Data Lakehouse Architecture
The TetraScience Data Lakehouse is designed to help life sciences organizations unlock opportunities for innovation and efficiency in drug discovery and development. The new data storage and management architecture provides 50% to 300% faster SQL query performance than the legacy Tetra Data Lake and an AI/ML-ready data storage format that operates seamlessly across all major data and cloud platform vendors.
What is a Data Lakehouse?
A data lakehouse is an open data management architecture that combines the benefits of both data lakes (cost-efficiency and scale) and data warehouses (management and transactions) to enable analytics and AI/ML on all data. It is a highly scalable and performant data storage architecture that breaks data silos and allows seamless, secure data access to authorized users.
TetraScience has adopted the ubiquitous Delta storage format to transform RAW data into refined, cleaned, and harmonized data, while empowering customers to create aggregated datasets as needed. This process is referred to as the “Medallion” architecture, which is outlined in the Databricks documentation.
Benefits
The new Data Lakehouse Architecture provides the following benefits:
-
Share data directly with any Databricks and Snowflake account
-
Run SQL queries faster and more efficiently
-
Create AI/ML-ready datasets while reducing data preparation time
-
Reduce data storage costs
-
Configure Tetraflow pipelines to read multiple data sources and run at specific times
-
Reduce version changes for SQL tables
To start getting the performance benefits of the new Lakehouse architecture, customers can convert their historical Tetra Data to Lakehouse tables. These data backfills can be scoped by specific Intermediate Data Schemas (IDSs) and historical time ranges as needed. Customers can then Transform Tetra Data in the Lakehouse for specific use cases by using a Tetraflow pipeline.
Architecture
The following diagram shows an example Data Lakehouse workflow in the Tetra Data Platform.
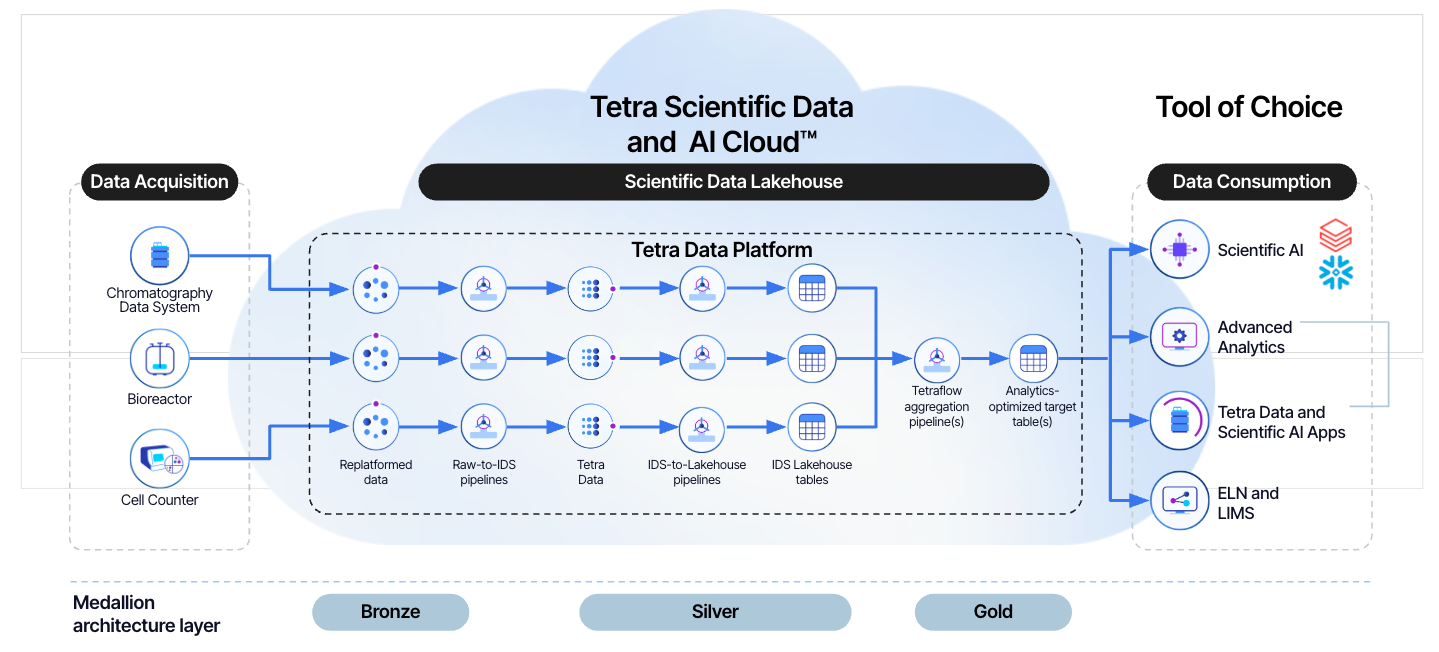
The diagram shows the following process:
- The TDP provides bidirectional integrations for instruments, Electronic Lab Notebooks (ELNs), Laboratory Information Management Systems (LIMS), connectivity middleware, and data science tools. It can also connect with contract research organizations (CROs) and contract development and manufacturing organizations (CDMOs). For a list of available Tetra Integrations, see Tetra Integrations.
