Create Lakehouse Tables
To automatically create open-format Lakehouse tables from your data that's coming into the Tetra Data Platform (TDP), use one of the following protocols in a Tetra Data Pipeline:
To Convert Tetra Data (IDS Data) in the TDP to Lakehouse Tables
To Convert Structured Data Outside of the TDP to Lakehouse Tables
After you enable the pipeline, any data that meets the trigger conditions you set is automatically converted into Lakehouse tables.
IMPORTANTWhen configuring
ids-to-lakehouseanddirect-to-lakehousepipelines, make sure that you select the Run on Deleted Files checkbox on the pipeline configuration page. This setting ensures that any upstream file delete events are accurately propagated to the downstream Lakehouse tables.
To backfill historical Tetra Data into Lakehouse tables, create a Bulk Pipeline Process Job that uses an ids-to-lakehouse pipeline and is scoped by the appropriate IDSs and historical time ranges.
What Happens Next
After your data is converted to Lakehouse tables, you can then transform and run SQL queries on the data in the Lakehouse by using any of the following methods:
- A third-party tool and a Java Database Connectivity (JDBC) or Open Database Connectivity (ODBC) driver endpoint
- The TDP user interface
- Databricks Delta Sharing
- Snowflake Data Sharing
You can also use Tetraflow pipelines to define and schedule data transformations in a familiar SQL language and generate custom, use case-specific Lakehouse tables that are optimized for downstream analytics applications.
To view Lakehouse tables after you create them, see Query SQL Tables in the TDP. For best practices on querying data in the Lakehouse, see Query Lakehouse Tables.
Create an ids-to-lakehouse Pipeline
ids-to-lakehouse PipelineTo create an ids-to-lakehouse pipeline that converts Tetra Data (IDS data) in the TDP to Lakehouse Tables, do the following:
-
On the Pipeline Manager page, create a new pipeline and define its trigger conditions by selecting the IDS data that you want to transform to Lakehouse tables. You can do either of the following:
- To convert all of your IDS data to Lakehouse tables, select File Category > is > IDS to create the trigger. This is the default protocol configuration and is best for when your data latency requirements are similar across all of your datasets.
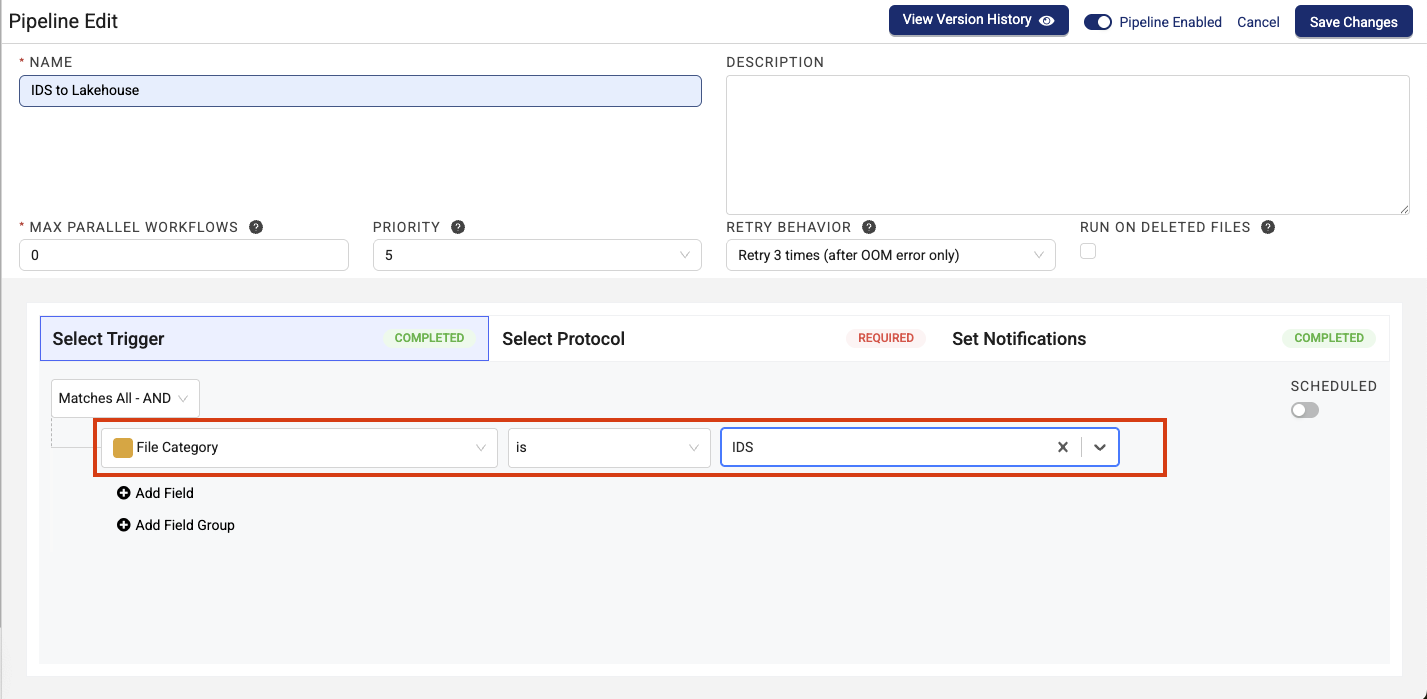
- or -
- To convert IDS data from a specific source, select IDS Type > is > then, select the specific IDS name to create the trigger. This approach is best for when a specific dataset has different latency needs than your other datasets.
