Push Data by Using SSPs: Send Data to an AI/ML Platform
You can create self-service Tetra Data pipelines (SSPs) to send data to many downstream systems. For example, you can use an SSP to push data to an electronic lab notebook (ELN), laboratory information management system (LIMS), or an artificial intelligence (AI) / machine learning (ML) platform.
This topic provides an example setup for sending data from the Tetra Scientific Data Cloud to a downstream AI/ML platform.
NOTE
It’s common for AI/ML applications to pull data from an existing database, rather than having data pushed to them. If the AI/ML tool that you’re using requires you to pull data from the Tetra Data Platform (TDP), see Use Third-Party Tools to Connect to Athena Tables.
Also, the following topic shows how to push data to Kaggle specifically. However, you can use a similar process to push Tetra Data to other AI/ML platforms, because most have software development kits (SDKs) and APIs that allow you to push and pull datasets.
Architecture
The following diagram shows an example SSP workflow for sending data from the Tetra Scientific Data Cloud to a downstream AI/ML platform:
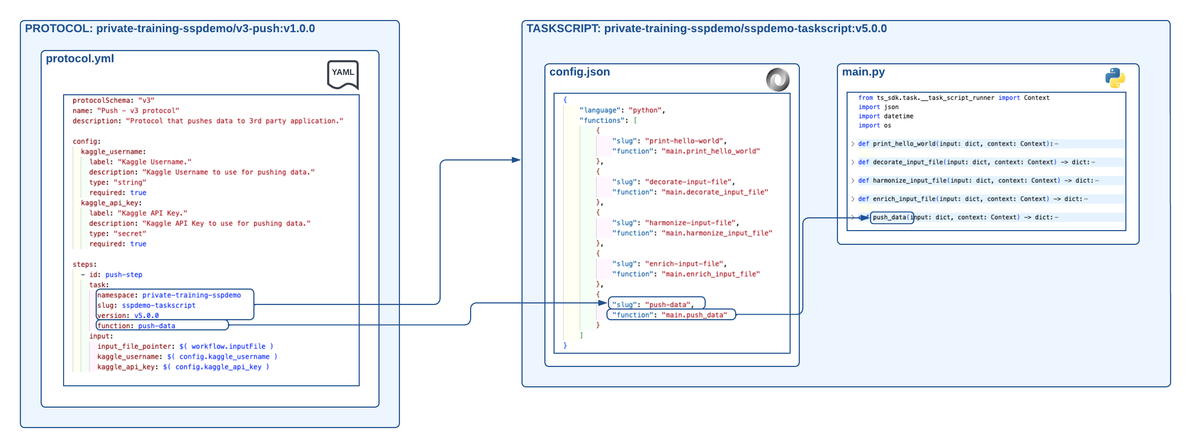
Example SSP workflow for pushing data to another system
The diagram shows the following workflow:
- Required third-party API credentials are identified.
- The API credentials are stored as Shared Settings and Secrets in the TDP.
- The “Hello, World!” SSP Example
sspdemo-taskscripttask script version is updated tov5.0.0. Theconfig.jsonfile has five exposed functions:
- print-hello-world (
main.print_hello_world), which is theprint_hello_worldfunction found in themain.pyfile. - decorate-input-file (
main.decorate_input_file), which is thedecorate_input_filefunction found in themain.pyfile. - harmonize-input-file (
main.harmonize_input_file), which is theharmonize_input_filefunction found in themain.pyfile. - enrich-input-file (
main.enrich_input_file), which is theenrich_input_filefunction found in themain.pyfile. - push-step (
main.push_data), which is thepush_datafunction found in themain.pyfile that uses the third-party API credentials to push data.
- A protocol named
v3-push (v1.0.0)is created. Theprotocol.ymlfile provides the protocol name, description, and two configuration items namedkaggle_usernameandkaggle_api_key. It also outlines one step:push-step. This step points to thesspdemo-taskscripttask script and the exposed function,v3-push. The inputs to this function are the input file that kicked off the pipeline workflow, thekaggle_username, and thekaggle_api_key.
Store Third-Party API Authentication Credentials in the TDP
To use third-party API authentication credentials in your protocol configuration elements and task script Python functions, do the following:
- Get the required authentication credentials from your target system. To get Kaggle credentials, do the following:
- Open Kaggle. Then, choose Settings.
- In the API section, choose Create New Token.
- Save the Username and API Key so that you can save them in the TDP.
- Sign in to the TDP as an admin.
- In the left navigation menu, choose Administration. Then, choose Shared Settings. The Shared Settings page appears.
- Add the username from the target system as a Shared Setting. For instructions, see Add a Shared Setting.
