The Tetra Data Platform
The Tetra Data Platform (TDP) is the life sciences industry’s only open, vendor-agnostic, collaborative platform purpose-built for scientific data. Built on Amazon Web Services (AWS) infrastructure, the TDP ingests raw/primary data from thousands of sources, replatforms it to the Tetra Scientific Data and AI Cloud and engineers it by extracting metadata and harmonizing it into a vendor-agnostic format that is liquid, large-scale, engineered, and compliant.
The TDP's event-driven architecture allows you to process data as soon as it's collected and provides pipeline monitoring capabilities that allow you to view the entire pipeline process. You can also use the TDP to perform SQL and Query DSL queries, either through the TDP user interface or the TetraScience API.
The TDP also provides GxP support to help ensure the capture of data provenance through a comprehensive audit trail, disaster recovery, control matrices, and software hazard analysis.
Key Data Activities
The TDP allows you to perform many tasks related to processing, viewing, and managing data. The following are a few examples:
- Replatform data: Use Tetra Integrations to automatically collect and move scientific data between different instruments and applications while centralizing that data in the Tetra Scientific Data and AI Cloud.
- Contextualize files: Add attributes to files to improve how retrievable they are by search. For example, you can use Tetra Data Pipelines to programmatically add information about samples, experiment names, and laboratories. You can add metadata to files through the TDP user interface or through the TetraScience API.
- Harmonize files: Parse proprietary instrument output files into a vendor-neutral format with scientifically relevant metadata through the Intermediate Data Schema (IDS), while also storing the data in SQL tables.
- Enrich files: Get information from other files within the Tetra Scientific Data and AI Cloud to augment new data.
- Push data to third-party applications: Send data to an electronic lab notebook (ELN), laboratory information management system (LIMS), analytics application, or an AI/ML platform.
TDP Architecture
The following diagram shows an example Tetra Data Platform (TDP) workflow.
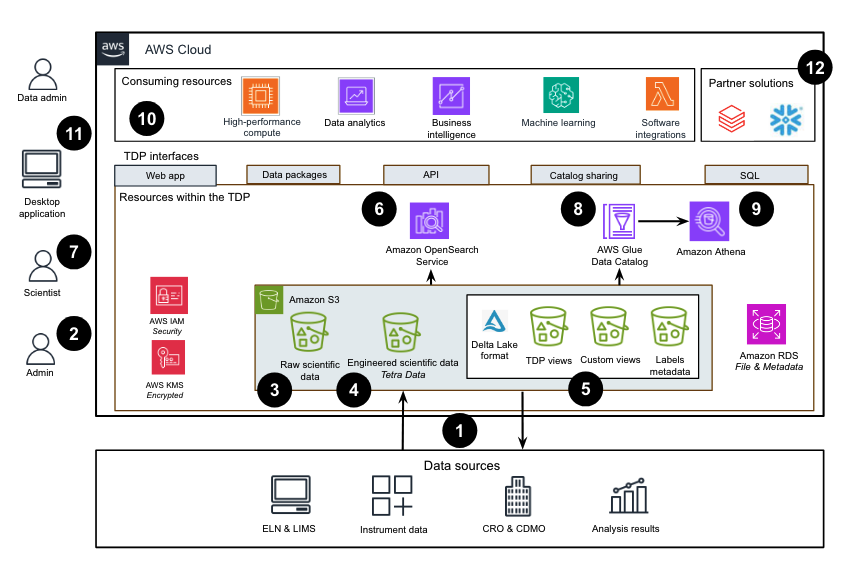
The diagram shows the following process:
- The TDP provides bidirectional integrations for instruments, Electronic Lab Notebooks (ELNs), Laboratory Information Management Systems (LIMS), connectivity middleware, and data science tools. It can also connect with contract research organizations (CROs) and contract development and manufacturing organizations (CDMOs). For a list of available Tetra Integrations, see Tetra Integrations.
- The system administrator uses the TDP user interface to set monitoring paths and extract metadata before uploading raw data to the TDP. Authentication uses AWS Identity and Access Management (IAM) roles and credentials.
- The TDP collects, enhances, and stores raw data in an Amazon Simple Storage Service (Amazon S3) bucket. Metadata is stored in Amazon Relational Database Service (Amazon RDS) and replicates to the Amazon S3 metadata bucket. AWS Key Management Service (AWS KMS) encrypts all data in the TDP.
- The TDP converts raw data into engineered Tetra Data and stores it in the Tetra Data Amazon S3 bucket.
- Tetra Data is converted into tables managed by AWS Glue in an open-source Delta Lake format.
- The Amazon OpenSearch Service maintains a search index for data.
- Scientists can search for data data either through the TDP Search page, SQL and Amazon Athena Queries, TetraScience API, or query domain-specific language (DSL) queries. Scientists can also use the Tetra Data & AI Workspace to access and use scientific data with analysis applications and correlate analysis results through Tetra Data Apps.
- The catalog sharing interface allows data administrators to use the AWS Glue Data Catalog for access controls over Tetra Data tables, which supports secure data sharing between AWS Regions and accounts.
- The SQL interface through Amazon Athena provides interactive querying, analysis, and processing of Tetra Data stored in Amazon S3 and cataloged in AWS Glue.
- Scientists analyze the engineered Tetra Data with high-performance computing, data analytics, data lakes, business intelligence, and machine learning. The TDP also provides software integrations by using APIs and webhooks.
- Locally, scientists create graphs, author reports, and conduct data analysis by using data packages.
- Data administrators integrate partner solutions and software as a service (SaaS) products into the TDP by provisioning API access keys or natively supported integrations, such as Databricks and Snowflake.
For more information about how the TDP uses AWS services, including how its architecture adheres to the AWS Well-Architected Framework, see Guidance for Integrating the TetraScience Tetra Data Platform on AWS in the AWS Solutions Library.
NOTEFor security reasons, multi-tenant Tetra hosted deployments don’t have direct access to the specific AWS resources that support the TDP, such as Amazon S3 buckets.
Updated 2 months ago