TDP v4.1.0 Release Notes
Release date: 29 August 2024
TetraScience has released its next version of the Tetra Data Platform (TDP), version 4.1.0. To help unlock opportunities for innovation and efficiency in drug discovery and development, this release introduces a new Data Lakehouse Architecture early adopter program (EAP).
The new data storage and management architecture provides up to 10 times faster SQL query performance and an AI/ML-ready data storage format that operates seamlessly across all major data and cloud platform vendors. To help customers get started with the new architecture, TDP v4.1.0 includes several new artifacts:
- An
ids-to-deltaprotocol to create new open-format Lakehouse tables (Delta Tables) from existing Intermediate Data Schema (IDS) data - A Tetraflow pipeline artifact to define and schedule data transformations in a familiar SQL language and generate custom, use case-specific Lakehouse tables that are optimized for downstream analytics applications
This release also includes new Custom Roles for defining precise user permissions, an improved platform health monitoring dashboard for data integrations, and several other new functionalities and enhancements.
Here are the details for what’s new in TDP v4.1.0.
SecurityTetraScience continually monitors and tests the TDP codebase to identify potential security issues. Various security updates are applied to the following areas on an ongoing basis:
- Operating systems
- Third-party libraries
Quality ManagementTetraScience is committed to creating quality software. Software is developed and tested following the ISO 9001-certified TetraScience Quality Management System. This system ensures the quality and reliability of TetraScience software while maintaining data integrity and confidentiality.
New Functionality
New functionalities are features that weren’t previously available in the TDP. The following are new functionalities introduced in TDP v4.1.0.
GxP Impact AssessmentAll new TDP functionalities go through a GxP impact assessment to determine validation needs for GxP installations. New Functionality items marked with an asterisk (*) address usability, supportability, or infrastructure issues and do not affect Intended Use for validation purposes, per this assessment. Enhancements and Bug Fixes do not generally affect Intended Use for validation purposes. Items marked as either Beta release or early adopter program (EAP) are not suitable for GxP use.
Performance and Scale
Data Lakehouse Architecture (EAP)*
A new Data Lakehouse Architecture early adopter program (EAP) provides up to 10 times faster SQL query performance, creates AI/ML-ready datasets automatically, and operates seamlessly across all major data and cloud platform vendors.
Benefits
- Fast, efficient SQL querying
- Creates AI/ML-ready datasets while reducing data preparation time
- Reduced data storage costs
- Ability to configure Tetra Data Pipelines to read multiple data sources and run at specific times
- Reduced version changes for SQL tables
How It Works
A data lakehouse is an open data management architecture that combines the benefits of both data lakes (cost-efficiency and scale) and data warehouses (management and transactions) to enable analytics and AI/ML on all data. It is a highly scalable and performant data storage architecture that breaks data silos and allows seamless, secure data access to authorized users.
TetraScience is adopting the ubiquitous Delta storage format to transform data into refined, cleaned, and harmonized data, while empowering customers to create aggregated datasets as needed. This process is referred to as the “Medallion” architecture, which is outlined in the Databricks documentation.
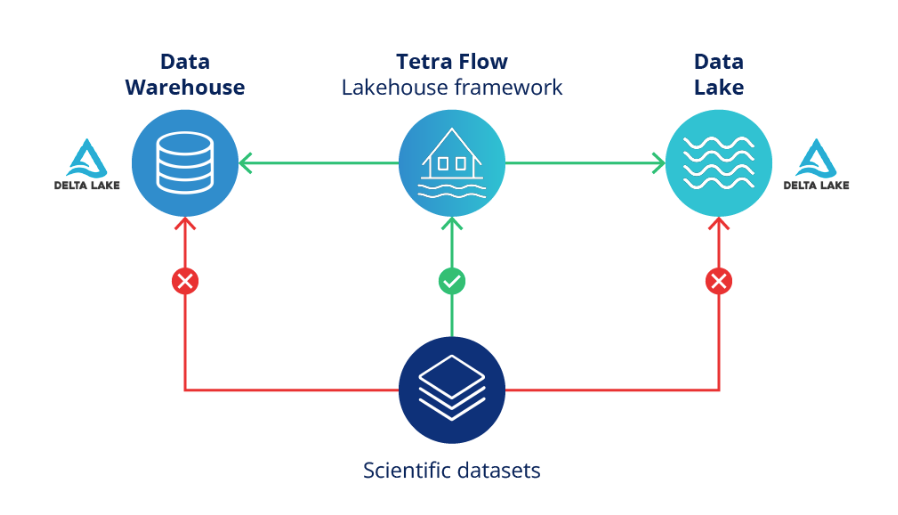
The Data Lakehouse Architecture is available to all customers as part of an early adopter program (EAP) and will continue to be updated in future TDP releases. If you are interested in participating in the program, please contact your customer success manager (CSM).
For more information, see Data Lakehouse Architecture (EAP).
Data Integrations
Download Agent Configurations from the TDP UI
NOTETo start, the Download Configuration button works for Tetra File-Log Agents only. This functionality will be added to other Tetra Agents on a rolling basis through future Agent releases.
To improve support and reduce troubleshooting time, customers can now download an Agent’s latest configuration settings directly from the TDP user interface (UI) by using a new Download Configuration button in the Info tab for each Agent on the Agents page. Previously, customers needed to download configuration files by using the Get File-Log Agent Configuration API endpoint.
For more information, see Download Agent Configuration Settings.
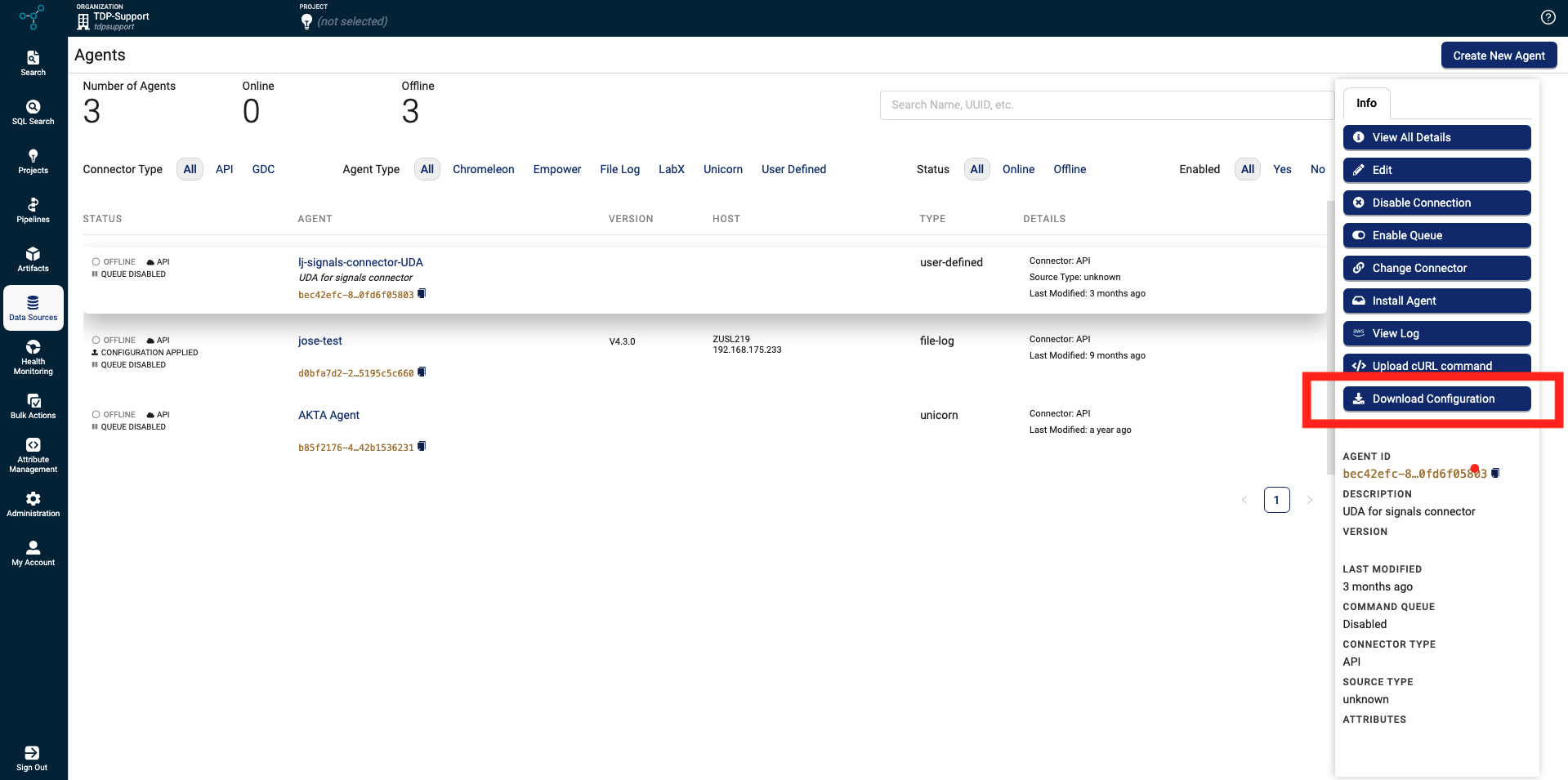
Download Configuration button on the Agents page
Send Agent Database Backups to TetraScience for Troubleshooting
To improve support and reduce troubleshooting time, customers can now send an Agent’s configuration data as an SQLite file directly from the TDP to the TetraScience Support Team along with the Agent’s Amazon CloudWatch logs.