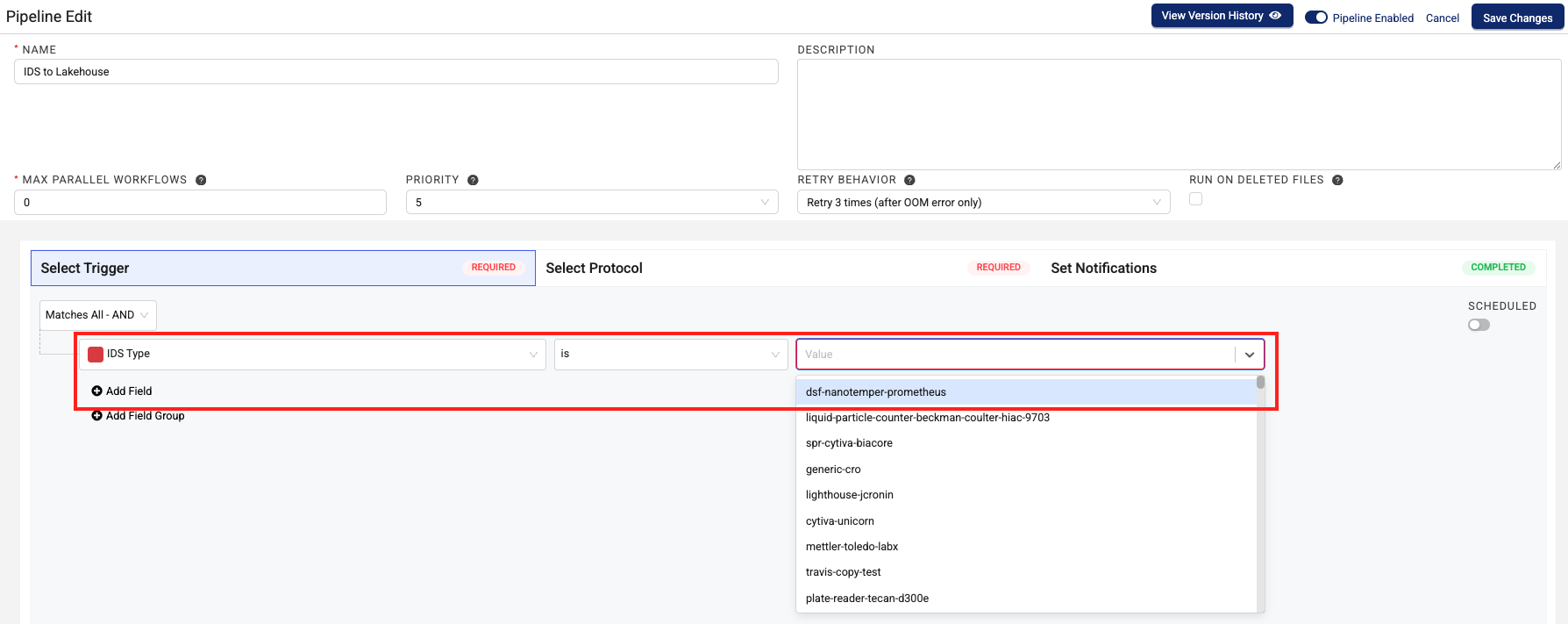
-
Click on Select Protocol.
