TDP v4.0.0 Release Notes
Release date: 9 April 2024
TetraScience has released its next version of the Tetra Data Platform (TDP), version 4.0.0. This release focuses on helping scientists quickly find, access, and derive meaningful insight from their scientific data. It also simplifies how system administrators manage their TDP environments, includes enhanced controls for authentication and authorization, and introduces several performance improvements.
Here are the details for what’s new in TDP v4.0.0.
Key Updates
Data Access and Management
- A new Projects page helps scientists quickly organize and access data that’s associated with specific labs, experiments, instruments, or any other type of project
- A new Search experience (updated from beta in TDP v3.6.x) makes it simpler to find and access scientific data through more customizable search filters and provides new ways to explore data through hierarchical data presentation
- Tetra Data Workspace (beta release) provides the ability to colocate data with software that’s familiar to scientists and correlate analysis outputs in the Tetra Scientific Data and AI Cloud (the FlowJo Data App for single-cell flow cytometry analysis is available in this beta release)
TDP System Administration
- Data Access Rules and Access Groups provide organization admins the ability to define data access rules for a group, or at individual user level through attribute-based access controls (ABAC)
- OAuth 2.0-based authentication workflows enhance authentication security in the TDP user interface and TetraScience API by providing additional configuration options for refresh tokens, access tokens, and timeout periods
- Event Subscriptions give customers the ability to programmatically notify downstream systems of key events in their TDP environment
- New tenant-level system settings provide customers more granular user controls
- A new System Log page provides a list of platform activities for each TDP user account and service account, such as log-in attempts, downloads, and file uploads
Performance and Scale
- Custom pipeline Retry Behavior settings provide more flexibility when configuring pipeline retry logic
- OpenSearch replaces Elasticsearch to improve search query performance and lower infrastructure cost
- A new data lakehouse architecture (beta release) enables limited creation of data sets in an open table format and improves SQL query performance
SecurityTetraScience continually monitors and tests the TDP codebase to identify potential security issues. Various security updates are applied to the following areas on an ongoing basis:
- Operating systems
- Third-party libraries
Quality ManagementTetraScience is committed to creating quality software. Software is developed and tested following the ISO 9001-certified TetraScience Quality Management System. This system ensures the quality and reliability of TetraScience software while maintaining data integrity and confidentiality.
New Functionality
New functionalities are features that weren’t previously available in the TDP.
GxP Impact AssessmentAll new TDP functionalities go through a GxP impact assessment to determine validation needs for GxP installations. New Functionality items marked with an asterisk (*) address usability, supportability, or infrastructure issues, and do not affect Intended Use for validation purposes, per this assessment. Enhancements and Bug Fixes do not generally affect Intended Use for validation purposes, and items marked as beta release or early adopter program (EAP) are not suitable for GxP use.
Data Integrations New Functionality
Pluggable Connector Failover Options*
New Pluggable Connector failover options provide customers the ability to seamlessly switch any Pluggable Connector to another Tetra Hub or the cloud, if network requirements permit.
For more information, see Change a Pluggable Connector's Host.
Diagnostics Support for Hubs*
Customers can now send Tetra Hubs logs directly from the TDP to the TetraScience Support Team for troubleshooting. The logs are sent to a secured Amazon Simple Storage Service (Amazon S3) bucket that's owned by TetraScience. The bucket is used for troubleshooting purposes only. After 30 days, logs are deleted.
For more information, see Send Integration Logs to TetraScience for Troubleshooting.
Data Harmonization and Engineering New Functionality
Custom Pipeline Retry Behavior Settings*
To provide more flexibility when configuring pipeline retry logic and to better accommodate longer-spanning network connectivity issues, customers can now configure custom pipeline Retry Behavior settings up to 10 MAX RETRIES. Previously, the maximum number of retry attempts was 3.
In addition to the three existing default behaviors (Always retry 3 times, Always retry 3 times (after OOM error only), and No Retry), the following custom pipeline retry options are now available:
- Constant retry interval: Sets a specific, custom time period (BASE RETRY DELAY) between each retry attempt
- Linear retry interval increasing: Sets a specific BASE RETRY DELAY for the first retry attempt, and then adds that same time period to the delay for each following attempt.
- Exponential retry interval increasing (default): Sets a specific BASE RETRY DELAY for the first retry attempt, and then doubles each time period for each following attempt exponentially.
For more information, see Retry Behavior Settings.
NOTECustom pipeline retry behavior settings are available for pipelines that use the
protocol.ymlprotocol definition file format only. For more information, see Protocol YAML Files.
Import and Download Pipelines
To simplify migrating pipelines between TDP environments, customers can now import and download pipeline definitions directly through the TDP user interface.
For more information, see Import a Pipeline and Download a Pipeline.
Data Access and Management New Functionality
Projects Page
Scientists can now organize and access data that’s associated with specific labs, experiments, instruments, or any other type of project by using the new Projects page. Projects are organized by user-defined attributes, and are updated with new data automatically when files that contain those attributes are uploaded to the TDP.
For more information, see Projects.