- Add the API key from the target system as a Secret. For instructions, see Add a Secret.
Identify the Required Third-Party SDK and API Endpoints
Each AI/ML platform has a different SDK and API endpoints. Learn how your target system works, and then find the relevant API calls that allow you to send data to your target platform.
For this example setup, Kaggle’s API works by having Kaggle software on a local machine, saving environment variables with your username and API key, and then running a command on the command line to create a new dataset on the Kaggle platform. The example task script in this topic follows this process.
NOTE
You will add these required SDK and API endpoints to a task script in the Create and Deploy a Task Script section of this topic.
Create and Deploy the Task Script
Task scripts are the building blocks of protocols, so you must build and deploy your task scripts before you can deploy a protocol that uses them.
Task scripts require the following:
- A
config.jsonfile that contains configuration information that exposes and makes your Python functions accessible so that protocols can use them. - A Python file that contains python functions (
main.pyin the following examples) that include the code that’s used in file processing. - A
requirements.txtfile that either specifies any required third-party Python modules, or that is left empty if no modules are needed.
To create a task script that programmatically sends data from the Tetra Scientific Data Cloud to a downstream AI/ML platform, do the following.
NOTE
For more information about creating custom task scripts, see Task Script Files. For information about testing custom task scripts locally, see Create and Test Custom Task Scripts.
Create a config.json File
config.json FileCreate a config.json file in your code editor by using the following code snippet:
{
"language": "python",
"runtime": "python3.11",
"functions": [
{
"slug": "print-hello-world",
"function": "main.print_hello_world"
},
{
"slug": "decorate-input-file",
"function": "main.decorate_input_file"
},
{
"slug": "harmonize-input-file",
"function": "main.harmonize_input_file"
},
{
"slug": "enrich-input-file",
"function": "main.enrich_input_file"
},
{
"slug": "push-data",
"function": "main.push_data"
}
]
}
NOTE
You can choose which Python version a task script uses by specifying the
"runtime"parameter in the script'sconfig.jsonfile. Python versions 3.7, 3.8, 3.9, 3.10, and 3.11 are supported currently. If you don't include a"runtime"parameter, the script uses Python v3.7 by default.
Update Your main.py File
main.py FileUsing the task script from Enrich Data by Using SSPs: Add Extra Data to Files, add the following elements to your task script:
# Add new import statement
import os
...
# Add this new function
def push_data(input: dict, context: Context) -> dict:
print("Starting push to 3rd party")
# Pull out the arguments to the function
input_file_pointer = input["input_file_pointer"]
kaggle_username = input["kaggle_username"]
kaggle_api_key_secret = input["kaggle_api_key"]
kaggle_api_key = context.resolve_secret(kaggle_api_key_secret)
print("Get Processed file data")
# Open the file and import json
f = context.read_file(input_file_pointer, form='file_obj')
processed_data = f['file_obj'].read().decode("utf-8")
processed_json = json.loads(processed_data)
print("Start Kaggle content")
# Kaggle Specific
# Add username and API Key to OS environment
os.environ['KAGGLE_USERNAME'] = kaggle_username
os.environ['KAGGLE_KEY'] = kaggle_api_key
# Kaggle Specific
# Pull out the data from the PROCESSED file and save as a temporary file
data = {}
data["data"] = processed_json["extra_data"]
with open('data.json', 'w') as outfile:
json.dump(data, outfile)
# Kaggle Specific
# Create dataset metadata and save as a temporary file
dataset_name = "exampledataset"
dataset_metadata = {
"title": dataset_name,
"id": kaggle_username+"/"+dataset_name,
"licenses": [
{
"name": "CC0-1.0"
}
]
}
with open('dataset-metadata.json', 'w') as outfile:
json.dump(dataset_metadata, outfile)
# Kaggle Specific
# Upload data to Kaggle. Uses OS environment variables
os.system("kaggle datasets create -p .")
Context API
In the Python code provided in this example setup, the Context API is used by importing it in the main.py file (from ts_sdk.task.__task_script_runner import Context). The Context section provides the necessary APIs for the task script to interact with the TDP.
This example setup uses the following Context API endpoint:
- context.resolve_secret: Returns the secret value
NOTE
The
context.resolve_secretfunction converts the AWS Systems Manager (SSM) reference to the actual secret value.
Install Any Required Third-Party Packages
You may need to install a third-party package in your Docker image so your task script can use the installed package (for example, Kaggle or OpenJDK). This example procedure uses Kaggle.
