TDP v4.1.1 Release Notes
Release date: 3 October 2024
TetraScience has released its next version of the Tetra Data Platform (TDP), version 4.1.1. This release introduces important enhancements to the Data Lakehouse Architecture early adopter program (EAP), including a more performant process for backfilling historical Intermediate Data Schema (IDS) data into the new Lakehouse table format, which mirrors the legacy Amazon Athena SQL table structure. It also provides more performant Tetraflow Pipelines and gives system administrators the ability to connect Embedded Data Apps based on Streamlit directly to external systems, such as Databricks and Snowflake.
Here are the details for what’s new in TDP v4.1.1.
SecurityTetraScience continually monitors and tests the TDP codebase to identify potential security issues. Various security updates are applied to the following areas on an ongoing basis:
- Operating systems
- Third-party libraries
Quality ManagementTetraScience is committed to creating quality software. Software is developed and tested following the ISO 9001-certified TetraScience Quality Management System. This system ensures the quality and reliability of TetraScience software while maintaining data integrity and confidentiality.
New Functionality
New functionalities are features that weren’t previously available in the TDP.
GxP Impact AssessmentAll new TDP functionalities go through a GxP impact assessment to determine validation needs for GxP installations. New Functionality items marked with an asterisk (*****) address usability, supportability, or infrastructure issues, and do not affect Intended Use for validation purposes, per this assessment. Enhancements and Bug Fixes do not generally affect Intended Use for validation purposes, and items marked as either beta release or early adopter program (EAP) are not suitable for GxP use.
Beta Release and EAP New Functionalities
The following new functionalities are behind feature flags as either part of a beta release or early adopter program (EAP). To use these new functionalities, contact your customer success manager (CSM) or account executive.
Connect External Systems to Embedded Data Apps Based on Streamlit
Customers can now quickly connect external systems such as Databricks and Snowflake to Embedded Data Apps based on Streamlit by using the new Data App Providers tab in the Tetra Data and AI Workspace. System administrators can use the new tab to provide Data Apps based on Streamlit (for example, the Tetra FPLC Data Explorer) with credentials for accessing any downstream application.
For more information, see Connect External Systems to an Embedded Data App Based on Streamlit.