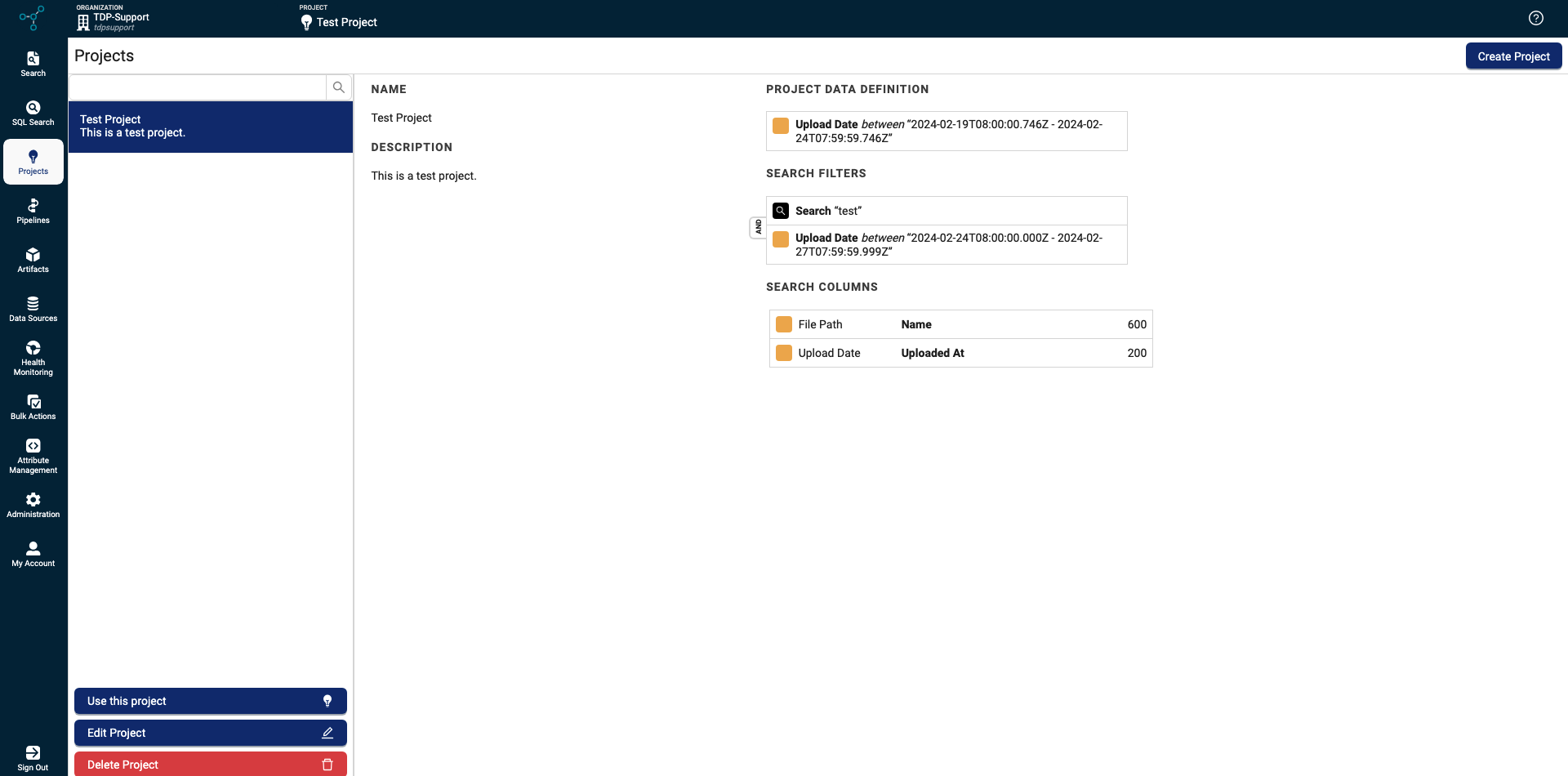
Projects page
Tetra Data Workspace (Beta Release)*
The new Data Workspace page helps scientists colocate their scientific data with their analysis applications and correlate analysis results through Tetra Data Apps.
The Tetra FlowJo Data App introduced in TDP v4.0.0 is the first of many data apps to come. It allows scientists to access Tetra Data on their local desktop directly through FlowJo, a platform for single-cell flow cytometry analysis.
Data Workspace and the Tetra FlowJo Data App are in beta release currently and may require changes in future TDP releases. If you are interested in using them, please contact your customer success manager (CSM).
For more information, see Tetra Data Workspace.
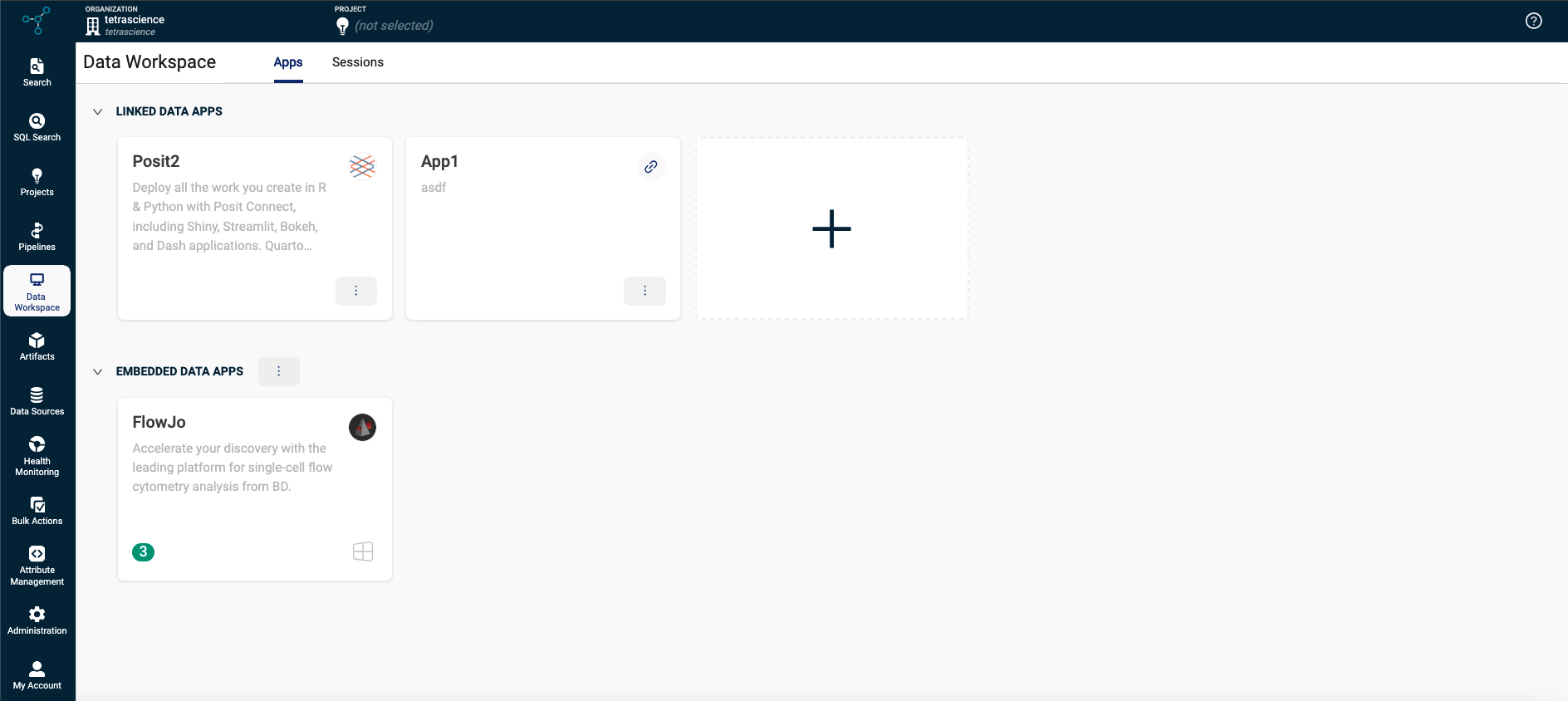
Tetra Data Workspace
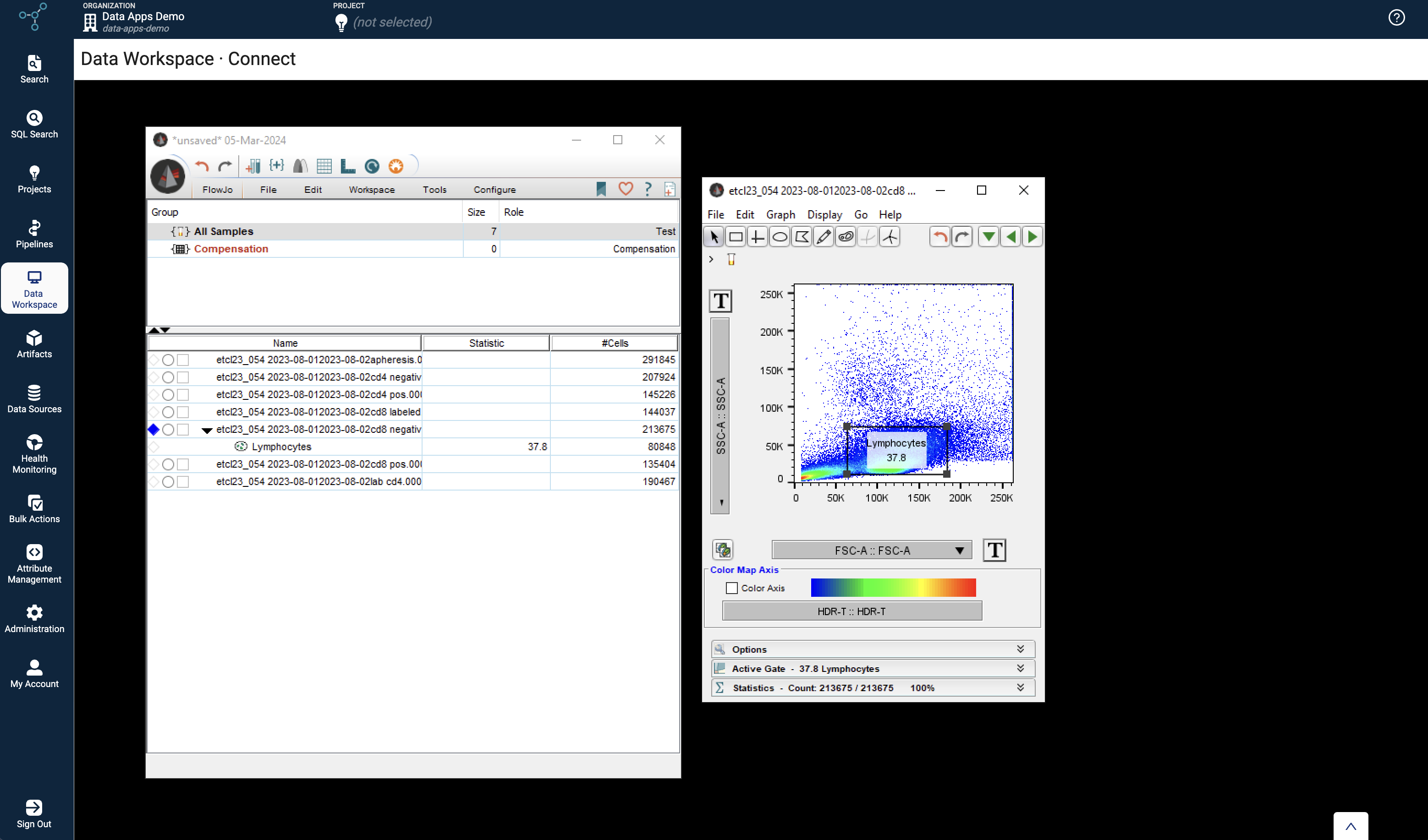
Tetra FlowJo Data App
Search
The Search (beta) page that was in beta release for TDP v3.6.x is now the main Search page in the TDP user interface. The previous Search Files page is still available and is listed in the left navigation menu under Search as Search (Classic).
The new Search page is designed for scientific users to be able to do the following:
- Quickly search for RAW data in the TDP by the following criteria:
- Existing search bar
- Any populated recommended labels
- Existing saved searches (previously referred to as
Collections)
- Add additional filters or columns to the results
- Create, update, and manage saved searches
- Explore data in a hierarchical folder-like view
- Default search filters can be updated for your organization through settings
- Download multiple files at once with the new Bulk Download option
For more information, see Search.
