Product Security
Data
Data-at-Rest Encryption
The files stored within the Data Lake Amazon Simple Storage Service (Amazon S3) bucket are stored encrypted leveraging AWS Key Management Services (KMS) by using 256-bit Advanced Encryption Standard (AES-256). AWS Secrets Manager is leveraged to store credentials for external Application Program Interfaces (APIs) and Amazon Relational Database Service (RDS) access.
Data-in-Transit Encryption
Data in transit is encrypted by using HTTPS, Transport Layer Security (TLS) 1.2, and a 256-bit encryption key.
NOTEFor Tetra Hub network access requirements, see Tetra Hub Allow List Endpoints. For Tetra Data Hub network access requirements, see Tetra Data Hub Allow List Endpoints.
API Authentication and Authorization
The TetraScience API accepts form-encoded request bodies, returns JSON-encoded responses, and uses standard HTTP response codes, JSON Web Token (JWT) authentication, and HTTP methods (verbs).
While some client systems like electronic lab notebooks (ELNs) are browser-based, their integrations with TetraScience APIs typically flow through secure server-side components, not directly from in-browser JavaScript. Enforcing Cross-Origin Resource Sharing (CORS) would block legitimate use cases without improving security. Instead, TetraScience protects its APIs with robust authentication and authorization, which is the industry standard approach.
For more information, see Authentication.
Record Preservation
Data gathered from customers is regulated under 21 CFR Part 11, and should have protection against being altered or deleted.
Application
Validation Controls
All data is validated using standard libraries for parameter validation for specific content. Node.js library secure library is leveraged with buffer size protections, connection attack protection to refuse connections beyond a certain level of load.
Secure Delivery
The Tetra Web Application is configured to use Content Security Policy to ensure only trusted javascript is loaded.
HTTP security headers are enabled: Strict-Transport-Security to enforce the use of HTTPS; X-Frame-Options is set to deny so that the web application cannot be loaded in a frame for another website; and X-Content-Type-Operations is set to ‘nosniff’ to declare the browser should not change the declared content type.
Penetration Testing
TetraScience engages an independent, outside party to perform penetration testing on the TDP annually.
Vulnerability Management
Packaged code is automatically scanned for vulnerabilities, with any high or critical vulnerabilities remediated, before being released.
Cloud Infrastructure
AWS Services
Security tooling is leveraged to assess, audit, and evaluate the configurations of various AWS services. Amazon Virtual Private Cloud (VPC) endpoints are used to establish communication with supported AWS services. Authentication is managed by AWS Identity and Access Management (IAM) roles and credentials with least privilege considered for each role that gets assigned to the services.
Amazon Elastic Container Registry (Amazon ECR) is not accessible publicly. The container images uploaded are scanned with Amazon ECR Image Scanning with any high or critical vulnerabilities remediated before the container image is published.
TetraScience primarily uses AWS Fargate for compute with one notable exception: Windows worker EC2 nodes for C# task scripts. In this case, TetraScience leverages AWS security best practices in using an AWS Windows
Amazon Machine Image (AMI). TetraScience created an AWS Lambda function to continually poll AWS for a new Windows AMI. Upon receiving notice of a new AMI, TetraScience deploys the latest version.
Compute Isolation
TetraScience uses multiple compute environments, each of which provides strong isolation at the kernel level.
AWS Serverless Services
Pipelines, task scripts, and Tetra Data Apps run on AWS Fargate and AWS Lambda. These services use the AWS Firecracker microVM architecture, which provides each compute instance (for example, each container task or Lambda function invocation) with its own dedicated kernel.
Databricks Runtime
Tetraflows and AI Assistants run on Amazon Elastic Compute Cloud (Amazon EC2) instances that use Amazon Machine Images (AMIs) provided by Databricks. The Databricks Runtime uses gVisor, a container isolation tool that provides each workload with its own isolated kernel boundary, similar to the Firecracker architecture. This significantly reduces the impact of Linux kernel vulnerabilities on these workloads.
Windows Workers
Windows workers run on EC2 instances that use the Windows operating system. These instances are short-lived and are automatically kept up-to-date.