-
In the Select Protocol section, select the latest version of the
ids-to-lakehouseprotocol. Don't change the protocol's default Configuration settings, unless you want to create Normalized IDS tables (see step 6). -
For Cluster Sizing, select the size of the compute cluster that you want the TDP to use for this pipeline. Starting in TDP v4.5.3, a default all-purpose compute cluster is pre-selected for all
ids-to-lakehousejobs. For most use cases, the default cluster size is appropriate. Choose a larger cluster size only if your pipeline processes large volumes of data or requires lower latency.IMPORTANTThe cluster size selections available in
ids-to-lakehousev1.2.0 and later are only available in TDP v4.5.0 and later. -
(Optional) To have your pipeline transform Lakehouse tables from the new, nested Delta Table structure to a normalized structure that mirrors the legacy Amazon Athena table structure, you can enable the normalizedIdsEnabled and/or the normalizedDatacubesEnabled in the Configuration section. Then, configure the Normalized IDS Frequency and/or Normalized Datacubes Frequency fields to determine how often the normalized tables are updated. Use the Cluster Size settings for each option to define the size of the cluster that you want the TDP to spin up to run the normalization. For more information, see Working with Normalized Lakehouse Tables.
IMPORTANTCreating normalized Lakehouse tables introduces higher data processing costs and latency (minimum 20 minutes) than the default nested Lakehouse Tables.
-
Select the RUN ON DELETED FILES checkbox. This setting ensures that any upstream file delete events are accurately propagated to the downstream Lakehouse tables.
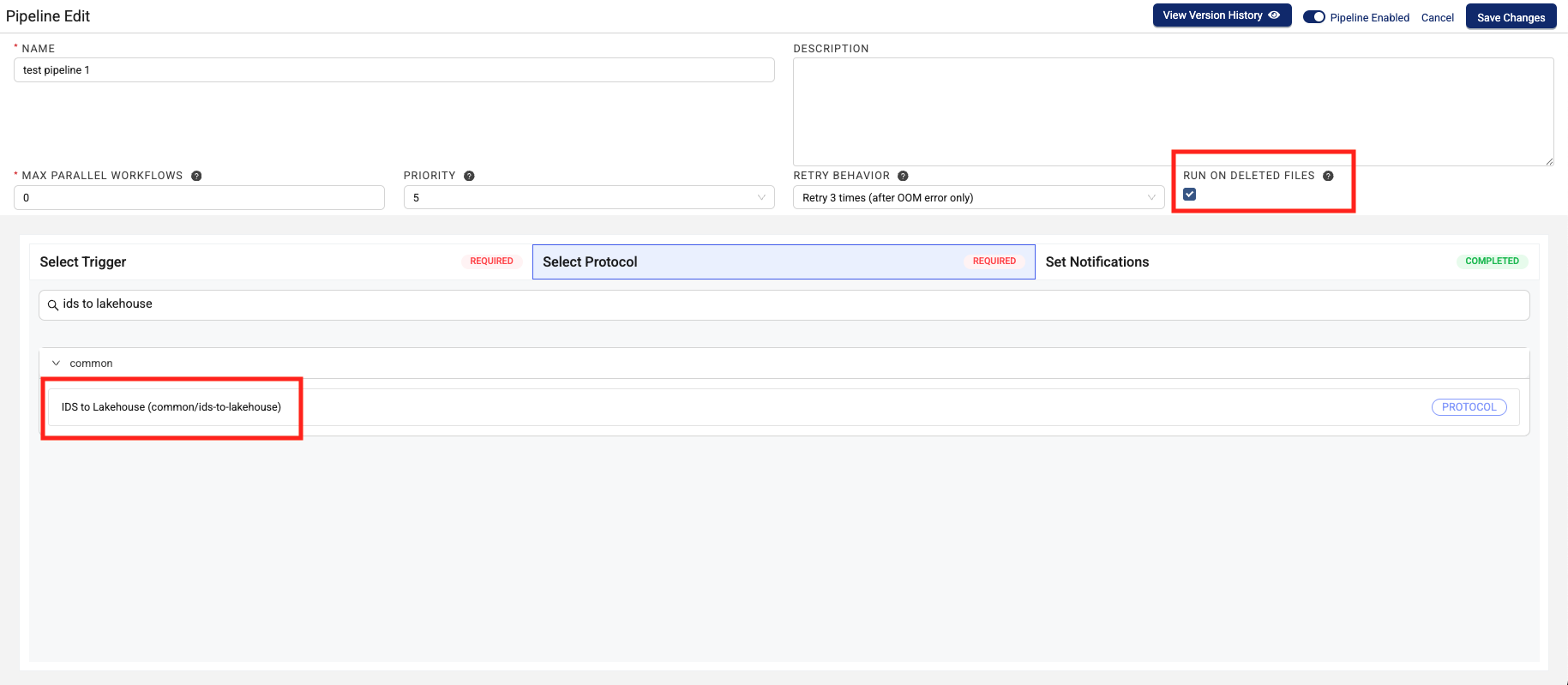
- (Optional) Set email notifications for successful and failed pipeline executions.