For more information, see Send Integration Logs to TetraScience for Troubleshooting.
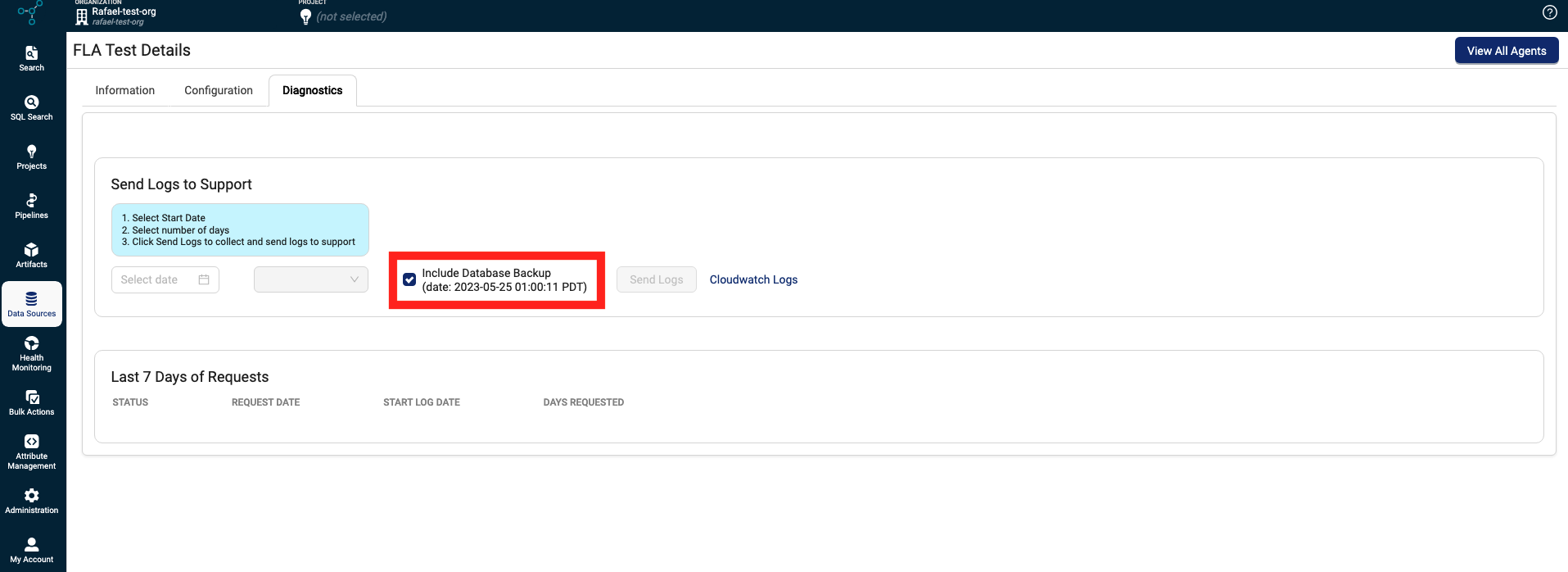
Include Database Backup option in the Diagnostics tab on the Agent Details page
Search for IoT Agent Devices by Serial Number*
Customers can now search for IoT Agent devices by serial number on the IoT Agents page by using the Search Name, UUID or Serial # bar.
For more information, see View Existing Tetra IoT Agent Devices.
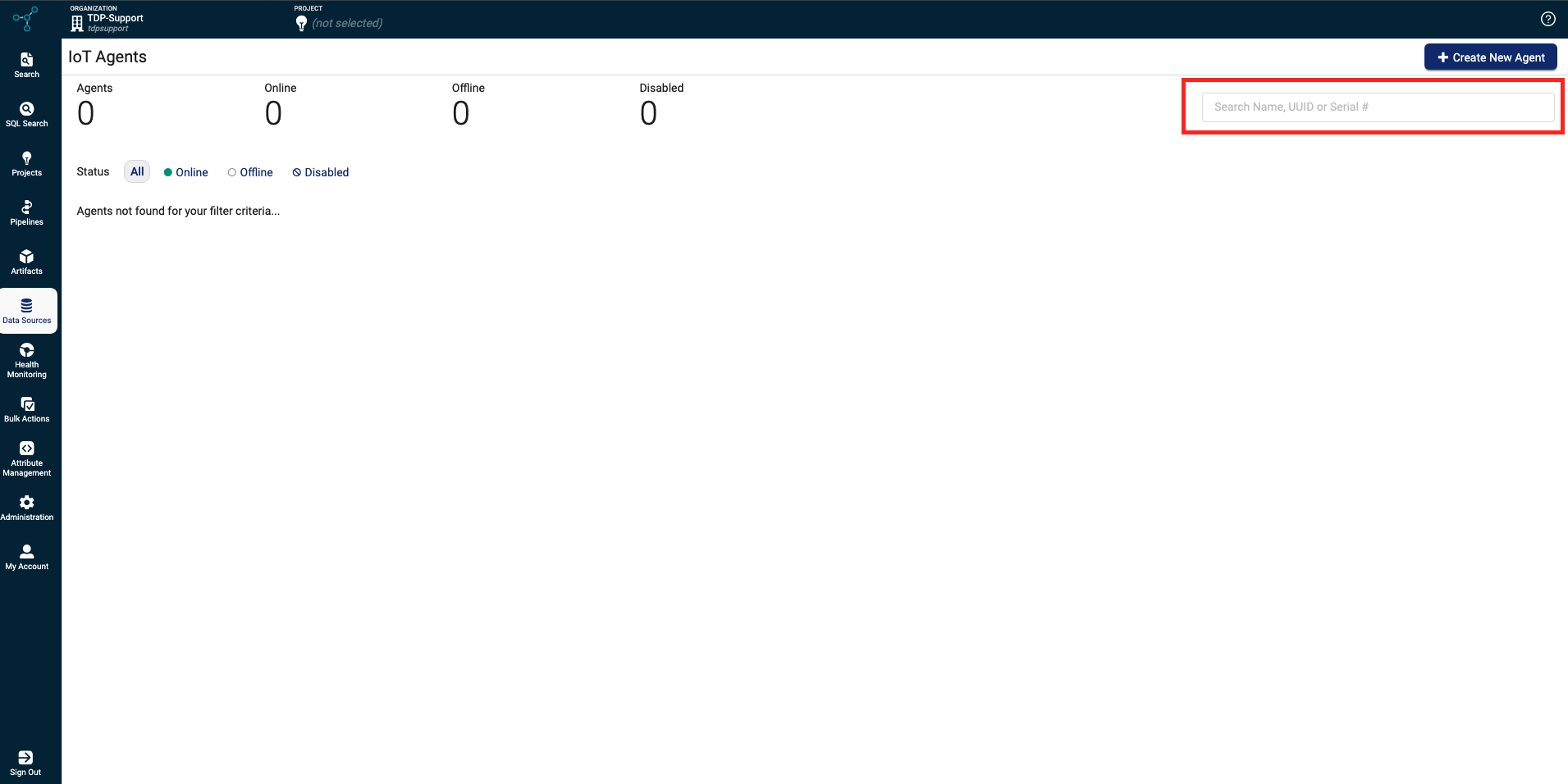
Search Name, UUID or Serial # bar field on the IoT Agents page
Data Harmonization and Engineering
Transform IDS Data Into Lakehouse Tables by Using the New ids-to-delta Protocol
ids-to-delta ProtocolA new ids-to-delta protocol helps customers automatically create open-format Lakehouse tables (Delta Tables) from their Intermediate Data Schema (IDS) data.