Identity and Access Control
Single Sign-on (SSO)
The TDP web interface can leverage identity providers (IdPs) that comply with the industry-standard SAML 2.0 protocol. AWS Cognito is leveraged to integrate with the Identity Provider.
Tetra Data Platform does not store SSO credentials in the platform. TDP redirects authentication to Cognito which in turn redirects to your identity provider. TDP only stores email and ID.
Customer responsibility: TetraScience strongly suggests our customers having Multi-Factor Authentication (MFA) as part of their SSO strategy.
Least Privilege Access
Authorization is accomplished using role based account access using the user’s attributes, managed and controlled with federated SSO.
During deployment, full AWS admin privileges are required for the user performing the deployment, and refer only to the services used by the platform.
All platform components have restrictive roles with the least level of privileges required to perform their functions.
Password Management
When SSO is not used, the TDP stores passwords in a SQL database using one-way (non-reversible) cryptographic hashing with a unique salt for each user.
One more area that passwords are stored is in the TDP Agent when using remote SMB file sharing to collect a file. The Agent stores the password using SHA-256 with a protected key.
Product Delivery Process
Peer Code Review
Code commits to the product are reviewed by peer engineers for quality assurance and security reviews.
Security Design Reviews
Major product changes and new features undergo specialized security reviews and risk assessment by qualified personnel early in the design phase, and as required throughout implementation.
Software Development Lifecycle
Any new software development, including features and bug fixes, go through TetraScience’s software development lifecycle (SDLC) process. The SDLC consists of five iterative phases, during which features are designed, implemented, and deployed. These phases include Planning, Design & Development, Testing, Deployment, and Operation & Maintenance.
The following diagram shows an example TDP SDLC workflow:
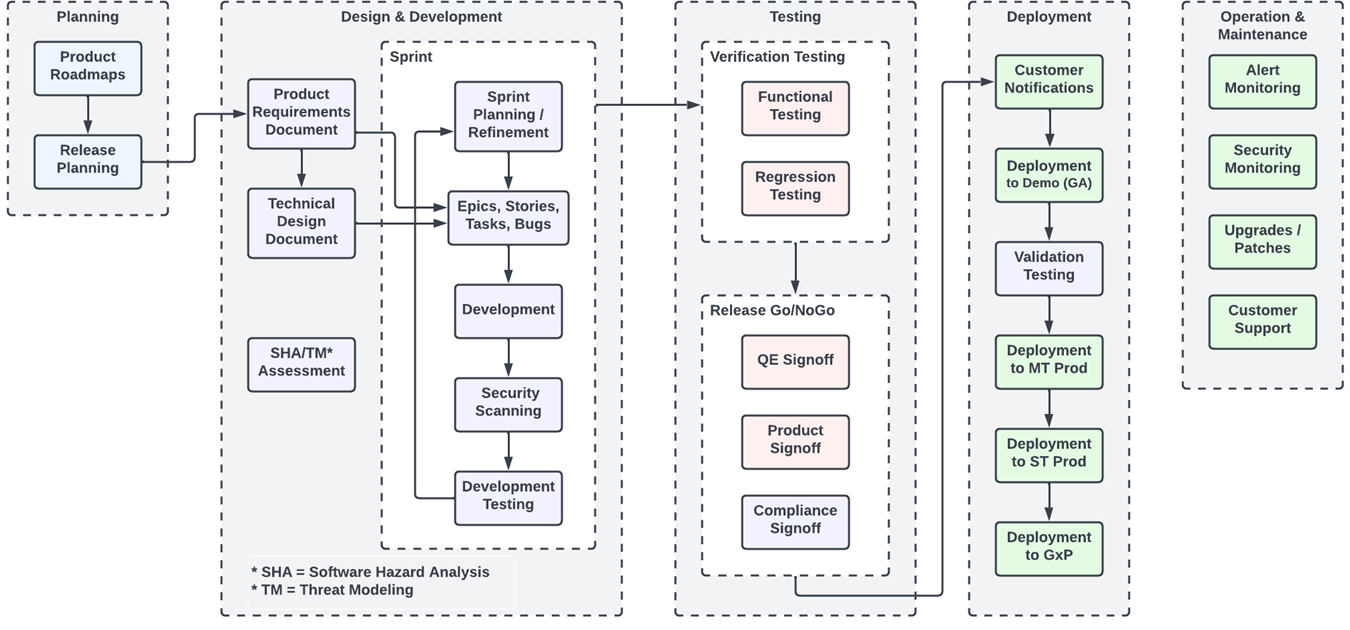
The diagram shows the following process:
-
For the Planning phase, product managers talk to customers to discover the requirements for new product updates and document their learnings. TetraScience maintains a six-quarter product roadmap that is updated quarterly. Then, the requirements are reviewed and prioritized as part of release planning.