- Choose Save Changes.
NOTEIf the Pipeline Enabled toggle is set to active when you choose Save Changes, then the pipeline will run as soon as the configured trigger conditions are met.
For more information about configuring pipelines, see Set Up and Edit a Pipeline.
Create a direct-to-lakehouse Pipeline
direct-to-lakehouse PipelineTo create a direct-to-lakehouse pipeline that converts structured data outside of the TDP to Lakehouse Tables, do the following:
- Sign in to the Tetra Data Platform (TDP).
- On the Pipeline Manager page, create a new pipeline and define its trigger conditions by doing the following:
- Choose Select Trigger.
- From the left menu, select Source Type. Then, in the middle menu, select is.
- In the right menu, select your data source.
- (Optional) To add another condition to your trigger, choose Add Field. Or, to nest another trigger condition, choose Add Field Group. For more information about how to configure triggers, see Select Trigger Conditions.
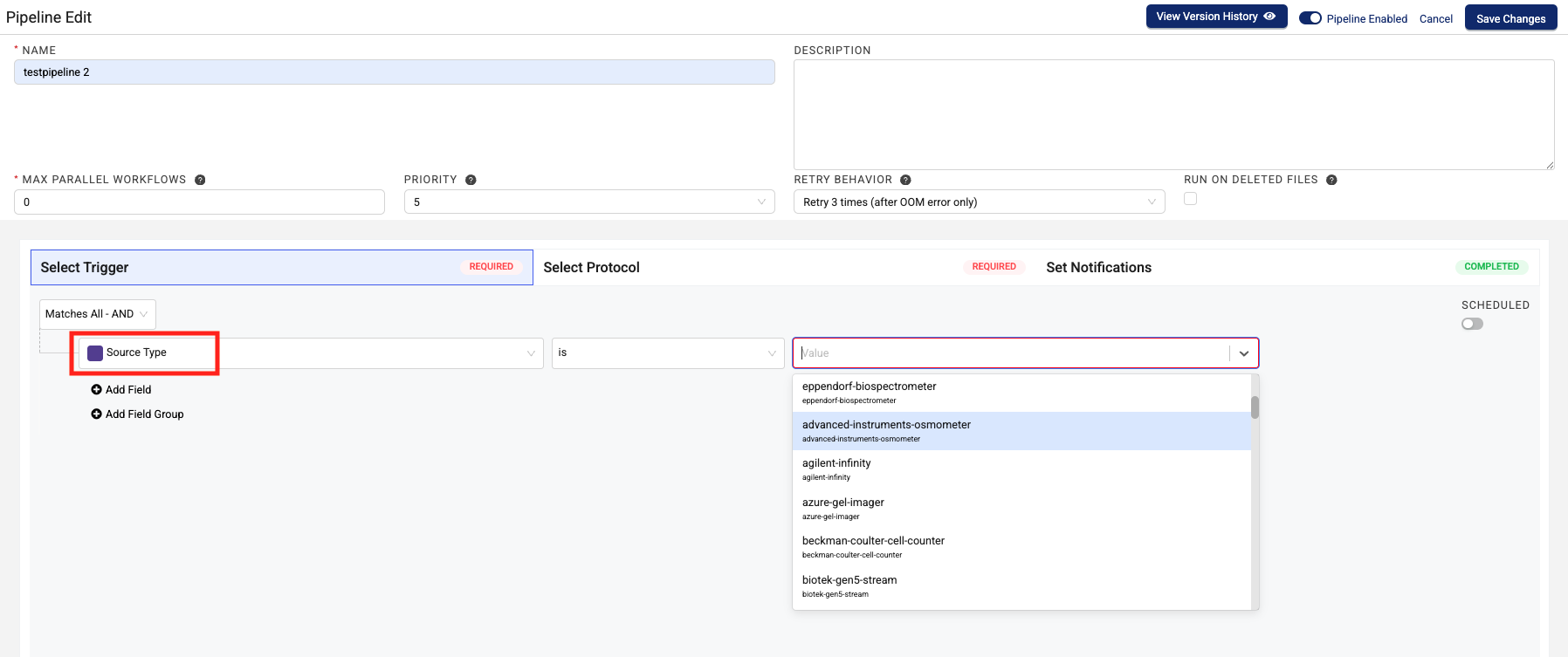
- Click on Select Protocol.