- The TDP converts raw data into engineered Tetra Data by using the
raw-to-idsprotocol in a Tetra Data Pipeline and stores it in the Data Lakehouse. - Data is converted to Lakehouse Tables in an open-source Delta Lake format by using either the
ids-to-lakehouse(for Tetra Data) ordirect-to-lakehouseprotocol (for structured reference data) in another pipeline. Creating a second type of normalized Lakehouse tables (normalized IDS Lakehouse tables and normalized Datacubes Lakehouse tables) is optional. These normalized tables transform Lakehouse tables from the new, nested Delta Table structure to a structure that mirrors the legacy Amazon Athena table structure in the Data Lakehouse. They reduce the need for rewriting existing queries.
IMPORTANTCreating normalized Lakehouse tables introduces higher data processing costs and latency (minimum 20 minutes) than the default nested Lakehouse Tables.
- Two additional types of tables are created for each IDS Lakehouse Table:
- File Info Tables mirror the information provided in the legacy Athena
file_info_v1tables. - File Attribute Tables mirror the information provided in the legacy Athena
file_attribute_v1tables.
- File Info Tables mirror the information provided in the legacy Athena
- Customers can then run Tetraflow pipelines to define and schedule data transformations in a familiar SQL language and generate custom, use case-specific Lakehouse tables that are optimized for downstream analytics applications.
NOTETo use the Data Lakehouse Architecture, customer proxies must provide limited internet access for pyPi package installation. The Data Lakehouse Architecture doesn't currently support restricted, customer-hosted environments that use a proxy to connect to the TDP and have no internet access.
Start Using the Data Lakehouse
To start using the Data Lakehouse, do the following:
- Convert your data into Lakehouse tables.
- Transform your data in the Lakehouse for specific use cases by using Tetraflow pipelines.
Lakehouse Data Access
You can transform and run SQL queries on data in the Lakehouse by using any of the following methods:
- A third-party tool and a Java Database Connectivity (JDBC) or Open Database Connectivity (ODBC) driver endpoint
- The SQL Search page in the TDP user interface
- Databricks Delta Sharing
- Snowflake Data Sharing
For best practices on querying data in the Lakehouse, see Query Lakehouse Tables.