-
During the Design & Development stage, user stories based on the high-level requirements identified during the Planning phase are documented. The detailed requirements are defined in this Design phase to a level of detail sufficient for systems development and testing to proceed. The applicable systems, software, and applications are then designed to satisfy the requirements identified. The following steps occur during the Design & Development phase:
- Product requirements
- Software hazard Analysis (SHA)
- Technical design
- Sprint planning and refinement
- Security and threat modeling
- Development and development testing
- Code review
- Security assessment
-
For Testing, various types of testing is performed on the system pre-release. The following steps occur during the Testing phase:
- Test cases
- Functional testing
- Regression testing
- Review and sign off
-
During Deployment, the product is deployed to the Cloud and made available to customers.
-
The Operation and Maintenance phase continues for the life of the system, and involves TetraScience continuously monitoring the system to maintain its performance in accordance with defined user requirements.
Quality Control Process
TetraScience performs continuous Quality Control as part of the overall development process, including leveraging a variety of automated testing practices (e.g.: unit tests) to ensure the software runs as expected and bugs are not reintroduced (e.g.: regression tests).
Monitoring
Active logging and monitoring is implemented using AWS CloudTrail and CloudWatch for the infrastructure. The Tetra Data Platform has audit logging enabled for user actions and logs are available for analysis through CloudWatch alerts.
Business Operations Process
Availability and Resilience
Each Tetra Data Platform (TDP) environment runs in a specific AWS Region, but is highly redundant because each Region has multiple, isolated locations known as Availability Zones (AZ). Because of this underlying infrastructure, the platform will continue to operate as normal if a platform component in one AZ goes down, or if an entire AZ fails.
For more information, see TDP Availability and Resilience.
Disaster Recovery
To preserve data and restore service following a catastrophic event that renders a TDP production site inoperable, TetraScience creates disaster recovery sites (DR sites) in a second AWS Region in a different geography (DR Region) for each Tetra hosted deployment. All data within each TDP environment, including all user files and platform state, is replicated to the DR Region.
For deployments in the European Union (EU), data is not replicated in AWS Regions outside of the EU. For US deployments, data is not replicated in Regions outside of the United States.
For more information, see Disaster Recovery.
Security Incident Management
Incident management responsibilities and procedures which cover all TetraScience services must be established and documented. These Incident Management Practices and Procedures are to ensure incidents can be resolved as quickly as possible, and business impacts are minimized. All third parties upon which TetraScience is dependent for the delivery of services and business continuity (for example, cloud service providers) must have acceptable incident management procedures in place. At a minimum, the incident management procedures should include the following:
- A notification process
- Security incident data collection and analysis processes
- Security incident documentation requirements
- Internal and external communication requirements
- Response action procedures
- A process for post-mortem analysis
- A process to review the sufficiency of controls and corrective actions.
All information gathered during incident and malfunction remediation activities are to be treated as TetraScience confidential information in accordance with Data Classification and Handling policies.
Documentation Feedback
Do you have questions about our documentation or suggestions for how we can improve it? Start a discussion in TetraConnect Hub. For access, see Access the TetraConnect Hub.
NOTEFeedback isn't part of the official TetraScience product documentation. TetraScience doesn't warrant or make any guarantees about the feedback provided, including its accuracy, relevance, or reliability. All feedback is subject to the terms set forth in the TetraConnect Hub Community Guidelines.
Updated 2 months ago