- In the Select Protocol section, select the latest version of the
direct-to-lakehouseprotocol.
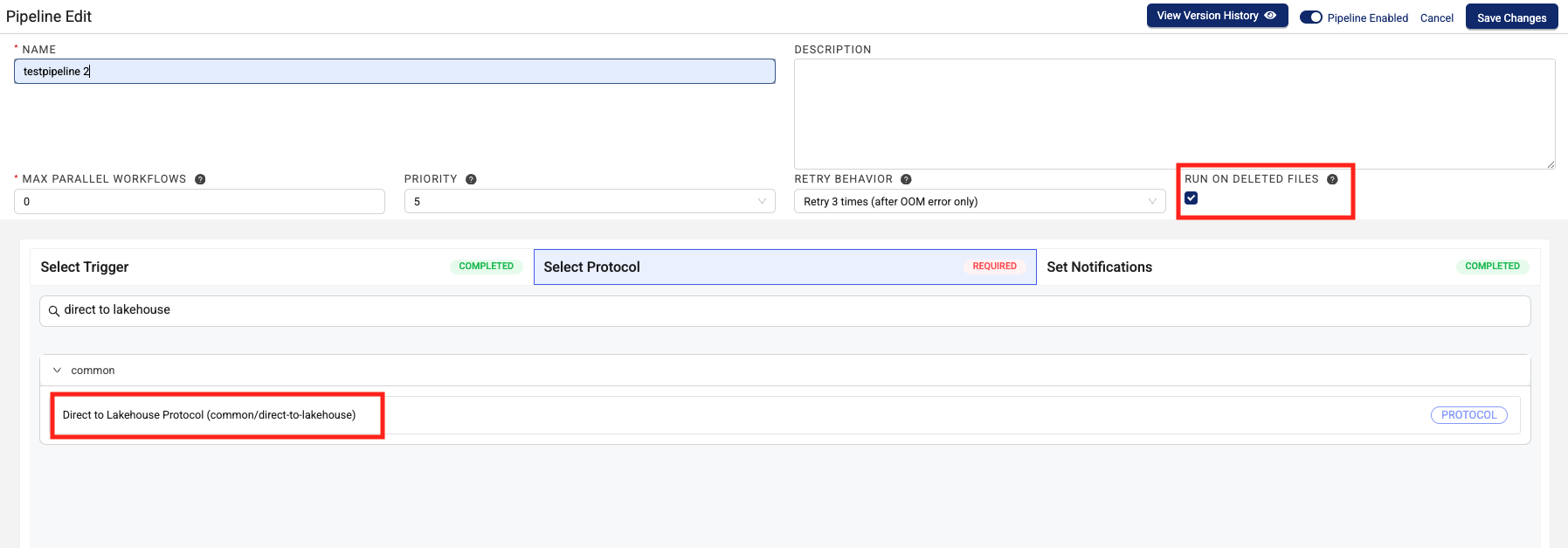
-
Select the RUN ON DELETED FILES checkbox. This setting ensures that any upstream file delete events are accurately propagated to the downstream Lakehouse tables.
-
In the Configuration section, do the following:
IMPORTANTDon't configure Advanced Settings fields without coordinating with TetraScience. These settings are for fine-tuning latency-sensitive or large-scale processing use cases.