To use the new protocol in a pipeline, customers can select the ids-to-delta protocol when creating or editing a pipeline.
For more information, see Convert Tetra Data to Lakehouse Tables.
Data Backfilling
To help customers get the performance benefits of the new Lakehouse architecture faster, TetraScience account teams will work with each customer to backfill their IDS data into Lakehouse tables. These data backfills can be scoped by specific IDSs and historical time ranges as needed.
For more information, see Backfill Historical Data Into Lakehouse Tables.
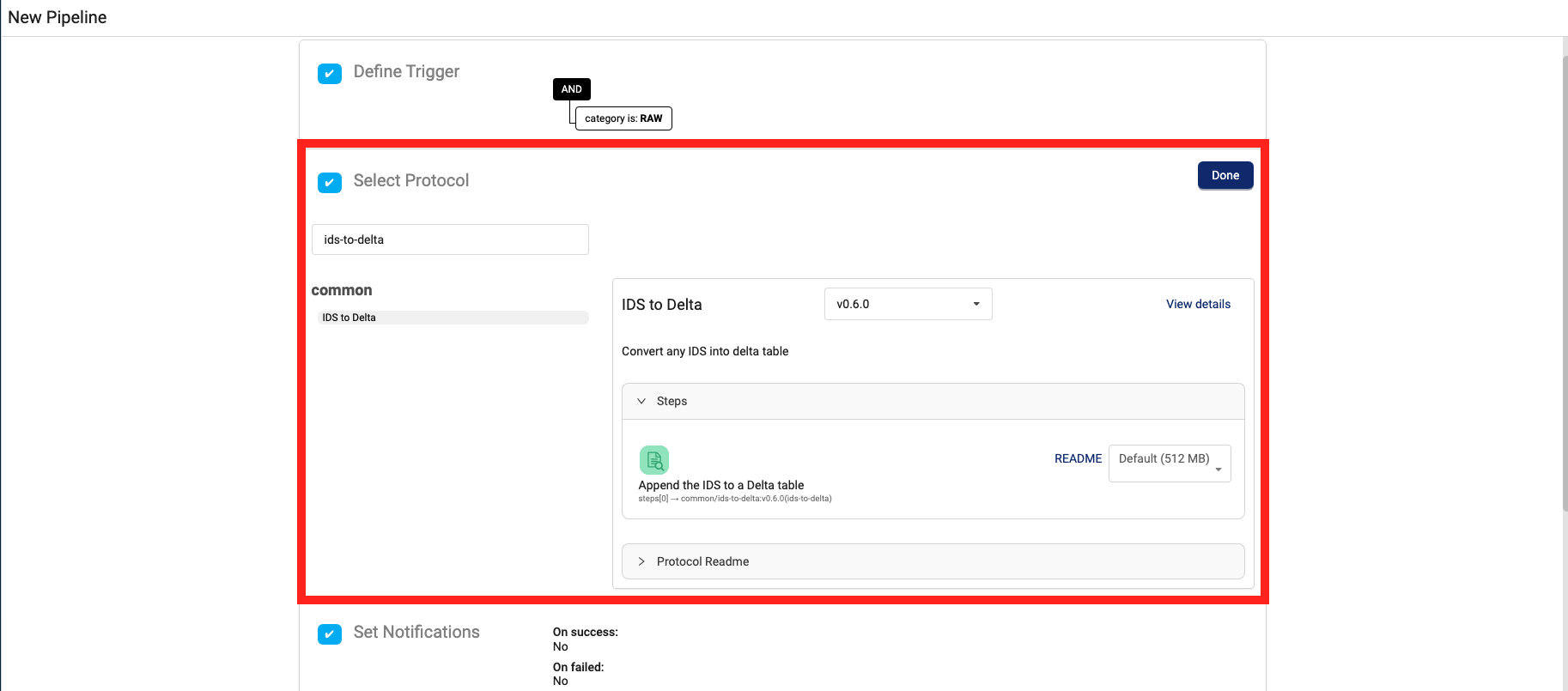
ids-to-delta protocol selection on the New Pipeline page
Define and Schedule Data Transformations by Using a New Tetraflow Pipeline Artifact
The new Tetraflow pipeline artifact allows customers to define and schedule their own data transformations in a familiar SQL language and generate custom, use case-specific Lakehouse tables that are optimized for downstream analytics applications.
To configure a pipeline that uses a Tetraflow, customers can now select Tetraflow from the new Select Pipeline Type dialog that appears when creating a new Tetra Data Pipeline in the TDP. Customers can then select either a Scheduled Trigger to run the pipeline on at specific times, or the legacy File-based trigger type.
For more information, see Transform Tetra Data in the Lakehouse.
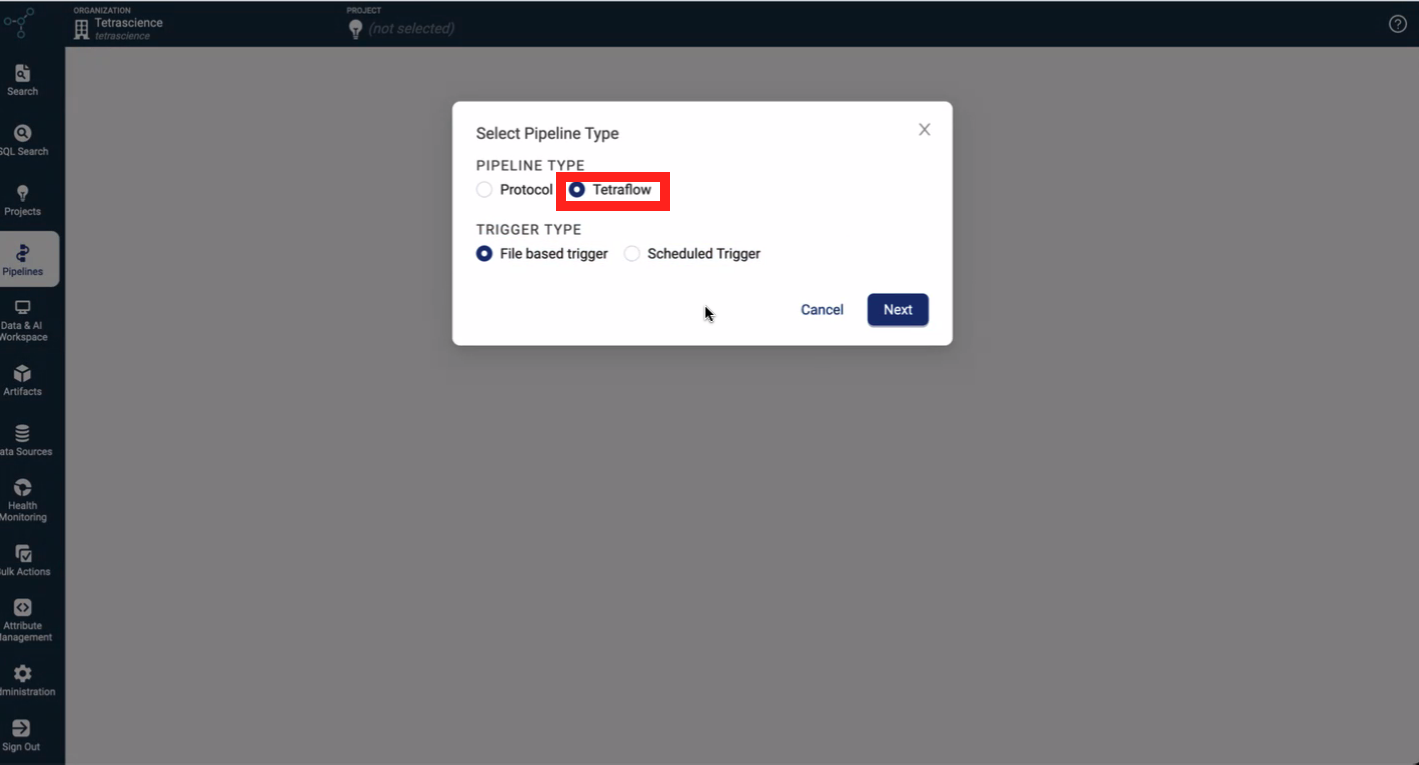
Select Pipeline Type dialog
Monitor Workflows Using the New Workflow Processing Page*
To help make monitoring both scheduled (Tetraflow) and file-based pipeline workflows easier, a new Workflow Processing page shows which pipeline workflows have run in a single dashboard. The workflows are chronologically sorted and can be selected individually to access each workflow’s Workflow Details page.
