Disaster Recovery
Disaster Recovery Service
Disaster Recovery (DR) is an optional service that is not included by default in the development, test, or production environments. To learn more about this option, please contact your TetraScience Account Manager.
High availability (redundant components) and periodic backups are already included in the standard product and do not require the DR option.
The Disaster Recovery (DR) option sets up the infrastructure required for resuming operations on a secondary site (DR site), following a disaster (for example, earthquake, flood, or terrorist attack) that has greatly impaired the main production site (PROD). The assumption is that all resources in PROD, including backups, are no longer available.
Disaster Recovery Configuration
The following diagram depicts TDP Disaster Recovery configuration.
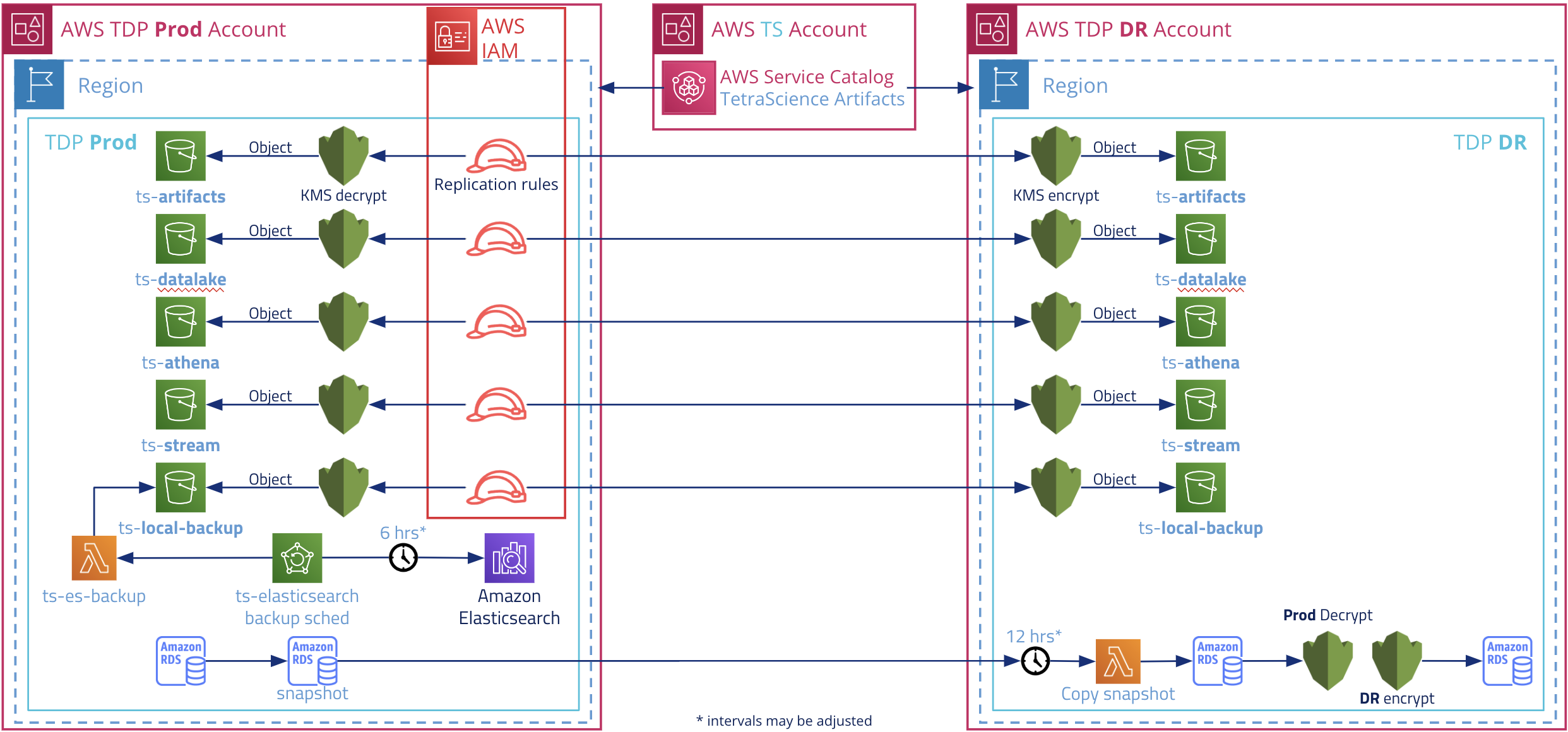
Recovery Timeframes and Replication Methods
This section outlines the Recovery Point Objective (RPO), Recovery Time Objective (RTO), and the Data Replication Methods.