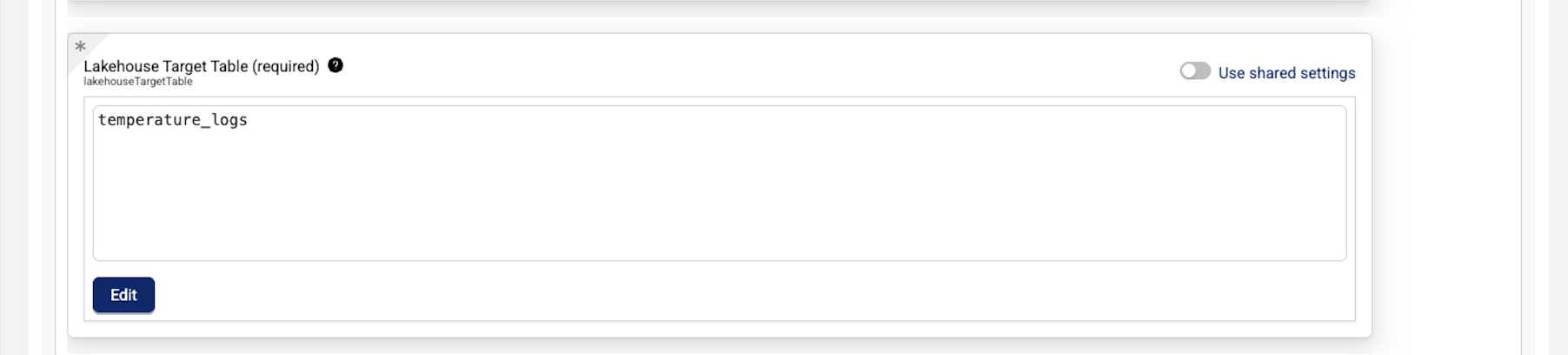
- For Lakehouse Target Table (required), enter the name of your destination table in the Data Lakehouse.
- For Transform SQL Query (required), enter an SQL query that uses DuckDB dialect to transform the input data. Make sure that the query references the input file in the following format:
{{ env_var("S3_INPUT_PATH") }}
Transform SQL Query Example
SELECT
id,
name,
UPPER(name) as name_upper,
created_at,
CASE
WHEN status = 'active' THEN 1
ELSE 0
END as is_active,
temperature_celsius,
temperature_celsius * 9.0 / 5.0 + 32.0 as temperature_fahrenheit
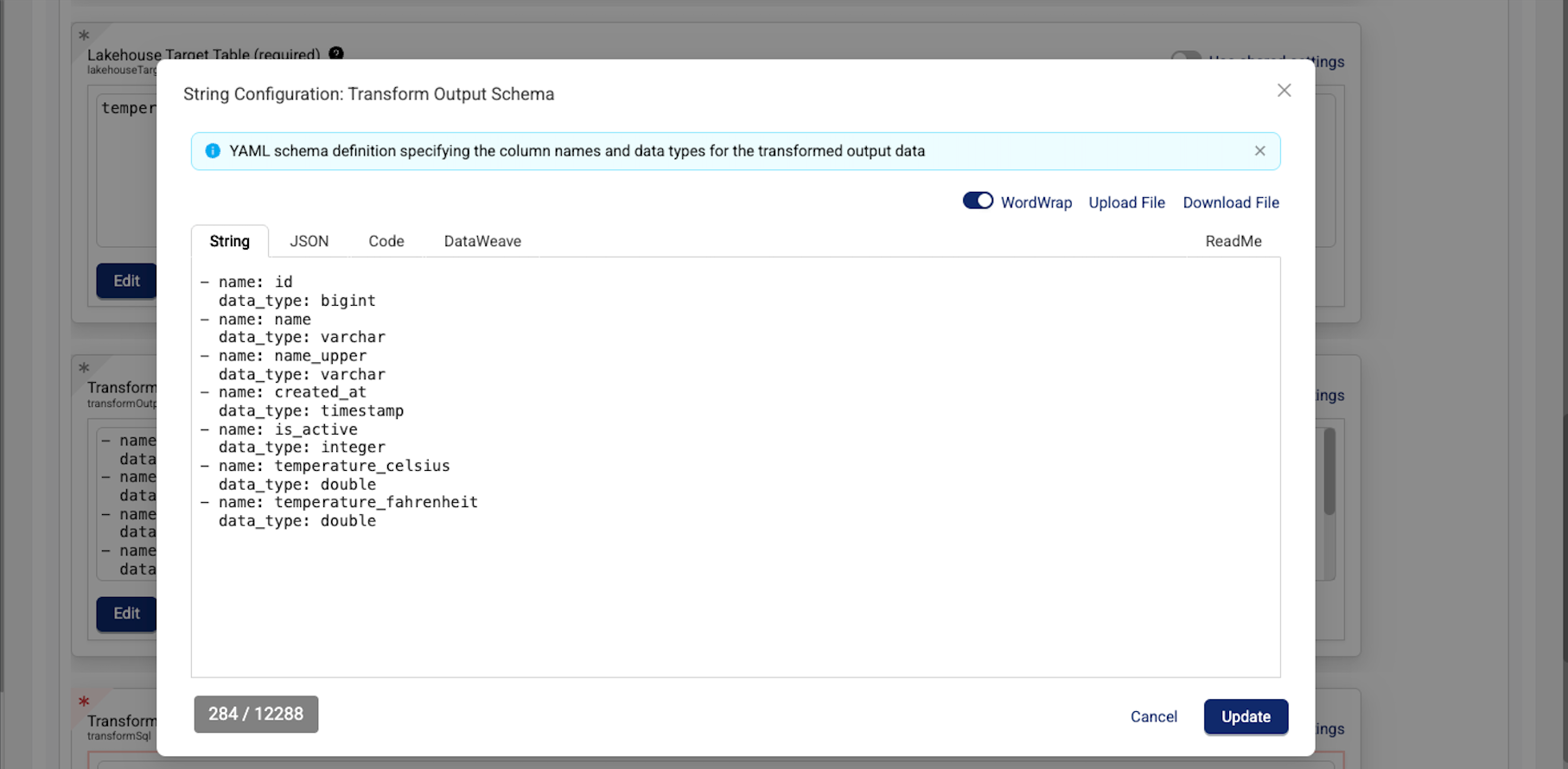
FROM read_csv('{{ env_var("S3_INPUT_PATH") }}', auto_detect=true)- For Transform Output Schema (required), enter the schema in data build tool (dbt) YAML format. For more information, see the dbt Labs YAML Style Guide.
IMPORTANTMake sure that you don't include line breaks (
\n), trailing whitespaces, or other special characters in your transform output'sschemaIdentifierfield. The presence of a hidden, special character results in the output table not being created.
- For Cluster Sizing, select the size of the compute cluster that you want the TDP to use for this pipeline. Starting in TDP v4.5.3, a default all-purpose compute cluster is pre-selected for all
direct-to-lakehousejobs. For most use cases, the default cluster size is appropriate. Choose a larger cluster size only if your pipeline processes large volumes of data or requires lower latency.