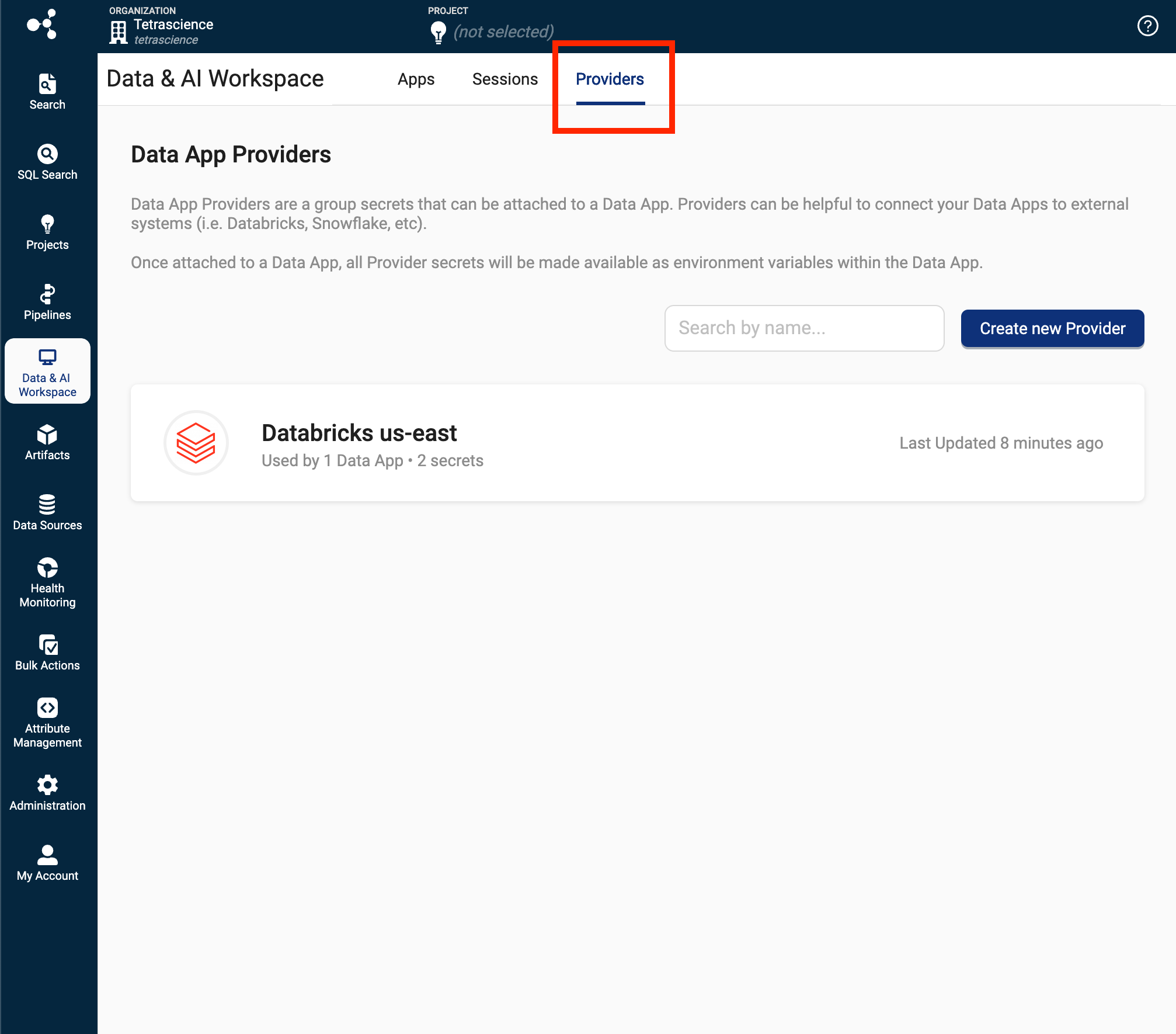
Providers tab
Enhancements
Enhancements are modifications to existing functionality that improve performance or usability, but don't alter the function or intended use of the system.
Beta Release and EAP Feature Enhancements
The following enhancements are behind feature flags as either part of a beta release or early adopter program (EAP). To use these enhancements, contact your customer success manager (CSM) or account executive.
Data Backfill Improvements for the Data Lakehouse Architecture EAP
There’s now an improved process to backfill historical Intermediate Data Schema (IDS) data into Lakehouse tables that mirror the legacy Amazon Athena SQL tables (Normalized IDS Lakehouse Tables). The new data backfill process makes it possible for customers to participate in the Data Lakehouse Architecture early adopter program (EAP) with minimal changes to any downstream queries performed by other applications.
For more information, see Start Using the Data Lakehouse.
Tetraflow Pipelines Now Run on Scheduled Workflows Only
To help optimize pipeline performance for analytics workloads, Tetraflow Pipelines now run on scheduled workflows only.
For more information, see Step 3: Create a Pipeline by Using the Deployed Tetraflow Artifact in Transform Tetra Data in the Lakehouse.
Infrastructure Updates
There are no infrastructure changes in this release.
Bug Fixes
The following bugs are now fixed:
TDP System Administration Bug Fixes
- The Tetra Data and AI Workspace no longer creates multiple versions of the same Embedded Data App if customers select Save more than once when activating an app.
Deprecated Features
There are no new deprecated features in this release.
For more information about TDP deprecations, see Tetra Product Deprecation Notices.
Known and Possible Issues
Last updated: 3 March 2026
The following are known and possible issues for TDP v4.1.1.
Data Harmonization and Engineering Known Issues
- When configuring a pipeline's RETRY BEHAVIOR settings, customers can select the Always retry 3 times option, but the configuration change won't save. A fix for this issue is in development and testing and is scheduled for TDP v4.2.0. (Updated on 13 December 2024)
- When customers configure custom memory settings for a new Tetra Data Pipeline, the custom options that display in the Default Memory dropdown can't be selected. As a workaround, customers can update the memory settings by editing the pipeline after saving it with the default settings first. A fix for this issue is in development and testing and scheduled for a future TDP release.