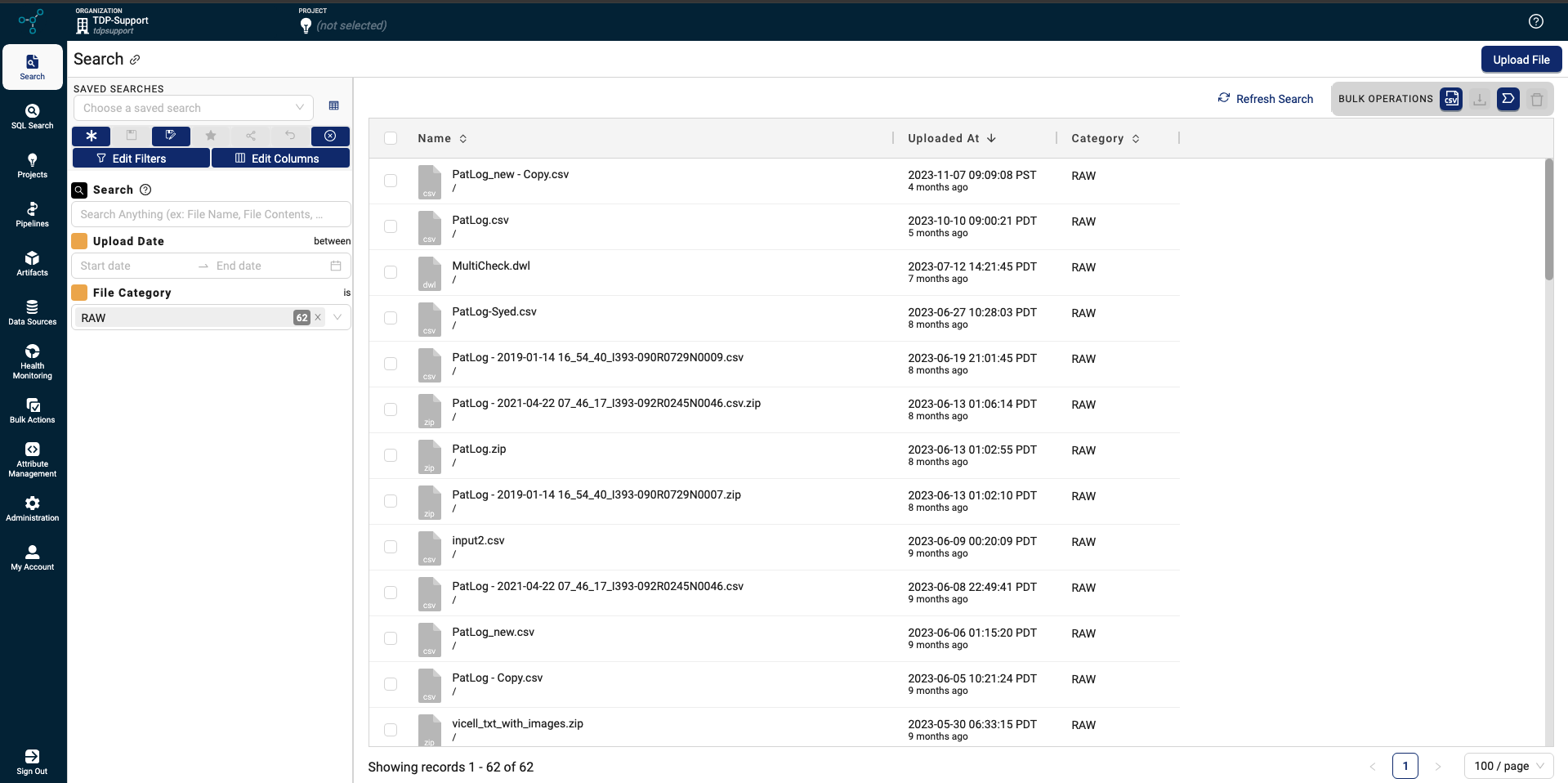
Search page
TDP System Administration New Functionality
Tenant-Level System Settings
To allow for more granular access controls, tenants are now the highest-level entity in each TDP environment instead of organizations. Each customer is represented by one tenant on the TDP only. Tenants can include one or more organizations.
Because of this change, the following actions that previously occurred at the organization level now must be configured at the tenant level on the new Tenant Settings page:
- Configure token settings
- Set password policies
- Configure single sign-on (SSO) settings
For more information, see Tenant Settings.
IMPORTANTPassword policies are now set at the tenant level. Organizations within the same tenant must now use the same password policies.