Automate Databricks Delta Sharing
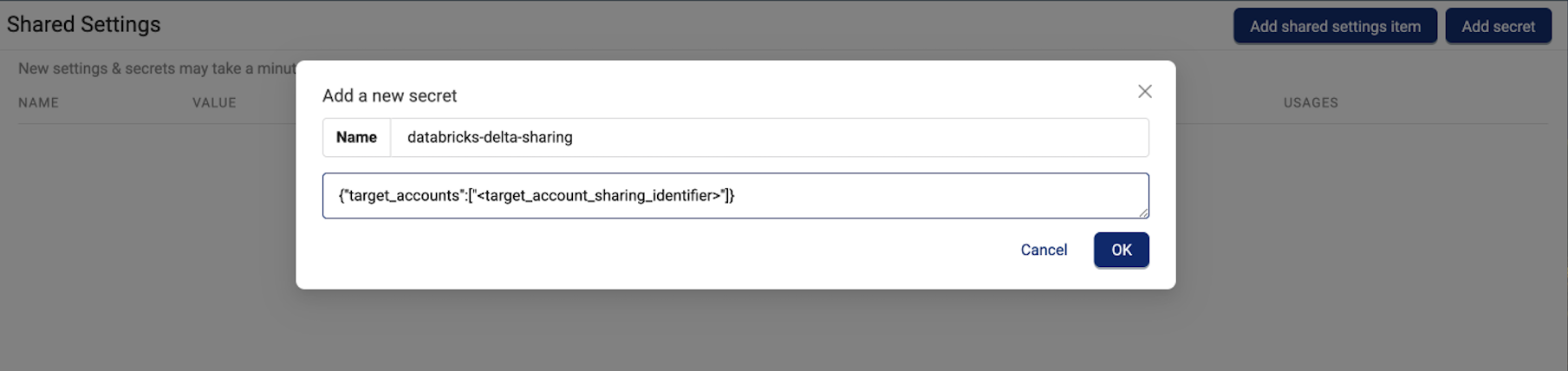
To have your Lakehouse databases automatically synced to your Databricks Delta Shares, create a new secret in your TDP organization named databricks-delta-sharing. Then, enter your Databricks sharing identifier as the secret value.
Make sure that you enter the secret value in the following format:
- For single shared accounts:
{"target_accounts":["<sharing_identifier>"]} - For multiple shared accounts:
{"target_accounts":["<sharing_identifier_1>","<sharing_identifier_2>"]}
You can also include an optional frequency field that controls how often your shares are reconciled—for example, {"target_accounts":["<sharing_identifier>"],"frequency":"12 hours"}. If you omit it, shares are reconciled once per day at midnight UTC by default. For details and important caveats, see Set the share reconciliation frequency.
For more information about setting up Delta Shares, see Create and manage shares for Delta Sharing in the Databricks documentation.
Set the share reconciliation frequency
The optional frequency field controls how often your organization's schemas are reconciled—that is, forced to appear in (be shared to) the destination Databricks account. Schemas aren't published to the destination the moment they're created: when a new schema appears (for example, a new IDS type), it isn't consumable from your Delta Share until the next reconciliation job runs. The frequency you choose is therefore the longest you might wait for a newly added IDS type to become available downstream—a shorter period surfaces new schemas sooner, but runs the job more often.
frequency is optional. If you omit it, shares are reconciled once per day at midnight UTC by default. This platform-wide default applies to every organization that doesn't set its own frequency. It's configured at deployment through the DeltaSharingDefaultFrequency CloudFormation stack parameter and is managed by TetraScience; to change it, contact your TetraScience CES contact.
Provide frequency as a <number> <unit> string, where the unit is minutes, hours, days, weeks, or months (singular or plural, and case-insensitive). For example: "30 minutes", "12 hours", "1 day", or "1 week".
IMPORTANTKeep the following in mind when setting
frequency:
Schedules are anchored to the start of the parent period, not to a rolling interval since the last run. The count restarts at the top of every hour for minute-based values, at midnight for hour-based values, on the first of the month for day-based values, and in January for month-based values. If your value doesn't divide evenly into its parent period, the final window is shorter than the interval you set—and the job can run a different number of times than you'd expect. For example,
"30 minutes"runs twice an hour (at:00and:30);"40 minutes"also runs only twice an hour (at:00and:40, then the count resets at the next hour), so the larger interval doesn't reduce the number of runs."25 minutes"runs three times an hour (:00,:25,:50), leaving only a 10-minute gap before the reset. For an even cadence, choose a value that divides its parent period evenly—for minutes, use 5, 10, 12, 15, 20, or 30; for hours, use 1, 2, 3, 4, 6, 8, or 12.Minute-based values below 5 are rejected. If you set a
frequencysuch as"2 minutes", the value isn't applied: an existing share keeps its current frequency, and if no share exists yet, it isn't created. Use"5 minutes"or longer.Very short periods can overlap and be skipped. Reconciliation jobs run on Databricks job clusters, which take a few minutes to start. With short periods (around 10 minutes or less), a run can still be in progress when the next one is scheduled. Overlapping runs aren't allowed—only one run of the job can be active at a time—so the run that would overlap is skipped. Choose a period comfortably longer than the job's typical runtime; the daily default is recommended unless you need schemas to appear sooner.
