The Tetra Scientific Data and AI Cloud
The Tetra Scientific Data and AI Cloud combines unparalleled expertise in science, modern data stacks, and artificial intelligence (AI) to harness the value of scientific data. For the first time, organizations can have the best of both worlds: Next-generation lab data automation and scientific data management, and the foundational building blocks for scientific AI.
Key Business Outcomes
- Open and vendor agnostic: Provides a vendor-agnostic data stack and data-only business model that prevents proprietary walled gardens and vendor lock-in, future-proofing customer data
- Collaborative: Enables unprecedented data liquidity and AI collaboration among our scientific customers and their partners
- AI native: Enables industrialized production of the world's only large-scale, liquid, engineered, and compliant scientific datasets to fuel scientific AI
- GxP compliant: Supports your Good Manufacturing / Laboratory / Documentation / Machine Learning Practices (GxP)-compliant workflows with full data integrity and traceability throughout the entire product lifecycle
NOTE
For use case examples, see Example Use Cases.
How It Works
The Tetra Scientific Data and AI Cloud connects the entire laboratory ecosystem and eliminates manual, time-consuming data management tasks. Productized integrations with instruments, informatics applications, and software systems across R&D and manufacturing allows for near real-time data capture and increased data integrity. Data is then automatically centralized in the Tetra Scientific Data and AI Cloud and engineered into an open, universally adoptable, vendor-agnostic format: Tetra Data.
This access to findable, accessible, interoperable, and reusable (FAIR) data allows organizations to leverage the potential of AI, machine learning (ML), and advanced analytics to improve outcomes and operational efficiencies, extract deeper insights to fuel new discoveries, and bring treatments to market faster.
Get Value at Every Step in the Scientific Data and AI Journey
Vendor-specific data silos and formats, pervasive across the scientific value chain, inhibit you from assembling the large-scale, liquid, engineered, and collaborative datasets necessary to fundamentally accelerate and improve scientific outcomes.
The Tetra Scientific Data and AI Cloud upends and revolutionizes the scientific data management system (SDMS) market and allows you to move up the inevitable data and AI pyramid to accelerate and improve scientific outcomes.
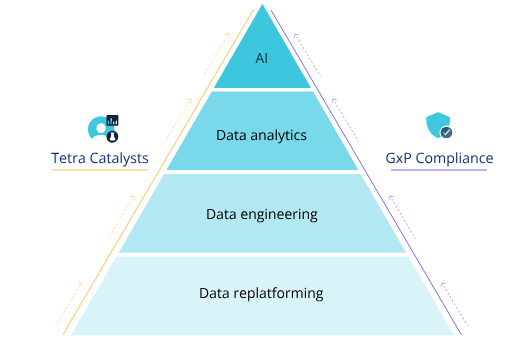
The following are the steps in the scientific data and AI journey that the Tetra Scientific Data and AI Cloud facilitates:
- Data replatforming: Automate the assembly, transfer, and contextualization of your scientific data in a centralized, purpose-built cloud.
- Data engineering: Transform your raw, scientific data into contextualized, harmonized, large-scale, and liquid AI-native data.
- Data analytics: Generate new insights by using engineered Tetra Data in your dashboards, visualization tools, and analytics applications.
- Scientific AI: Achieve groundbreaking scientific outcomes by preparing your data for cutting-edge AI applications and collaborative workflows.
Components
The Tetra Scientific Data and AI Cloud consists of the following components.
Tetra Data Platform
The Tetra Data Platform (TDP) is the industry’s only open, cloud-native, purpose-built scientific data platform. Built on Amazon Web Services (AWS) infrastructure, the TDP ingests raw/primary data from thousands of sources, engineers them, extracts metadata, harmonizes content, and replatforms it to the cloud in a vendor-agnostic format that is harmonized, compliant, liquid, and actionable.
The TDP also provides GxP support to help ensure the capture of data provenance through a comprehensive audit trail, disaster recovery, control matrices, and software hazard analysis.
Tetra Integrations
You can use Tetra Integrations to automatically collect and send scientific data between different instruments and applications while centralizing that data in the Tetra Scientific Data Cloud. You can then use Tetra Data models in your pipelines to automate data operations and transformations.
TetraScience provides bidirectional integrations for many instruments, Electronic Lab Notebooks (ELNs), Laboratory Information Management Systems (LIMS), connectivity middleware, and data science tools. For a list of available Tetra Integrations, see Supported Tetra Integrations.
Tetra Data Lake
The cloud-based Tetra Data Lake is an important component of the TDP that contains the following:
- RAW data
- Standardized data in Intermediate Data Schema (IDS) formatting
- Search index
- Graph representation of the data
- Data in tabular formats to facilitate SQL queries
Tetra Data Pipelines
TetraScience automated data operations and transformations are handled by Tetra Data Pipelines and self-service Tetra Data pipelines (SSPs). A pipeline is a way to configure a set of actions to occur automatically each time new data is ingested into the Data Lake.
Intermediate Data Schemas
The Intermediate Data Schemas (IDSs) designed by TetraScience in collaboration with instrument manufacturers, scientists, and customers, are applied to raw instrument data or report files to map vendor-specific information (like the name of a field) to vendor-agnostic information. The IDS standardizes naming, data type, data range, and data hierarchy.
By doing this, each IDS harmonizes different data sets in the Life Science industry, such as instrument data, CRO assay data and software data. This allows Life Sciences companies to consume the data in their applications, build searches and aggregations and feed the data into visualization/analysis software seamlessly, because the IDS generated JSON files are predictable, consistent, and vendor agnostic.
Tetra Data Models and Custom Schemas
TetraScience provides many Tetra Data models as well as options for creating custom schemas. You can use these schematized representations of common scientific data in pipelines to automate data operations and transformations. Through this process, your data becomes easily accessible through search in the Tetra Data Platform (TDP) user interface, TetraScience API, and SQL queries.
Tetra Quality Management System
The Tetra Quality Management System (QMS) ensures data integrity, traceability, reliability, and availability for scenarios that include capturing of data provenance through a comprehensive audit trail, disaster recovery, control matrices, and software hazard analysis.
Tetra Catalysts
Get help from experts in science and data, with a focus on business outcomes. Tetra Catalysts provide the “connective tissue” between scientific IT and scientists, increasing the value of your Tetra Scientific Data and AI Cloud deployment by 5-10x.
Tetra Partner Network
The Tetra Partner Network (TPN) is a global community of life sciences technology providers dedicated to unlocking the power of pharmaceutical R&D and manufacturing data to accelerate the delivery of life-changing therapies. TPN multiplies the value delivered to customers and provides vendor-agnostic access to the power of the Tetra Scientific Data and AI Cloud.
Updated 4 months ago