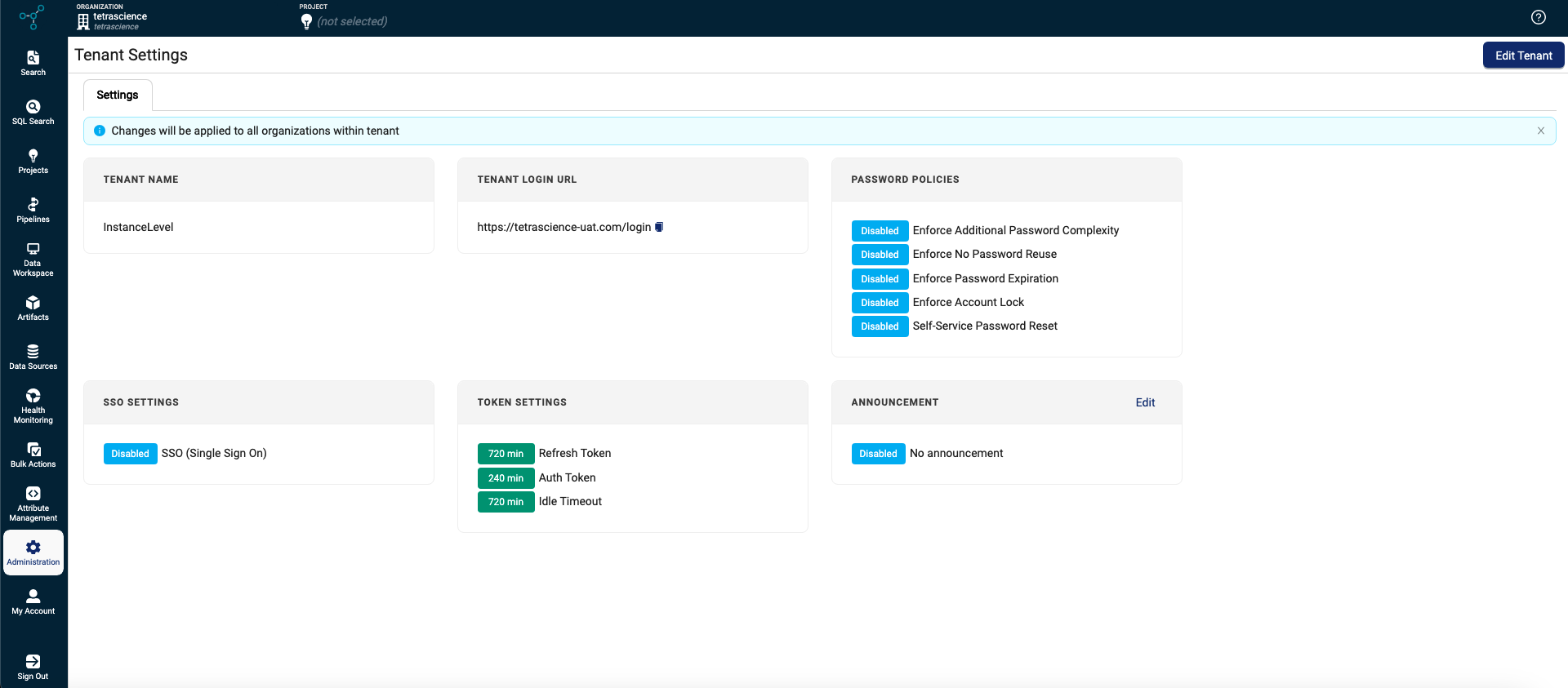
Tenant Settings page
Data Access Rules and Access Groups
To provide more control over who has access to specific data sets within a TDP organization, organization admins can now define metadata-driven Data Access Rules through Access Groups. By enabling Data Access Rules on the Organizations Settings page in the TDP user interface, admins can configure data access permissions for multiple users based on specific file metadata (source type and file attributes).
For more information, see Configure Data Access Rules for an Organization.
IMPORTANTData access remains open to all TDP users within an organization until an organization admin configures access groups for that organization. After access groups are activated for an organization, all users within that organization must be assigned to an access group; otherwise, they won’t have access to any data.
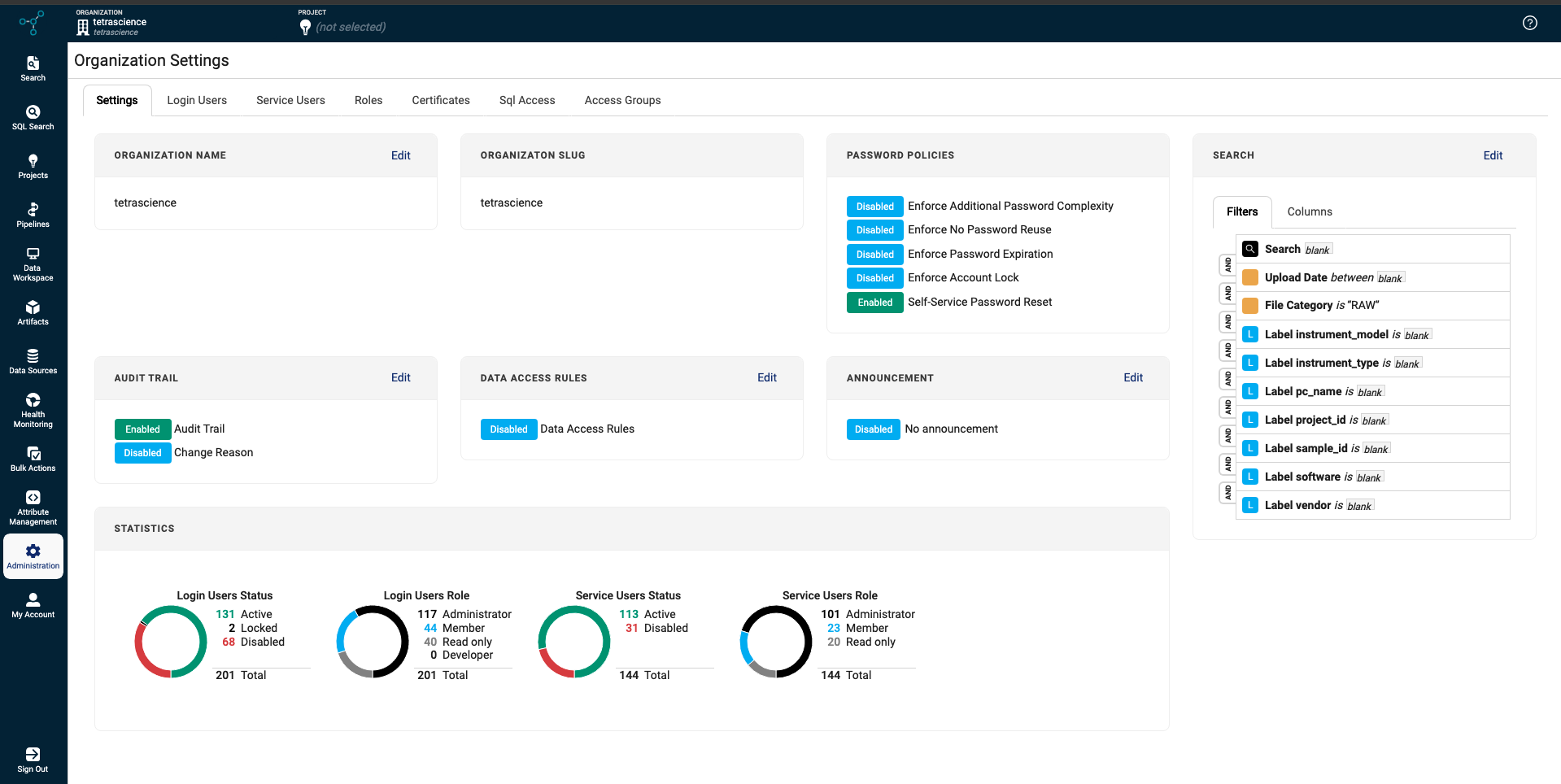
Organization Settings page
OAuth 2.0-Based Authorization Workflows
The TDP and TetraScience API now use OAuth 2.0 Authorization Code Flow for authentication and authorization.