At unit boundaries, use the next-larger unit. Minute values must be under 60 (use
hoursfor 60 minutes or more), and hour values must be under 24 (usedaysfor 24 hours or more). Only"1 week"is supported for weeks; usedaysfor other multiples. For example, use"1 hour"rather than"60 minutes".
Lakehouse Tables
When data is converted into Lakehouse Tables, which use an open-source Delta Lake format, three types of tables are created automatically:
- Lakehouse tables, which are the new nested-format Delta Tables. To access the new IDS Lakehouse tables, customers will need to update their existing queries to align with the new table structure eventually.
- File Info Tables mirror the information provided in the legacy Athena
file_info_v1tables. - File Attribute Tables mirror the information provided in the legacy Athena
file_attribute_v1tables.
You can also choose to create normalized Lakehouse tables (Normalized IDS and Normalized Datacubes tables), which transform Lakehouse tables from the new, nested Delta Table structure to a normalized structure that mirrors the legacy Amazon Athena table structure in the Data Lakehouse. They reduce the need for rewriting existing queries that use the legacy table strucutre.
IMPORTANTKeep in mind the following:
Lakehouse tables (Delta Tables) use slightly different table names and column names than the legacy SQL table structure used in Amazon Athena. For more information, see Table Names and Column Names.
SQL queries run against the Lakehouse tables generated from Cytiva AKTA IDS (
akta) SQL tables aren’t backwards compatible with the legacy Amazon Athena SQL table queries. WhenaktaIDS SQL tables are converted into Lakehouse tables, the following table and column names are updated:
The source
akta_v_runAmazon Athena SQL table is replaced with anakta_v_rootLakehouse table.The
akta_v_run.timecolumn in the source Amazon Athena SQL tables is renamed toakta_v_root.run_time.The
akta_v_run.notecolumn in the source Amazon Athena SQL tables is renamed toakta_v_root.run_note.These updated table and column names must be added to any queries run against the new akta IDS Lakehouse tables. A fix for this issue is in development and testing and is scheduled for a future release.
Table Names
To make it easier to share data across all major data and cloud platform vendors, Lakehouse table names use the following format.
Lakehouse Table Name Format:
{ORG_SLUG}__tss__{IDS_SLUG}.table_name for tables generated using the Generally Available version of the Lakehouse (4.3.0+). A new top-level schema will be generated for each IDS ingested into the Lakehouse.
{ORG_SLUG}__tss__default.table_name for tables generated in the limited availability release period (TDP 4.2.x)
Legacy SQL tables in Amazon Athena remain unchanged and continue to use the following format.
Legacy SQL Table Name Format: {ORG_SLUG}.table_name
Column Names
The Delta protocol uses different table and column naming conventions than the legacy SQL tables in Amazon Athena. Because these naming conventions are different, Lakehouse tables replace the following characters in their column names with an underscore (_):
- Accents
- Any characters that aren't part of the American Standard Code for Information Interchange (ASCII)
- The following special characters:
,;{}()\n\t=%/& - Column names that start with a number
IMPORTANTFor SQL queries that source from Lakehouse tables which contain column names that have any of the affected characters, you must change the column references in your queries to reflect the new underscored (
_) column names.
View Lakehouse Tables
You can use the SQL Search page in the TDP To view and navigate between Lakehouse tables (Delta Tables), legacy SQL tables in Athena, and the system table database. For more information, see Query SQL Tables in the TDP.
Lakehouse Ingestion Data Validation
To help ensure data integrity, Lakehouse tables provide schema enforcement and data validation for files as they’re ingested into the Data Lakehouse. Any file ingestion failures are recorded on the Files Health Monitoring dashboard in the File Failures section. You can reprocess these failed files by running a Reconciliation Job.
Documentation Feedback
Do you have questions about our documentation or suggestions for how we can improve it? Start a discussion in TetraConnect Hub. For access, see Access the TetraConnect Hub.
NOTEFeedback isn't part of the official TetraScience product documentation. TetraScience doesn't warrant or make any guarantees about the feedback provided, including its accuracy, relevance, or reliability. All feedback is subject to the terms set forth in the TetraConnect Hub Community Guidelines.
Updated 28 days ago