A new Run Now button was also added that allows customers to manually run their scheduled Tetraflow pipelines and speed up iterative development.
For more information, see Monitor Pipeline File Processing.
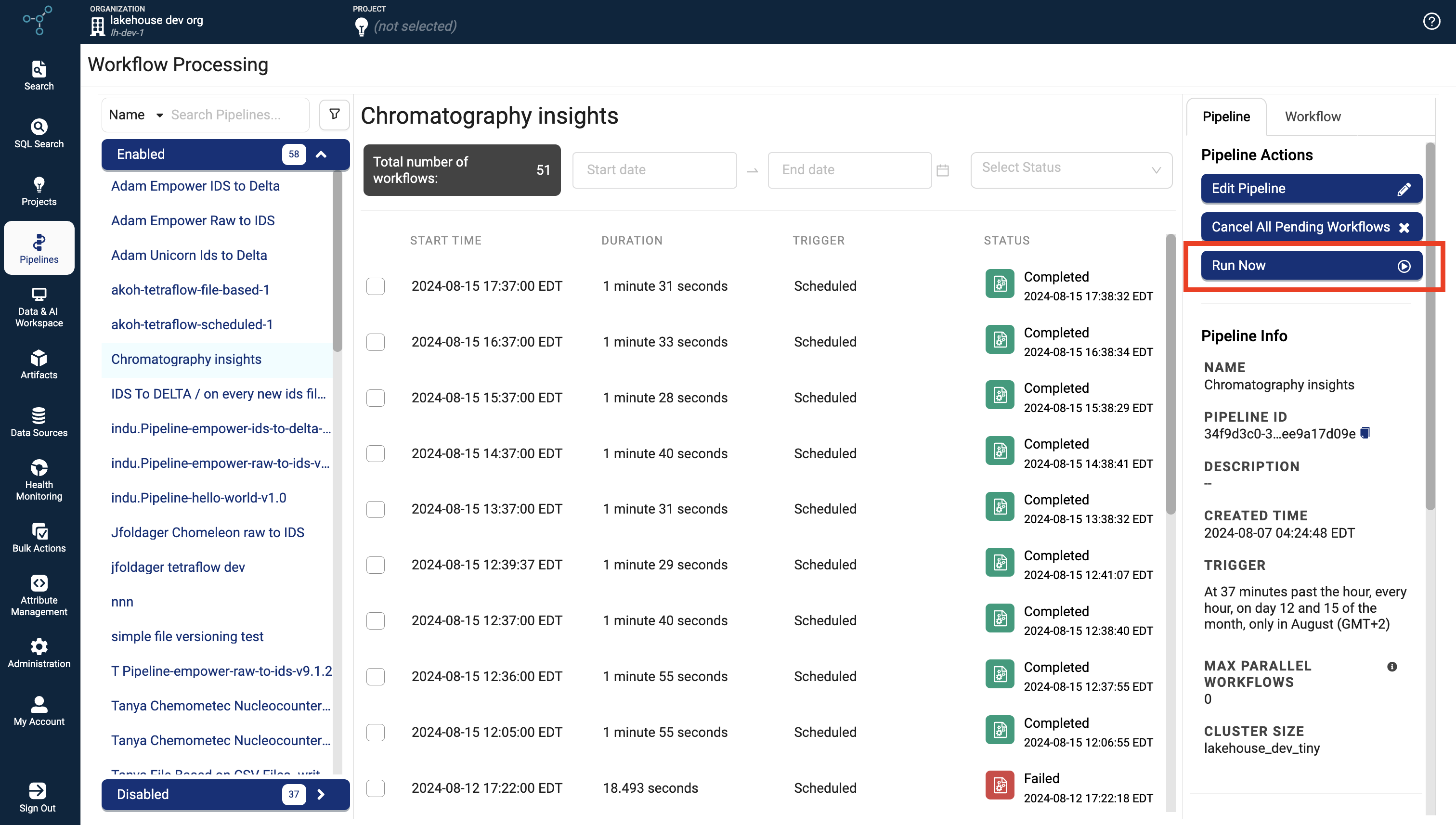
Workflow Processing page
Data Access and Management
Run SQL Queries Against Specific SQL Tables, Including New TDP System Tables
Customers can now query specific SQL tables by using one of the following methods:
- A third-party tool connected to Amazon Athena by using a JDBC or ODBC driver
- A new Database selector on the SQL Search page in the TDP
Queryable Tables
Three types of SQL tables are available to query in TDP v4.1.0:
- Legacy IDS tables
- Lakehouse tables (Delta Tables), which are available through the new Data Lakehouse Architecture (EAP) feature
- TDP System tables, which are part of a new System database that exposes key platform metrics for self-serve analytics on Tetra Integrations and file-based events
For more information, see Query SQL Tables in the TDP.
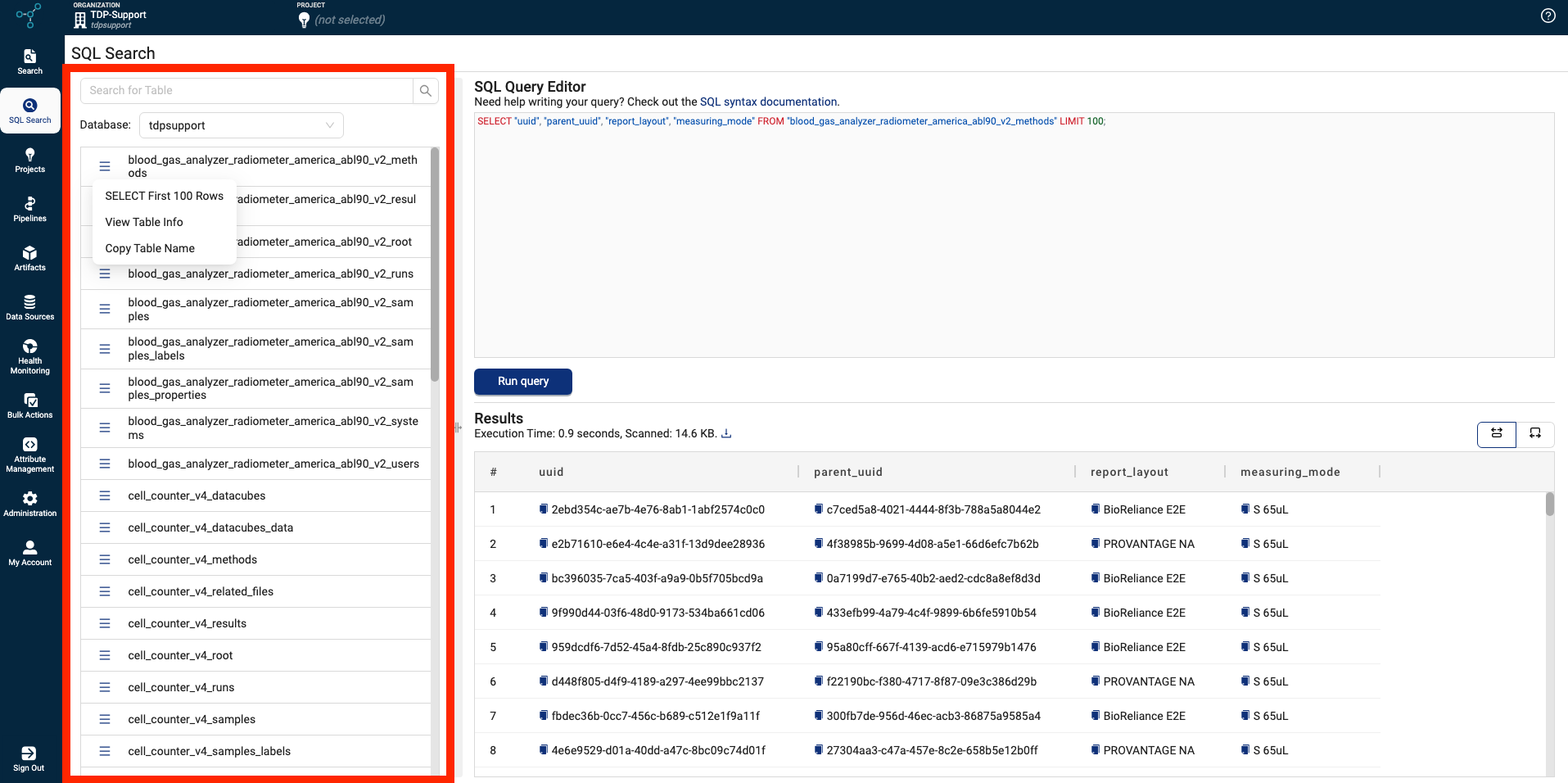
Database selector on the SQL Search page
TDP System Administration
Define Precise User Permissions with Custom Roles
Customers can now configure granular permissions for individual TDP users and groups by using Custom Roles in addition to the three existing platform roles (Administrator, Read Only, and Member).