The new authentication method provides the following benefits:
- Developers can now programmatically retrieve access tokens through API calls for TDP User accounts. There’s no longer a need to copy access tokens from the TDP user interface.
- TDP users can configure their personal access tokens to last for a specific length of time, up to 24 hours. There’s no longer a default, four-hour time period on personal tokens.
- Organization admins can now set an inactivity timeout period for inactive users. Previously, there was no way for admins to set an inactivity timeout period.
For more information, see Copy a Personal Token for Authentication, Generate a JWT for a Service User, and Authentication.
IMPORTANTFor security reasons, the new OAuth 2.0 authentication method doesn’t allow the following:
- Non-expiring Service User tokens are no longer allowed. All access tokens must have an expiration date.
- Users can no longer copy access tokens from the TDP UI after a token is generated. Users can now only copy access tokens when they’re first generated.
System Log
The new System Log page provides a comprehensive list of platform activity for each TDP user account and service account, such as log-in attempts, downloads, and file uploads. All GxP/Part 11 compliance-related events are also still logged in the Audit Trail.
System logs are available for up to 90 days and are accessible to users with Org Admin and Read-Only roles only.
For more information, see System Log.
Event Subscriptions
Customers can now programmatically notify downstream systems of key events in their TDP environment by using Event Subscriptions through Amazon EventBridge. This new subscription functionality can help drive custom apps and business processes, such as the following:
- Notify a custom app when a file is uploaded to the TDP from a specific instrument type
- Alert scientists when a file is available for search
- Programmatically monitor Tetra Agent health
- Fuel workflow operational metrics and custom dashboards
For more information, see Event Subscriptions.
IMPORTANTEvent Subscriptions require the use of AWS Database Migration Service (DMS), which increases infrastructure cost. For more information and for help reducing this cost, customers with single-tenant, customer hosted TDP environments should contact their success manager (CSM).
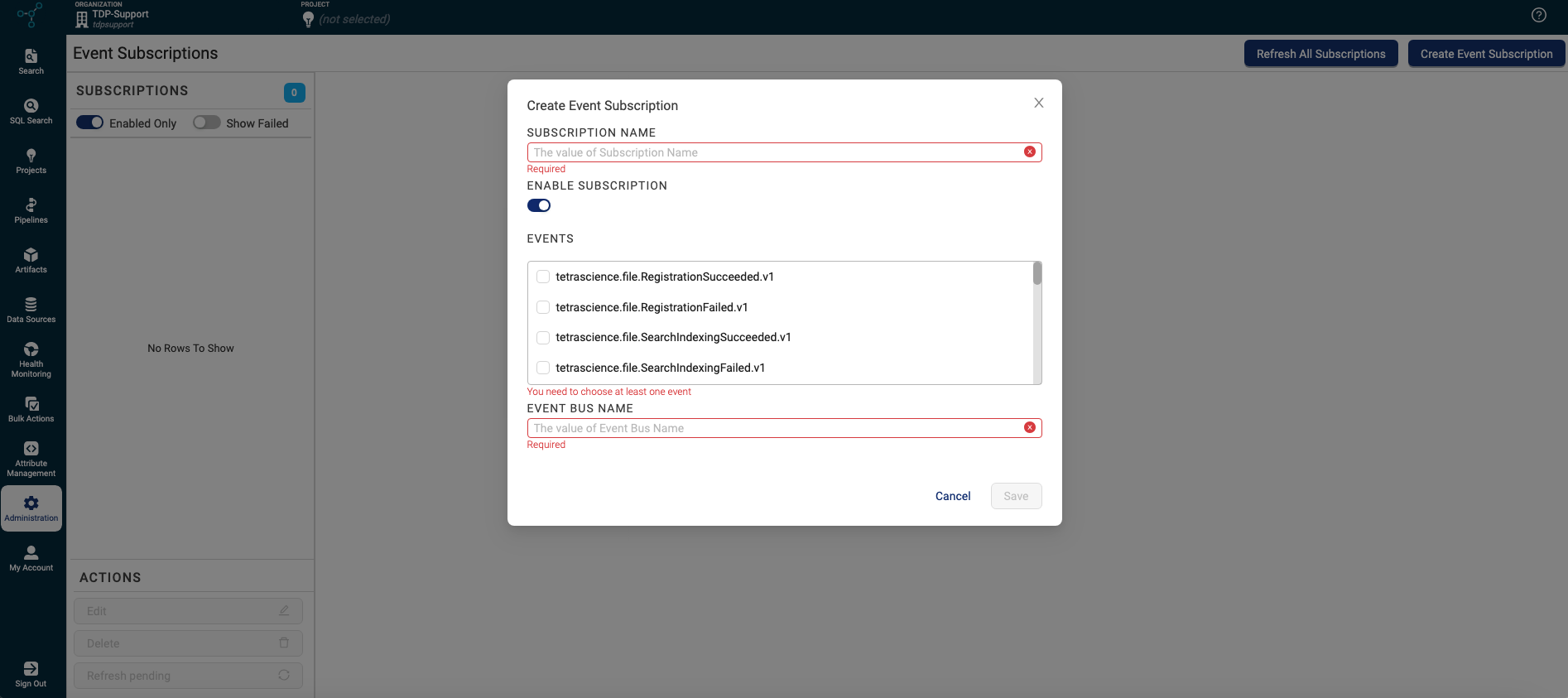
Event Subscriptions page
Enhancements
Enhancements are modifications to existing functionality that improve performance or usability, but don't alter the function or intended use of the system.