- When customers define a Source Type trigger for a new Tetra Data Pipeline, the Pipeline Manager page can sometimes display the following error message: Critical: TDP service have failed to returned required data (Schemas). Please reload the page or contact your administrator for help. To resolve the error, close the Pipeline Manager page. Then, restart the pipeline creation process. The error won't appear again. A fix for this issue is in development and testing and scheduled for a future release.
- File statuses on the File Processing page can sometimes display differently than the statuses shown for the same files on the Pipelines page in the Bulk Processing Job Details dialog. For example, a file with an
Awaiting Processingstatus in the Bulk Processing Job Details dialog can also show aProcessingstatus on the File Processing page. This discrepancy occurs because each file can have different statuses for different backend services, which can then be surfaced in the TDP at different levels of granularity. A fix for this issue is in development and testing. - Logs don’t appear for pipeline workflows that are configured with retry settings until the workflows complete.
- Files with more than 20 associated documents (high-lineage files) do not have their lineage indexed by default. To identify and re-lineage-index any high-lineage files, customers must contact their CSM to run a separate reconciliation job that overrides the default lineage indexing limit.
- OpenSearch index mapping conflicts can occur when a client or private namespace creates a backwards-incompatible data type change. For example: If
doc.myFieldis a string in the common IDS and an object in the non-common IDS, then it will cause an index mapping conflict, because the common and non-common namespace documents are sharing an index. When these mapping conflicts occur, the files aren’t searchable through the TDP UI or API endpoints. As a workaround, customers can either create distinct, non-overlapping version numbers for their non-common IDSs or update the names of those IDSs. - File reprocessing jobs can sometimes show fewer scanned items than expected when either a health check or out-of-memory (OOM) error occurs, but not indicate any errors in the UI. These errors are still logged in Amazon CloudWatch Logs. A fix for this issue is in development and testing.
- File reprocessing jobs can sometimes incorrectly show that a job finished with failures when the job actually retried those failures and then successfully reprocessed them. A fix for this issue is in development and testing.
- On the Pipeline Manager page, pipeline trigger conditions that customers set with a text option must match all of the characters that are entered in the text field. This includes trailing spaces, if there are any.
- File edit and update operations are not supported on metadata and label names (keys) that include special characters. Metadata, tag, and label values can include special characters, but it’s recommended that customers use the approved special characters only. For more information, see Attributes.
- The File Details page sometimes displays an Unknown status for workflows that are either in a Pending or Running status. Output files that are generated by intermediate files within a task script sometimes show an Unknown status, too.
Data Access and Management Known Issues
Last updated: 3 March 2026
-
The Download selected files action replaces the following characters with an underscore (
_) if they appear before the file extension in file names:/[/\\:*?<>|.]+/gu;. As a workaround, customers should compare the names of downloaded files against the source file names in the TDP and then rename them if required. A fix for this issue is in development and testing and is scheduled for TDP v4.4.4. (Added on 3 March 2026) -
When customers upload a new file on the Search page by using the Upload File button, the page doesn’t automatically update to include the new file in the search results. As a workaround, customers should refresh the Search page in their web browser after selecting the Upload File button. A fix for this issue is in development and testing and is scheduled for a future TDP release. (Updated on 18 December 2024)
-
In the Filters dialog on the Search page, tag-related filters have two related known issues:
- The Select a filter type dropdown doesn’t provide the option to filter search results by Tags.
- The Tag Name filter’s dropdown doesn’t automatically populate with all of an organization’s available tags.
As a workaround, customers can do the following:
- To search for files with specific tags, customers should enter the exact tag value in the Tag Name filter field. (To retrieve a list of an organization’s existing tags, customers can reference the Tags filter dropdown on the Search (Classic) page.)
- To search for files that exclude specific tags, customers can do either of the following:
- Search by tags on the Search (Classic) page.