Custom roles are configured through a combination of Policies based on common TDP user personas and the Functionality access each requires. Organization administrators can create or edit roles assigned one or more policies to make sure that functionality access is limited to only what is necessary for each user’s role through both the TDP user interface and TetraScience API. Users can be assigned either View Access or Full Access to each platform functionality.
For more information, including a complete list of available policies, see Roles and Permissions. To create custom roles, see Create Custom Roles.
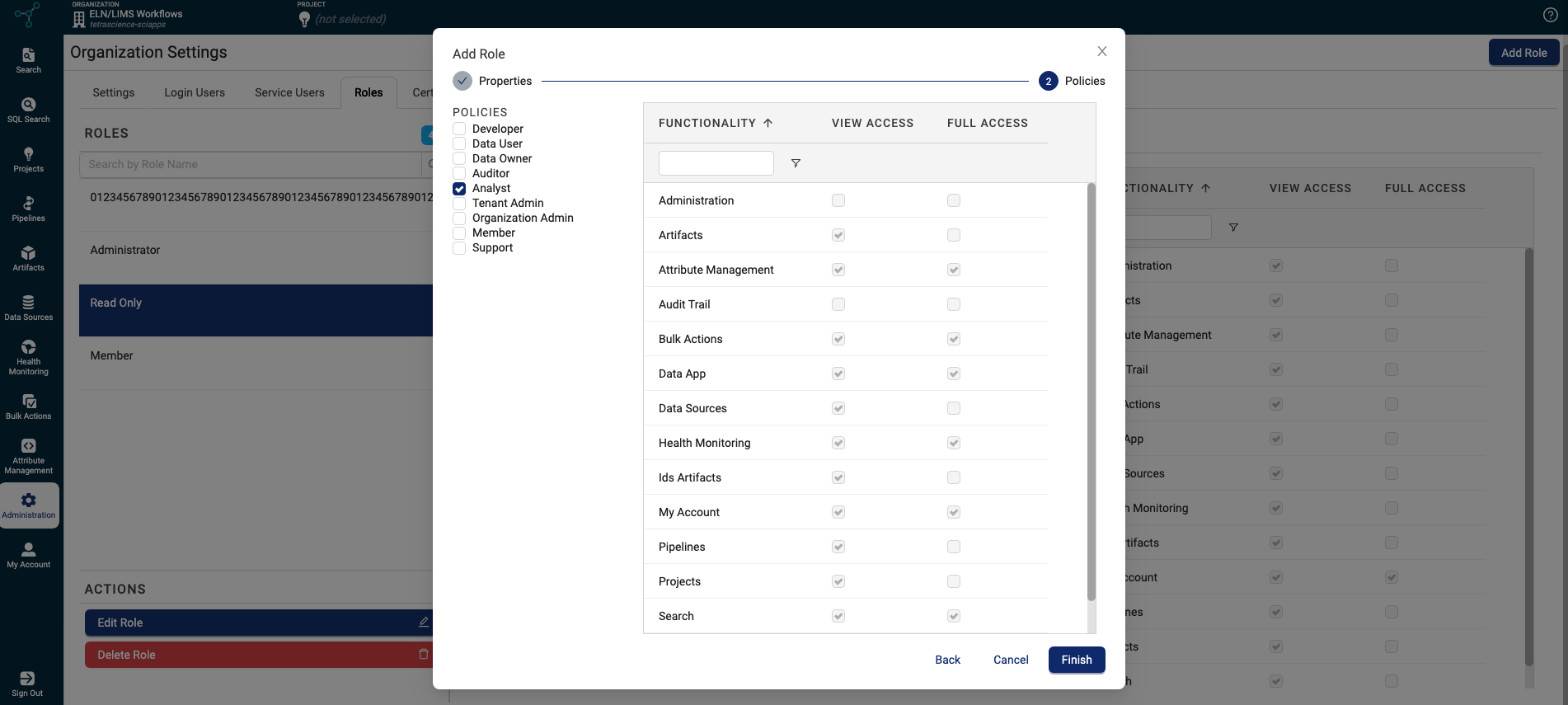
Custom Roles configuration
Support for Multiple Identity Providers*
A single tenant can now support multiple identity providers (IdPs), allowing organizations with different IdPs to collaborate on the same data. This ability reduces the need for additional configuration, users, and administration overhead for companies before integration and better facilitates TetraScience support access.
For more information, see Configure SSO Settings.
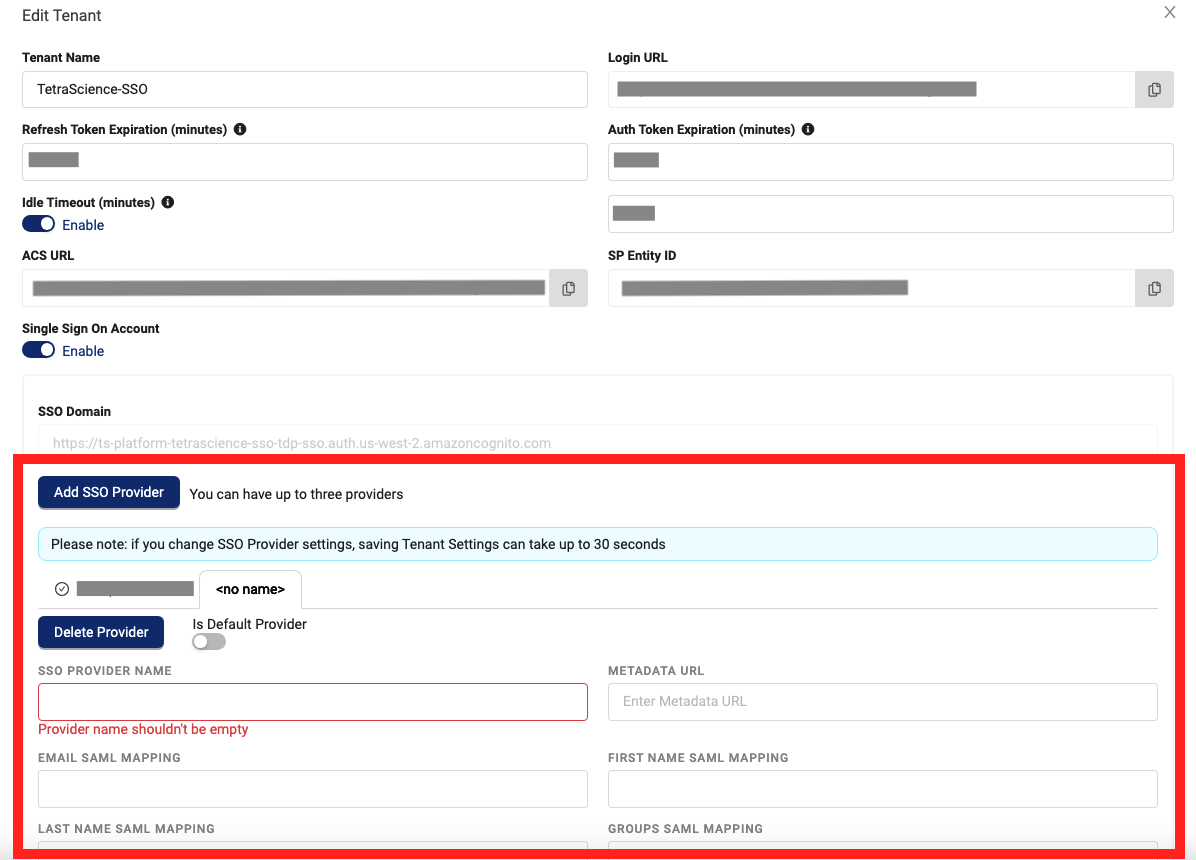
Edit Tenant dialog
Enhancements
Enhancements are modifications to existing functionality that improve performance or usability, but don't alter the function or intended use of the system. The following are new enhancements introduced in TDP v4.1.0.