Performance and Scale Enhancements
Data Lakehouse Architecture (Beta Release)
A new data lakehouse architecture improves SQL query performance by better managing high-compute workloads than the previous Data Lake architecture. For example, the new storage architecture can help speed up the production of ML-ready datasets that aggregate many Intermediate Data Schemas (IDSs).
The new data lakehouse architecture is in beta release currently and may require changes in future TDP releases. The enhancement is activated for specific IDSs on request only.
OpenSearch Replaces Elasticsearch for Running Search Queries
To improve search performance, the TDP now uses OpenSearch to facilitate search queries instead of Elasticsearch. There is no impact to customers' existing search and Query Domain Specific Language (DSL) searches. However, when using the OpenSearch Query Validate API, errors appear in an explanation field, rather than an error field.
IMPORTANTMigrating data from Elasticsearch to OpenSearch requires running both the existing Elasticsearch cluster and a new OpenSearch cluster for a period of time. During the upgrade to TDP v4.0.0, this migration will increase the infrastructre cost of both of these services, based on the number of files on the platform and how long it takes to process them. For more information and for help reducing this cost, customers with single-tenant, customer hosted TDP environments should contact their CSM.
Data Integrations Enhancements
Tetra Snowflake Integration (EAP) Improvements
The following enhancements were made to the Tetra Snowflake Integration:
- Improved data processing that allows for near real-time data sharing
- Improved scalability for supporting larger data sets
- Simplified resource provisioning
These enhancements improve the initial, historical data loading time and reduce how long it takes for new data to be available in Snowflake. They also decrease the cost associated with sharing data with a Snowflake account.
The Tetra Snowflake Integration is available through an early adopter program (EAP) currently and may require changes in future TDP releases. For more information, see Tetra Snowflake Integration.
Tetra Hubs Inherit Their Host Server’s DNS Nameservers
Tetra Hubs now automatically inherit their host server’s DNS nameservers during installation, unless custom L7 Proxy DNS Nameservers are configured. Previously, if custom L7 DNS nameservers weren’t specified, the settings would default to public DNS nameservers.
For more information, see Tetra Hub Proxy Settings.
Bug Fixes
The following bugs are now fixed.
Data Integrations Bug Fixes
- The Command Details page no longer displays the following error when a command has no response (for example, if the request's status is Pending):
"ERROR":{1 item "message":"src property must be a valid json object" } - Pluggable Connector offline alarms are now created automatically when a Connector is created. Customers no longer need to select Sync on the Connector Details page after the Connector is online to create these alarms.
- When installing or rebooting a Tetra Hub, the Hub’s Health status no longer incorrectly displays as CRITICAL for a short time in the TDP UI. The Hub’s status now displays as INITIALIZING immediately after installation for up to five minutes until the Hub’s initial metrics and proxy status are gathered. Then, the Hub’s status changes to ONLINE.
- The Events tab on the Health Monitoring dashboard no longer presents a spinner if an Agent is configured with no file path (
filePath) and hasn't produced any file events (fileEvents). - For Tetra Data Hubs that use a proxy configured with basic authentication settings, a non-exploitable security vulnerability was patched. For Tetra Data Hubs that were deployed before TDP v4.0.0, the security patch must be implemented manually. Customers with affected Data Hubs should contact their customer success manager (CSM) for instructions.
Deprecated Features
The following features are now on a deprecation path:
-
The following API endpoints are now on a deprecation path, because they don’t support the new Access Groups functionality:
Customers should use the Search files via Elasticsearch Query Language endpoint instead. For more information, see the Search Files, Search Workflow, and Paginate through All Pipeline Details API Endpoints Deprecation notice.
Known and Possible Issues
Last updated: 18 December 2024
The following are known and possible issues for the TDP v4.0.0 release.
Data Harmonization and Engineering Known Issues
- File statuses on the File Processing page can sometimes display differently than the statuses shown for the same files on the Pipelines page in the Bulk Processing Job Details dialog. For example, a file with an
Awaiting Processingstatus in the Bulk Processing Job Details dialog can also show aProcessingstatus on the File Processing page. This discrepancy occurs because each file can have different statuses for different backend services, which can then be surfaced in the TDP at different levels of granularity. A fix for this issue is in development and testing. - Logs don’t appear for pipeline workflows that are configured with retry settings until the workflows complete.
- Files with more than 20 associated documents (high-lineage files) do not have their lineage indexed by default. To identify and re-lineage-index any high-lineage files, customers must contact their CSM to run a separate reconciliation job that overrides the default lineage indexing limit.
- OpenSearch index mapping conflicts can occur when a client or private namespace creates a backwards-incompatible data type change. For example: If
doc.myFieldis a string in the common IDS and an object in the non-common IDS, then it will cause an index mapping conflict, because the common and non-common namespace documents are sharing an index. When these mapping conflicts occur, the files aren’t searchable through the TDP UI or API endpoints. As a workaround, customers can either create distinct, non-overlapping version numbers for their non-common IDSs or update the names of those IDSs. - File reprocessing jobs can sometimes show fewer scanned items than expected when either a health check or out-of-memory (OOM) error occurs, but not indicate any errors in the UI. These errors are still logged in Amazon CloudWatch Logs. A fix for this issue is in development and testing.
- File reprocessing jobs can sometimes incorrectly show that a job finished with failures when the job actually retried those failures and then successfully reprocessed them. A fix for this issue is in development and testing.
- On the Pipeline Manager page, pipeline trigger conditions that customers set with a text option must match all of the characters that are entered in the text field. This includes trailing spaces, if there are any.
- File edit and update operations are not supported on metadata and label names (keys) that include special characters. Metadata, tag, and label values can include special characters, but it’s recommended that customers use the approved special characters only. For more information, see Attributes.