- Add the tag to the Tags tab on the Attribute Management page before running the search. This action populates the Select a filter type dropdown with the added tags.
A fix for this issue is in development and testing and is scheduled for a future TDP release. (Issue #3916) (Added on 22 October 2024)
-
Query DSL queries run on indices in an OpenSearch cluster can return partial search results if the query puts too much compute load on the system. This behavior occurs because the OpenSearch
search.default_allow_partial_resultsetting is configured astrueby default. To help avoid this issue, customers should use targeted search indexing best practices to reduce query compute loads. A way to improve visibility into when partial search results are returned is currently in development and testing and scheduled for a future TDP release. -
SQL queries run through the SQL Search page can fail if the size of a single row or its columns exceeds 32 MB. This can occur when IDS tables are converted and flattened into Lakehouse tables (Delta Tables) and is a limitation of the Amazon Athena service. To work around this limitation, customers can modify queries to unnest the data in any columns with more than 32 MB of data.
-
Text within the context of a RAW file that contains escape (
\) or other special characters may not always index completely in OpenSearch. A fix for this issue is in development and testing, and is scheduled for an upcoming release. -
If a data access rule is configured as [label] exists > OR > [same label] does not exist, then no file with the defined label is accessible to the Access Group. A fix for this issue is in development and testing and scheduled for a future TDP release.
-
When using SAVED SEARCHES created with the Search Files page (Search (Classic)) prior to TDP v4.0.0, the new Search page can sometimes appear blank. A fix for this issue is in development and testing and planned for a future TDP release. As a workaround, customers should recreate the saved search by using the new Search page.
-
File events aren’t created for temporary (TMP) files, so they’re not searchable. This behavior can also result in an Unknown state for Workflow and Pipeline views on the File Details page.
-
When customers search for labels in the TDP UI’s search bar that include either @ symbols or some unicode character combinations, not all results are always returned.
-
Customers must click the Apply button after modifying an existing collection of search queries by adding a new filter condition from one of the Options modals (Basic, Attributes, Data (IDS) Filters, or RAW EQL). Otherwise, the previous, existing query is deleted. For more information, see How to Save Collections and Shortcuts.
-
The File Details page displays a
404error if a file version doesn't comply with the configured Data Access Rules for the user.
TDP System Administration Known Issues
- The latest Connector versions incorrectly log the following errors in Amazon CloudWatch Logs:
Error loading organization certificates. Initialization will continue, but untrusted SSL connections will fail.Client is not initialized - certificate array will be empty
These organization certificate errors have no impact and shouldn’t be logged as errors. A fix for this issue is currently in development and testing, and is scheduled for an upcoming release. There is no workaround to prevent Connectors from producing these log messages. To filter out these errors when viewing logs, customers can apply the following CloudWatch Logs Insights query filters when querying log groups. (Issue #2818)
CloudWatch Logs Insights Query Example for Filtering Organization Certificate Errors
fields @timestamp, @message, @logStream, @log | filter message != 'Error loading organization certificates. Initialization will continue, but untrusted SSL connections will fail.' | filter message != 'Client is not initialized - certificate array will be empty' | sort @timestamp desc | limit 20 - If a reconciliation job, bulk edit of labels job, or bulk pipeline processing job is canceled, then the job’s ToDo, Failed, and Completed counts can sometimes display incorrectly.
Upgrade Considerations
During the upgrade, there might be a brief downtime when users won't be able to access the TDP user interface and APIs.
After the upgrade, the TetraScience team verifies that the platform infrastructure is working as expected through a combination of manual and automated tests. If any failures are detected, the issues are immediately addressed, or the release can be rolled back. Customers can also verify that TDP search functionality continues to return expected results, and that their workflows continue to run as expected.
For more information about the release schedule, including the GxP release schedule and timelines, see the Product Release Schedule.
For more details about the timing of the upgrade, customers should contact their CSM.
Other Release Notes
To view other TDP release notes, see Tetra Data Platform Release Notes.
Updated 2 months ago