RPO Timeframes
The RPO (Recovery Point Objective) is the maximum acceptable data loss, measured in time from the moment of disaster.
Standard RPO timeframe for platform components are in the following table.
NOTE
The standard RPO time for some components can be decreased, if needed. For details, contact your TetraScience Account Manager.
Standard RPO Timeframe for Platform Components
| Component | RPO Values |
|---|---|
| Raw and processed files in the Data Lake | 10 Minutes |
| Database with all configurations | 12 Hours (can be decreased)* |
| Elasticsearch index | 6 Hours (can be decreased)* |
RTO Timeframe
RTO (Recovery Time Objective) is the maximum acceptable time interval between DR initiation and the resuming of operations.
The estimated RTO is 12 hours.
Data Replication Methods
The data replication methods from PROD to DR are:
- Data Lake AWS S3 Bucket - Replicated via AWS S3 Cross-Region Replication (CRR). CRR is always on. For more details, see [Amazon C3 CRR Documentation].(https://docs.aws.amazon.com/AmazonS3/latest/userguide/replication.html).
- RDS Database - Periodically backed up with snapshot that is copied to the DR site.
- Elasticsearch Cluster - Periodically backed up in a bucket that is also replicated via the S3 CRR.
Configure the Disaster Recovery Environment
PREREQUISITES
- It is recommended that the DR environment be configured during the initial installation of PROD. It is possible to configure DR later on, but only via a manual process.
- Obtain a separate AWS account that will be used for DR. The DR account must be in a different region than the one used for PROD.
- Perform the platform pre-deployment tasks in the DR Account. The DR account should be as similar to production as possible: same number and subnet sizes, same VPC parameters, same AWS service quotas increased(if any), same internal stacks deployed, if any.
To set up DR in a new environment.
- Deploy in the DR Account and DR region the dr.yaml cloudformation template - see step 9 of the platform pre-deployment tasks. The stack will create S3 buckets that allow prod to replicate data to them and the new KMS encryption keys. The stack outputs will be required as input for the main production deployment.
- Perform the main production deployment, using the above parameters as inputs for the Data Layer product.
- In the DR Account and Prod Region (NOT DR region) deploy the snapshots_tool_rds_dest.json template. This template creates lambdas and a state machine that copies RDS snapshots cross-account from production to the DR account and region.
- A new AWS Service Catalog portfolio containing the latest TDP version will be shared by TetraScience with the DR Account and it will be imported there.
- All updates shared by TetraScience with the production account will be also shared with the DR account.
- TetraScience will give the DR environment access to the same artifact namespaces and env vars as production.
Perform Disaster Recovery (After a Disaster Has Occurred)
Starting the DR environment is basically a new platform installation. But instead of starting with an empty configuration that has no data, the new platform uses the replicated data and configurations from the PROD instance.
To recover data after a disaster has occurred:
- In production, make sure data is no longer replicated from the prod S3 buckets to DR. Manually edit source bucket configuration and disable replication.
- In the DR account, find the latest RDS snapshot and make a note of its ARN.
- In the DR account, check the existing S3 buckets and note their names.
- Perform a new deployment of the platform, using the standard procedure. The only exceptions are:
- For DataLayer, use the above snapshot ARN for the RDSSnapShot stack parameter.
- For DataLayer, use the above bucket names for DLBucket and STBucket, respectively.
- For ServiceLayer, you can use the same DNS name used in PROD and change the DNS to point to the new region, or use a different name.
- Login to the platform as platform admin and confirm all the orgs, their users and defined pipelines are present.
- Press the "AWS" button next to each organization shown in the platform UI.
- Secrets will have to be manually re-entered via the UI for all pipelines that use them.
- Get the datahub DB password from SSM, connect to the db and check the configuration of the datahubs of the old platform.
- Reinstall all datahubs and their agents from scratch, using the data in the DB as reference.
- To reindex data into Elasticsearch, run the ECS ts-core-reprocess-master task supplied with the platform to reindex data into Elasticsearch. The duration will vary, depending on the number of files in the Data Lake. Contact TetraScience to determine priorities and throughput. The number of task instances, parameters, and Elasticsearch nodes and types may have to be adjusted.
- To re-add data to Athena, run the same ts-core-reprocess-master ECS task, with an 'Athena' target. TetraScience will assist with this.
Updated over 1 year ago