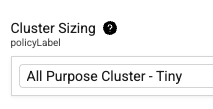
IMPORTANTThe cluster size selections available in
direct-to-lakehousev0.3.0 and later are only available in TDP v4.5.0 and later.
- (Optional) Set email notifications for successful and failed pipeline executions.
- Choose Save Changes.
NOTEIf the Pipeline Enabled toggle is set to active when you choose Save Changes, then the pipeline will run as soon as the configured trigger conditions are met. All
direct-to-lakehousetables are written to theorg_name__tss__externalschema.
For more information about configuring pipelines, see Set Up and Edit a Pipeline.
Backfill Historical Data Into Lakehouse Tables
To backfill historical data into Lakehouse tables, create a Bulk Pipeline Process Job that uses an ids-to-lakehouse pipeline and is scoped in the Date Range field by the appropriate IDSs and historical time ranges.
Documentation Feedback
Do you have questions about our documentation or suggestions for how we can improve it? Start a discussion in TetraConnect Hub. For access, see Access the TetraConnect Hub.
NOTEFeedback isn't part of the official TetraScience product documentation. TetraScience doesn't warrant or make any guarantees about the feedback provided, including its accuracy, relevance, or reliability. All feedback is subject to the terms set forth in the TetraConnect Hub Community Guidelines.
Updated about 1 month ago