- The File Details page sometimes displays an Unknown status for workflows that are either in a Pending or Running status. Output files that are generated by intermediate files within a task script sometimes show an Unknown status, too.
Data Access and Management Known Issues
Last updated: 18 December 2024
-
When customers upload a new file on the Search page by using the Upload File button, the page doesn’t automatically update to include the new file in the search results. As a workaround, customers should refresh the Search page in their web browser after selecting the Upload File button. A fix for this issue is in development and testing and is scheduled for a future TDP release. (Updated on 18 December 2024)
-
In the Filters dialog on the Search page, tag-related filters have two related known issues:
- The Select a filter type dropdown doesn’t provide the option to filter search results by Tags.
- The Tag Name filter’s dropdown doesn’t automatically populate with all of an organization’s available tags.
As a workaround, customers can do the following:
- To search for files with specific tags, customers should enter the exact tag value in the Tag Name filter field. (To retrieve a list of an organization’s existing tags, customers can reference the Tags filter dropdown on the Search (Classic) page.)
- To search for files that exclude specific tags, customers can do either of the following:
- Search by tags on the Search (Classic) page.
- Add the tag to the Tags tab on the Attribute Management page before running the search. This action populates the Select a filter type dropdown with the added tags.
A fix for this issue is in development and testing and is scheduled for a future TDP release. (Issue #3916) (Added on 22 October 2024)
-
Query DSL queries run on indices in an OpenSearch cluster can return partial search results if the query puts too much compute load on the system. This behavior occurs because the OpenSearch
search.default_allow_partial_resultsetting is configured astrueby default. To help avoid this issue, customers should use targeted search indexing best practices to reduce query compute loads. A way to improve visibility into when partial search results are returned is currently in development and testing and scheduled for a future TDP release. (Added on 25 September 2024) -
Embedded Data Apps based on Windows may not load if a customer’s local web browser’s tracking prevention settings are activated. A fix for this issue is in development and testing, and it currently affects the Tetra FlowJo Data App only. As a workaround, customers can deactivate their browser’s tracking prevention settings. For more information, see An Embedded Data App Based on Windows Won’t Open.
-
Text within the context of a RAW file that contains escape (
\) or other special characters may not always index completely in OpenSearch. A fix for this issue is in development and testing, and is scheduled for an upcoming release. -
If a data access rule is configured as [label] exists > OR > [same label] does not exist, then no file with the defined label is accessible to the Access Group. A fix for this issue is in development and testing and scheduled for a future TDP release.
-
When using SAVED SEARCHES created with the Search Files page (Search (Classic)) prior to TDP v4.0.0, the new Search page can sometimes appear blank. A fix for this issue is in development and testing and planned for a future TDP release. As a workaround, customers should recreate the saved search by using the new Search page.
-
File events aren’t created for temporary (TMP) files, so they’re not searchable. This behavior can also result in an Unknown state for Workflow and Pipeline views on the File Details page.
-
File events aren’t created for temporary (TMP) files, so they’re not searchable. This behavior can also result in an Unknown state for Workflow and Pipeline views on the File Details page.
-
When customers search for labels that include @ symbols in the TDP UI’s search bar, not all results are always returned.
-
When customers search for some unicode character combinations in the TDP UI’s Search bar, not all results are always returned.
-
If customers modify an existing collection of search queries by adding a new filter condition from one of the Options modals (Basic, Attributes, Data (IDS) Filters, or RAW EQL), but they don't select the Apply button, the previous, existing query is deleted. To modify the filters for an existing collection, customers must select the Apply button in the Options modal before you update the collection. For more information, see How to Save Collections and Shortcuts.
-
The File Details page displays a
404error if a file version doesn't comply with the configured Data Access Rules for the user.
TDP System Administration Known Issues
- The latest Connector versions incorrectly log the following errors in Amazon CloudWatch Logs:
Error loading organization certificates. Initialization will continue, but untrusted SSL connections will fail.Client is not initialized - certificate array will be empty
These organization certificate errors have no impact and shouldn’t be logged as errors. A fix for this issue is currently in development and testing, and is scheduled for an upcoming release. There is no workaround to prevent Connectors from producing these log messages. To filter out these errors when viewing logs, customers can apply the following CloudWatch Logs Insights query filters when querying log groups. (Issue #2818)
CloudWatch Logs Insights Query Example for Filtering Organization Certificate Errors
fields @timestamp, @message, @logStream, @log | filter message != 'Error loading organization certificates. Initialization will continue, but untrusted SSL connections will fail.' | filter message != 'Client is not initialized - certificate array will be empty' | sort @timestamp desc | limit 20 - If a reconciliation job, bulk edit of labels job, or bulk pipeline processing job is canceled, then the job’s ToDo, Failed, and Completed counts can sometimes display incorrectly.
Upgrade Considerations
IMPORTANTFor customer hosted deployments, the following services must be allowed in the AWS account that hosts the TDP before upgrading:
- Amazon Cognito
- AWS Database Migration Service (DMS)
- Amazon ElastiCache
- Amazon Kinesis Data Streams
- Amazon OpenSearch Service
- Amazon EventBridge Pipes
- (For customers activating Tetra Data Workspace only) Amazon AppStream 2.0
For more information, see Required AWS Services.
During the upgrade, there might be a brief downtime when users won't be able to access the TDP user interface and APIs.
After the upgrade, the TetraScience team verifies that the platform infrastructure is working as expected through a combination of manual and automated tests. If any failures are detected, the issues are immediately addressed, or the release can be rolled back. Customers can also verify that TDP search functionality continues to return expected results, and that their workflows continue to run as expected.
For more information about the release schedule, including the GxP release schedule and timelines, see the Product Release Schedule.
For more details about the timing of the upgrade, customers should contact their CSM.
Other Release Notes
To view other TDP release notes, see Tetra Data Platform Release Notes.
Updated 2 months ago