Data Integrations Enhancements
Improved Data Integrity Checks for Tetra File-Log Agents and Tetra Empower Agents
To provide improved data integrity checks, the TDP now verifies a new checksum value for all files generated by Tetra File-Log Agents and Tetra Empower Agents. This update guarantees that data is recorded exactly as intended and is alway retrievable in its original, RAW format.
As part of this improvement, the following enhancements were also made:
- The Archive files with no checksum setting is no longer an option when configuring file paths for the Tetra File-Log Agent. This option had allowed files to be archived that didn’t have a
checksumin the Agent database, because they had been uploaded by an earlier Agent version originally. Now, files will always have verifiedchecksumvalues calculated, regardless of how they were first uploaded. - For Tetra Agents that have their S3 Direct Upload setting turned off (No), the File Upload (
v1/data-acquisition/agent/upload) API endpoint now does the following:- The endpoint no longer applies the gzip utility to file uploads when the
payloadGzipparameter is set tofalse(the default value). If the parameter is set totrue, the API assumes the payload is already in gzip format and sets Content-Encoding appropriately. - If a
rawMd5CheckSumvalue is passed to the endpoint, the value is now validated against the request payload. The request is rejected if therawMd5CheckSumvalidation fails.
- The endpoint no longer applies the gzip utility to file uploads when the
For more information, see Archive File in the Tetra File-Log Agent Installation Guide (Version 4.3.x).
Set an End Date for Tetra File-Log Agent Path Configurations
Customers can now determine when they want the Tetra File-Log Agent to stop using a specific path configuration by setting an End Date value on the TDP’s Path Configurations page.
For more information, see Configure the Tetra File-Log Agent in the Cloud Configuration Window.
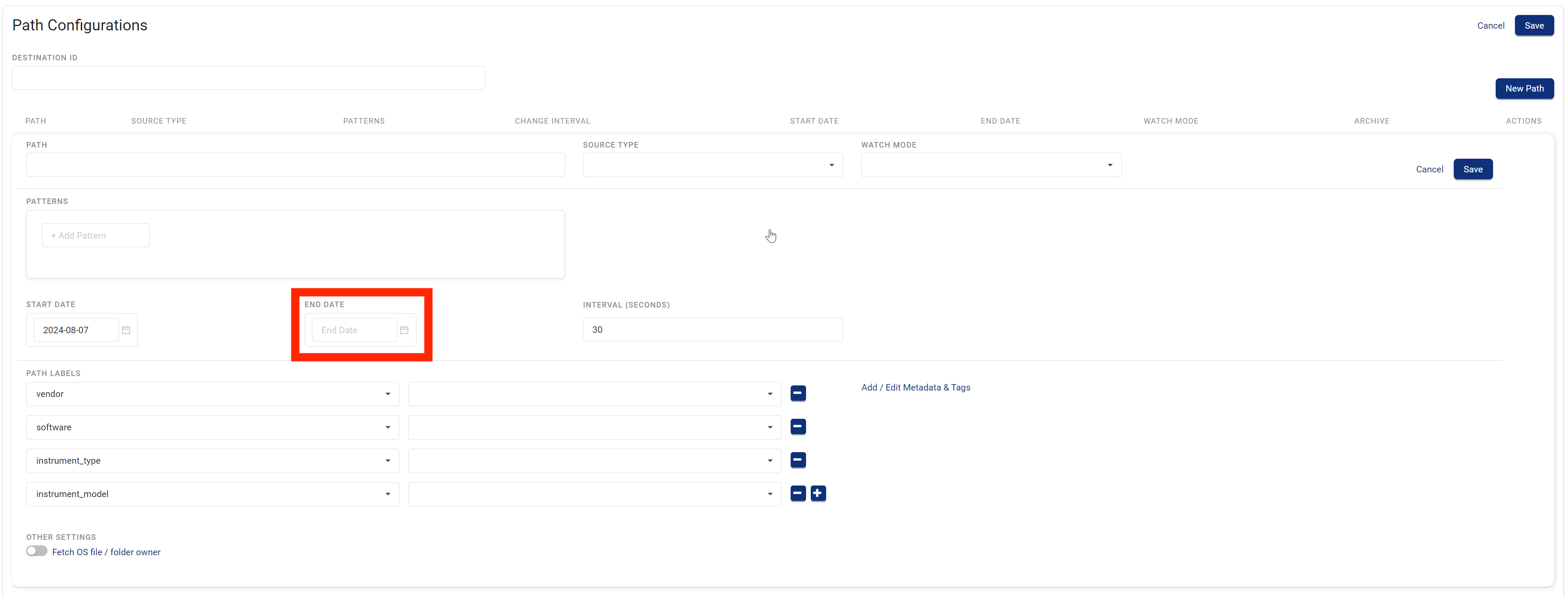
TDP Path Configurations page
Override Tetra Hub Nginx Proxy Settings for Agent Connections
The Tetra Hub’s reverse proxy (Nginx) settings for Agent connections now supports configuration overrides. These optional settings provide greater compatibility for a broader range of networking requirements, such as turning on or off Server Name Identification (SNI).
For more information, see Hub Nginx Proxy Settings.
Data Access and Management Enhancements
File Path Search Filters are Now Case Insensitive by Default
The File Path filter on the Search page is now case insensitive by default. This update makes it so that search results are returned even if they aren’t an exact case match for each character entered in the field.
Customers can still choose to make the File Path filter case sensitive by checking the new Case sensitive check box below the Any path… field in the Filter dialog.
For more information, see More Filter Options.
Browse View on the Search (Classic) Page Now Requires Specific Roles
With the introduction of Custom Roles in TDP v4.1.0, the Browse view on the Search (Classic) page now requires a role assigned at least one of the following policies:
- Administrator
- Developer
- Data Owner
- Member
- Analyst
- Support
For more information, see Browse Files in Folders.
Search Results Exported as CSV Files Now Include Search Terms
To make re-running and sharing searches easier, search results exported as a CSV file now include the search terms that were applied to the search.
For more information, see Download Search Results as a CSV File.
Copy Attribute Values to Your Clipboard from the Search Page
Customers can now copy attribute values to their clipboard by selecting the new copy icon next to the attributes listed for any file on the Search page.
For more information, see View File Information.
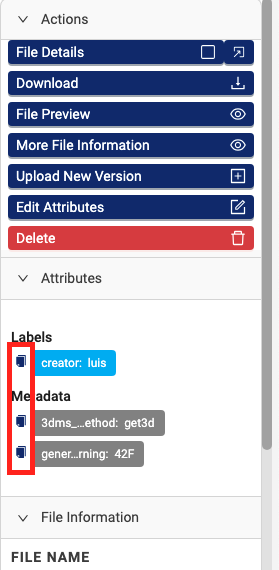
Copy attributes icons
Data harmonization and Engineering Enhancements
Pipelines Now Run On the Latest Versions of a File Only
To help ensure that previous file versions don’t overwrite the latest data in the system, customers can now run pipelines on the latest version of a file only.
