Tetra Amazon S3 Connector
The Tetra Amazon S3 Connector is a standalone, containerized application that automatically uploads files (objects) from your organization's Amazon Simple Storage Service (Amazon S3) buckets to the Tetra Data Platform (TDP) whenever an object is created. Amazon S3 is an object storage service that offers high scalability, data availability, security, and performance.
Design Overview
The Tetra Amazon S3 Connector communicates with S3 by receiving ObjectCreated events through an Amazon Simple Queue Service (Amazon SQS) queue. Events are sent to the queue through Amazon Simple Notification Service (Amazon SNS), and then trigger the Connector to upload the new objects to the TDP. Access permissions are configured through AWS Identity and Access Management (IAM).
Architecture
The following diagram shows an example Tetra Amazon S3 Connector workflow:
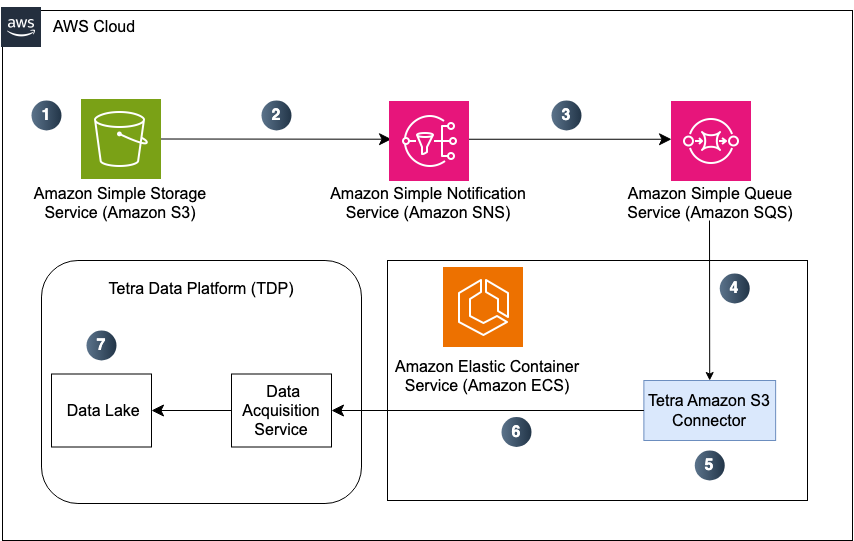
Example Tetra Amazon S3 Connector workflow
The diagram illustrates the following workflow:
- An object is uploaded to the source Amazon S3 bucket, or an object in the S3 bucket has its metadata modified.
- An
ObjectCreatedevent is sent to an Amazon SNS topic. - The SNS topic sends a message that contains the S3 event to an Amazon SQS queue that is subscribed to the SNS topic.
- The Connector continuously polls the SQS queue to receive messages by using long polling.
- When the Connector receives a message, it checks that the message includes an
ObjectCreatedevent. It also checks the key of the S3 object against an optional set of configured path patterns, defaulting to accepting all keys. - If the message has the wrong type or a key that doesn't match, the message is removed from the queue.
-or-
If the message passes the required filters, then the Connector gets the object from the source S3 bucket and streams the data to the TDP Data Lake by using the platform's data acquisition service. - After an object successfully uploads, the Connector deletes the event message from the SQS queue. If the upload fails, the message is not deleted and becomes available on the queue again after the queue's visibility timeout period.
Prerequisites
Before you can create and use a Tetra Amazon S3 Connector, you must have the following:
-
An active TDP environment
-
Knowledge of Python
-
An active AWS account
-
AWS Command Line Interface (AWS CLI) installed and configured
-
An Amazon S3 bucket
-
An Amazon Simple Queue Service (Amazon SQS) queue
-
An Amazon Simple Notification Service (Amazon SNS) topic with an Access Policy that grants
SNS:Publishpermissions to the S3 bucket -
An AWS Identity and Access Management (IAM) role that the Connector can assume (or another IAM permissions method), which grants the following permissions:
Amazon S3 Bucket Permissions
s3:GetObjects3:GetBucketLocations3:ListBuckets3:GetObjectVersions3:GetObjectAttributes
Amazon SQS Queue Permissions
sqs:DeleteMessagesqs:GetQueueUrlsqs:ReceiveMessagesqs:GetQueueAttributes
NOTEThese permissions work with Amazon S3 buckets that are encrypted using the default of server-side encryption with Amazon S3 managed keys (SSE-S3). If your bucket uses server-side encryption with AWS Key Management Service (KMS) keys, you must add the AWS KMS Key permissions to the IAM policy. For more information, see Using IAM policies with AWS KMS in the AWS documentation.
Operational Guides
For installation and operational instructions, see the Tetra Amazon S3 Connector v1 Operational Guide.
Documentation Feedback
Do you have questions about our documentation or suggestions for how we can improve it? Start a discussion in TetraConnect Hub. For access, see Access the TetraConnect Hub.
NOTEFeedback isn't part of the official TetraScience product documentation. TetraScience doesn't warrant or make any guarantees about the feedback provided, including its accuracy, relevance, or reliability. All feedback is subject to the terms set forth in the TetraConnect Hub Community Guidelines.
Updated about 2 months ago