor-agnostic structures. They normalize naming, data types, ranges, and hierarchies so that data from different instruments and systems become predictable, consistent, and reusable.
Schemas, Taxonomies, and Ontologies
TetraScience provides and supports AI-native schemas, taxonomies, and ontologies that capture scientific meaning and make data machine-interpretable. These are foundational to the Scientific Data Foundry and become increasingly valuable as they are reused and refined across scientific workflows and use cases.
Scientific Use Case Factory
The Scientific Use Case Factory is the execution layer of Tetra OS for anything at the scientific use case, ontology, workflow, or data app level. It replaces fragmented, project-based approaches with an industrial production model in which use cases are designed, validated, productized, and continuously improved as durable, reusable assets.
Each use case can be built once, validated once, and then reused and refined across teams, sites, and scientific domains. This includes analytical workflows, scientific applications, ontology-driven workflows, deviation detection, yield prediction, in silico modeling, process analytics, and other AI-enabled scientific use cases.
Tetra AI
Tetra AI builds directly on the Scientific Data Foundry and the Scientific Use Case Factory because agents require order to act intelligently. It provides semi-autonomous and fully autonomous agentic capabilities that assist scientists across complex, multi-step processes by identifying relevant data, traversing broader scientific spaces, surfacing patterns, and guiding better decisions.
Tetra AI is not a generic AI wrapper. It is a scientific reasoning layer grounded in ontologies, provenance, and validated workflows so that intelligence is rooted in scientific context rather than disconnected tokens.
Tetra Data Platform
The underlying Tetra Data Platform architecture supports the Scientific Data Foundry, Scientific Use Case Factory, and Tetra AI while providing a user interface for scientists and administrators. It ingests raw data from Tetra Integrations and supports standardized intermediate representations, search, graph-oriented representations, and tabular data structures that enable downstream retrieval, analytics, and operational workflows. These capabilities make scientific data findable, accessible, interoperable, and reusable at scale.
Tetra Quality Management System
The Tetra Quality Management System (QMS) helps ensure data integrity, traceability, reliability, and availability through capabilities such as audit trails, disaster recovery, control matrices, and software hazard analysis.
Tetra Sciborgs
Tetra Sciborgs are embedded scientist-engineers who operate at the nexus of science, data, and AI. They help operationalize the Foundry, scale the Factory, accelerate adoption of Tetra AI, and bridge the persistent divide between scientists, IT, data, and AI teams.
Sciborgs are not traditional consultants. They are builders and translators who embed with customer teams to turn architecture into operating reality and to increase the value of a Tetra deployment through adoption, standardization, and continuous improvement.
Tetra Partner Network
The Tetra Partner Network (TPN) is a global community of life sciences technology providers dedicated to unlocking the power of scientific data and accelerating the delivery of life-changing therapies. It expands access to the Tetra architecture across the scientific ecosystem.
Documentation Feedback
Do you have questions about our documentation or suggestions for how we can improve it? Start a discussion in TetraConnect Hub. For access, see Access the TetraConnect Hub.
NOTEFeedback isn't part of the official TetraScience product documentation. TetraScience doesn't warrant or make any guarantees about the feedback provided, including its accuracy, relevance, or reliability. All feedback is subject to the terms set forth in the TetraConnect Hub Community Guidelines.
Updated 2 months ago