If a pipeline tries to process an outdated or deleted file version, the workflow errors out and the TDP now displays the following error message on the Workflow Details page :
Error Message
"message":"file is outdated or deleted so not running workflow"
For more information, see Tetra Data Pipelines.
TDP System Administration Enhancements
New Health Monitoring Dashboard for Tetra Integrations (EAP)
A new Health Monitoring Dashboard v2 early adopter program (EAP) displays detailed observability metrics for Tetra Integrations to help customers better track and troubleshoot data downtime (for example, data ingestion failures or high latency).
Customers can also access the new observability metrics to build their own dashboards in a third-party analytics tool by connecting to the new dashboard’s SQL tables .
The new Health Monitoring v2 dashboard is available to all customers as part of an early adopter program (EAP) currently and will continue to be updated in future TDP releases. If you are interested in participating in the early adopter program, please contact your CSM.
For more information, see Monitor Platform Health.
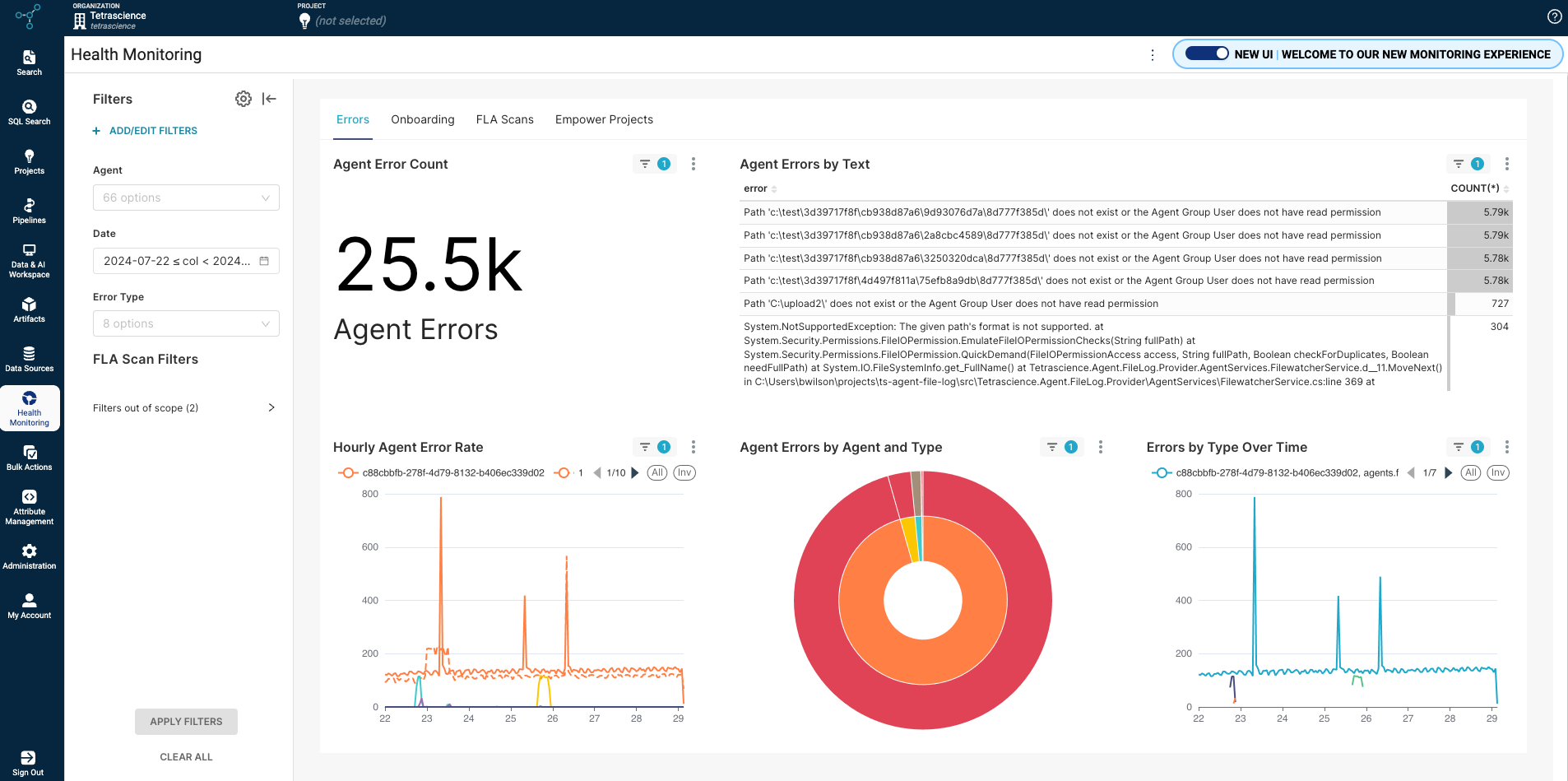
Health Monitoring Dashboard v2 (EAP)
ImportantFor customer-hosted and Tetra-managed deployments, the Health Monitoring Dashboard v2 (EAP) won’t work if the following configurations are not in place:
- The TDP certificate must be valid for
*.data-apps.tdp-hostname.com.- The DNS zone for
tdp-hostname.commust have a CNAME record routing*.data-apps.tdp-hostname.comto thetdp-hostname.comendpoint.Please make sure that you verify these configurations before requesting access to the new dashboard.
Amazon Athena Query Metrics are Now Collected to Help with Troubleshooting
To help speed up the collection of information and resolution of technical issues related to Amazon Athena queries, TDP deployments now send the following configuration and usage information to TetraScience:
- Platform name
- Organization
- Query time
- Data size
- SQL Queries
For more information, see Tetra Phone Home Telemetry.
NoteTetraScience does not automatically pull any proprietary information or data for troubleshooting purposes.
Enhanced Service User Token Management Security for Tetra Agents
To help improve token management security for Tetra Agents, customers can no longer copy over existing service user tokens from the Agent Installation wizard on the Agents page. Instead, users with Administrator permissions can now do either of the following:
-
Add a new service user that has at least a Member or Administrator role. Then, copy the new token and use it in the Agent configuration.
-or-
-
Use a previously generated service user token that’s stored away in a secure password vault.
For more information, see Create a New Agent.
Infrastructure Updates
The following is a summary of the TDP infrastructure changes made in this release. For more information about specific resources, contact your CSM or account manager.
New Resources
- AWS services added: 0
- AWS Identity and Access Management (IAM) roles added: 15
- IAM policies added: 2
- IAM AWS managed policies added: 1
Removed Resources
- IAM roles removed: 1
- IAM policies removed: 0
- IAM AWS managed policies removed: 0
Bug Fixes
The following bugs are now fixed.
Data Integrations Bug Fixes
- The Tetra L7 Proxy Connector now comes back online after the Tetra Data Hub it's configured on is rebooted, without needing to manually sync the Data Hub with the TDP.
Data Access and Management Bug Fixes
- Embedded Data Apps based on Windows are no longer blocked from opening by customers' web browser tracking prevention settings. This issue affected the Tetra FlowJo Data App and Tetra Skyline Data App only and is now resolved.
Deprecated Features
The following feature is now on a deprecation track:
- The existing Health Monitoring dashboard is tentatively planned to be deprecated in TDP v4.3.0 and replaced by the new Health Monitoring Dashboard v2 (EAP). If your organization relies on the existing Health Monitoring dashboard, please contact your customer success manager (CSM) to ensure we’ve migrated all required functionality to the new user interface.
- The existing File Processing page is tentatively planned to be deprecated in TDP v4.3.0 and replaced with a new, consolidated view to capture all data processing observability in one place. The TetraScience Product team will work with customers to make sure that the new experience in TDP v4.3.0 meets customer needs that are currently served by the File Processing page.
For more information about TDP deprecations, see Tetra Product Deprecation Notices .
Known and Possible Issues
Last updated: 18 December 2024
The following are known and possible issues for the TDP v4.1.0 release.