To install a third-party package in the Docker image, do the following:
- Create a folder called
initin your task local task script folder. - Create a new file locally in the
initfolder namedbefore_install. Then, add install command line statements that use your specific package management system.
IMPORTANT
For SSP artifacts built in TDP v3.6 or earlier, the base Docker image is Debian "buster" version 10.
Kaggle Install Command Example
pip install kaggle
OpenJDK Install Command Example
apt-get update && apt-get install -y default-jdk
- Open your task script’s root folder, and then add the
before_installfile by using the following SSP folder structure:
SSP Folder Structure Example that Includes a ./init/before_install File
protocol
└── protocol.yml
task-script
├── init
| └── before_install
├── config.json
└── main.py
NOTE
The code runs when the task script Docker image builds.
IMPORTANT
The executable attributes of task script files on your local machine are not preserved. If a file is executable on your local machine, that doesn’t mean it’s executable during the Docker image build step.
To execute your files during the Docker image build step and have your task script files run them from your code, you must include the following command in your
before_installscript:
chmod a+x ./path-to-your-exec-file
Create a Python Package
Within the task script folder that contains the config.json and main.py files, use Python Poetry to create a Python package and the necessary files to deploy them to the TDP.
Poetry Command Example to Create a Python Package
poetry init
poetry add datetime
poetry export --without-hashes --format=requirements.txt > requirements.txt
NOTE
If no packages are added, this
poetry exportcommand example produces text inrequirements.txtthat you must delete to create an emptyrequirements.txtfile. However, for this example setup, there’s adatetimepackage, sorequirements.txtshouldn't be empty. Arequirements.txtfile is required to deploy the package to the TDP.
Deploy the Task Script
To the deploy the task script, run the following command from your command line (for example, bash):
ts-sdk put task-script private-{TDP ORG} sspdemo-taskscript v5.0.0 {task-script-folder} -c {auth-folder}/auth.json
NOTE
Make sure to replace
{TDP ORG}with your organization slug,{task-script-folder}with the local folder that contains your protocol code, and{auth-folder}with the local folder that contains your authentication information.Also, when creating a new version of a task script and deploying it to the TDP, you must increase the version number. In this example command, the version is increased to
v5.0.0.
Create and Deploy a Protocol
Protocols define the business logic of your pipeline by specifying the steps and the functions within task scripts that execute those steps. For more information about how to create a protocol, see Protocol YAML Files.
In the following example, there’s one step: push-step. This step uses the push-data function that’s in the sspdemo-taskscript task script, which is v5.0.0 of the task script.
Create a protocol.yml File
protocol.yml FileCreate a protocol.yml file in your code editor by using the following code snippet:
protocolSchema: "v3"
name: "Push - v3 protocol"
description: "Protocol that pushes data to 3rd party application."
config:
kaggle_username:
label: "Kaggle Username."
description: "Kaggle Username to use for pushing data."
type: "string"
required: true
kaggle_api_key:
label: "Kaggle API Key."
description: "Kaggle API Key to use for pushing data."
type: "secret"
required: true
steps:
- id: push-step
task:
namespace: private-training-sspdemo
slug: sspdemo-taskscript
version: v5.0.0
function: push-data
input:
input_file_pointer: $( workflow.inputFile )
kaggle_username: $( config.kaggle_username )
kaggle_api_key: $( config.kaggle_api_key )
NOTE
When using a new task script version, you must use the new version number when we’re calling that task script in the protocol step. This example
protocol.ymlfile refers tov5.0.0.
Deploy the Protocol
To the deploy the protocol, run the following command from your command line (for example, bash):
ts-sdk put protocol private-{TDP ORG} v3-push v1.0.0 {protocol-folder} -c {auth-folder}/auth.json
NOTE
Make sure to replace
{TDP ORG}with your organization slug,{protocol-folder}with the local folder that contains your protocol code, and{auth-folder}with the local folder that contains your authentication information.
NOTE
To redeploy the same version of your code, you must include the
-fflag in your deployment command. This flag forces the code to overwrite the file. The following are example protocol deployment command examples:
ts-sdk put protocol private-xyz hello-world v1.0.0 ./protocol -f -c auth.jsonts-sdk put task-script private-xyz hello-world v1.0.0 ./task-script -f -c auth.jsonFor more details about the available arguments, run the following command:
ts-sdk put --help
Create a Pipeline That Uses the Deployed Protocol
To use your new protocol on the TDP, create a new pipeline that uses the protocol that you deployed. Then, upload a file that matches the pipeline’s trigger conditions.
For the configuration elements in the UI configuration of your pipeline, you can use your shared setting (kaggle_username) and shared secret (kaggle_api_key).
Updated 7 months ago