Data Harmonization and Engineering Known Issues
- When configuring a pipeline's RETRY BEHAVIOR settings, customers can select the Always retry 3 times option, but the configuration change won't save. A fix for this issue is in development and testing and is scheduled for TDP v4.2.0. (Updated on 13 December 2024)
- When customers configure custom memory settings for a new Tetra Data Pipeline, the custom options that display in the Default Memory dropdown can't be selected. As a workaround, customers can update the memory settings by editing the pipeline after saving it with the default settings first. A fix for this issue is in development and testing and scheduled for a future TDP release. (Added on 26 September 2024)
- When customers define a Source Type trigger for a new Tetra Data Pipeline, the Pipeline Manager page can sometimes display the following error message: Critical: TDP service have failed to returned required data (Schemas). Please reload the page or contact your administrator for help. To resolve the error, close the Pipeline Manager page. Then, restart the pipeline creation process. The error won't appear again. A fix for this issue is in development and testing and scheduled for a future release. (Added on 3 September 2024)
- File statuses on the File Processing page can sometimes display differently than the statuses shown for the same files on the Pipelines page in the Bulk Processing Job Details dialog. For example, a file with an
Awaiting Processingstatus in the Bulk Processing Job Details dialog can also show aProcessingstatus on the File Processing page. This discrepancy occurs because each file can have different statuses for different backend services, which can then be surfaced in the TDP at different levels of granularity. A fix for this issue is in development and testing. - Logs don’t appear for pipeline workflows that are configured with retry settings until the workflows complete.
- Files with more than 20 associated documents (high-lineage files) do not have their lineage indexed by default. To identify and re-lineage-index any high-lineage files, customers must contact their CSM to run a separate reconciliation job that overrides the default lineage indexing limit.
- OpenSearch index mapping conflicts can occur when a client or private namespace creates a backwards-incompatible data type change. For example: If
doc.myFieldis a string in the common IDS and an object in the non-common IDS, then it will cause an index mapping conflict, because the common and non-common namespace documents are sharing an index. When these mapping conflicts occur, the files aren’t searchable through the TDP UI or API endpoints. As a workaround, customers can either create distinct, non-overlapping version numbers for their non-common IDSs or update the names of those IDSs. - File reprocessing jobs can sometimes show fewer scanned items than expected when either a health check or out-of-memory (OOM) error occurs, but not indicate any errors in the UI. These errors are still logged in Amazon CloudWatch Logs. A fix for this issue is in development and testing.
- File reprocessing jobs can sometimes incorrectly show that a job finished with failures when the job actually retried those failures and then successfully reprocessed them. A fix for this issue is in development and testing.
- On the Pipeline Manager page, pipeline trigger conditions that customers set with a text option must match all of the characters that are entered in the text field. This includes trailing spaces, if there are any.
- File edit and update operations are not supported on metadata and label names (keys) that include special characters. Metadata, tag, and label values can include special characters, but it’s recommended that customers use the approved special characters only. For more information, see Attributes.
- The File Details page sometimes displays an Unknown status for workflows that are either in a Pending or Running status. Output files that are generated by intermediate files within a task script sometimes show an Unknown status, too.
Data Access and Management Known Issues
Last updated: 18 December 2024
-
When customers upload a new file on the Search page by using the Upload File button, the page doesn’t automatically update to include the new file in the search results. As a workaround, customers should refresh the Search page in their web browser after selecting the Upload File button. A fix for this issue is in development and testing and is scheduled for a future TDP release. (Updated on 18 December 2024)
-
In the Filters dialog on the Search page, tag-related filters have two related known issues:
- The Select a filter type dropdown doesn’t provide the option to filter search results by Tags.
- The Tag Name filter’s dropdown doesn’t automatically populate with all of an organization’s available tags.
As a workaround, customers can do the following:
- To search for files with specific tags, customers should enter the exact tag value in the Tag Name filter field. (To retrieve a list of an organization’s existing tags, customers can reference the Tags filter dropdown on the Search (Classic) page.)
- To search for files that exclude specific tags, customers can do either of the following:
- Search by tags on the Search (Classic) page.
- Add the tag to the Tags tab on the Attribute Management page before running the search. This action populates the Select a filter type dropdown with the added tags.
A fix for this issue is in development and testing and is scheduled for a future TDP release. (Issue #3916) (Added on 22 October 2024)
-
Query DSL queries run on indices in an OpenSearch cluster can return partial search results if the query puts too much compute load on the system. This behavior occurs because the OpenSearch
search.default_allow_partial_resultsetting is configured astrueby default. To help avoid this issue, customers should use targeted search indexing best practices to reduce query compute loads. A way to improve visibility into when partial search results are returned is currently in development and testing and scheduled for a future TDP release. -
SQL queries run through the SQL Search page can fail if the size of a single row or its columns exceeds 32 MB. This can occur when IDS tables are converted and flattened into Lakehouse tables (Delta Tables) and is a limitation of the Amazon Athena service. To work around this limitation, customers can modify queries to unnest the data in any columns with more than 32 MB of data.
-
Text within the context of a RAW file that contains escape (
\) or other special characters may not always index completely in OpenSearch. A fix for this issue is in development and testing, and is scheduled for an upcoming release. -
If a data access rule is configured as [label] exists > OR > [same label] does not exist, then no file with the defined label is accessible to the Access Group. A fix for this issue is in development and testing and scheduled for a future TDP release.
-
When using SAVED SEARCHES created with the Search Files page (Search (Classic)) prior to TDP v4.0.0, the new Search page can sometimes appear blank. A fix for this issue is in development and testing and planned for a future TDP release. As a workaround, customers should recreate the saved search by using the new Search page.
-
File events aren’t created for temporary (TMP) files, so they’re not searchable. This behavior can also result in an Unknown state for Workflow and Pipeline views on the File Details page.
-
When customers search for labels in the TDP UI’s search bar that include either @ symbols or some unicode character combinations, not all results are always returned.
-
Customers must click the Apply button after modifying an existing collection of search queries by adding a new filter condition from one of the Options modals (Basic, Attributes, Data (IDS) Filters, or RAW EQL). Otherwise, the previous, existing query is deleted. For more information, see How to Save Collections and Shortcuts.
-
The File Details page displays a
404error if a file version doesn't comply with the configured Data Access Rules for the user.
TDP System Administration Known Issues
- If customers select Save more than once when activating an Embedded Data App, the same data app can be created in their Tetra Data and AI Workspace environment multiple times. A fix for this issue is in development and testing and scheduled for a future TDP release. As a workaround, customers should deactivate the Embedded Data App. Then, activate the app again while selecting Save once only.
- The latest Connector versions incorrectly log the following errors in Amazon CloudWatch Logs:
Error loading organization certificates. Initialization will continue, but untrusted SSL connections will fail.Client is not initialized - certificate array will be empty
These organization certificate errors have no impact and shouldn’t be logged as errors. A fix for this issue is currently in development and testing, and is scheduled for an upcoming release. There is no workaround to prevent Connectors from producing these log messages. To filter out these errors when viewing logs, customers can apply the following CloudWatch Logs Insights query filters when querying log groups. (Issue #2818)
CloudWatch Logs Insights Query Example for Filtering Organization Certificate Errors
fields @timestamp, @message, @logStream, @log | filter message != 'Error loading organization certificates. Initialization will continue, but untrusted SSL connections will fail.' | filter message != 'Client is not initialized - certificate array will be empty' | sort @timestamp desc | limit 20 - If a reconciliation job, bulk edit of labels job, or bulk pipeline processing job is canceled, then the job’s ToDo, Failed, and Completed counts can sometimes display incorrectly.
Upgrade Considerations
IMPORTANTFor customer-hosted deployments where the Tetra Data and AI Workspace is activated, the following services must be allowed in the AWS account that hosts the TDP before upgrading:
During the upgrade, there might be a brief downtime when users won't be able to access the TDP user interface and APIs.
After the upgrade, the TetraScience team verifies that the platform infrastructure is working as expected through a combination of manual and automated tests. If any failures are detected, the issues are immediately addressed, or the release can be rolled back. Customers can also verify that TDP search functionality continues to return expected results, and that their workflows continue to run as expected.
For more information about the release schedule, including the GxP release schedule and timelines, see the Product Release Schedule.
For more details about the timing of the upgrade, customers should contact their CSM.
Other Release Notes
To view other TDP release notes, see Tetra Data Platform Release Notes.
Updated 2 months ago