Tetra UNICORN Agent FAQ
How Does the Tetra UNICORN Agent Work?
The Tetra UNICORN Agent performs four tasks:
-
Scan New The UNICORN Agent detects the new result file by scanning the entire address space specified in the Tetra UNICORN Agent Management Console. The scanning speed largely depends on the UNICORN server's capability.
-
Scan Change The Tetra UNICORN Agent detects the file change by checking its latest timestamp in the
Evaluation Logbookand the new content inEvaluation Notes. If the result file is updated, the Tetra UNICORN Agent flags the result file so that it can be regenerated. -
Generation The Tetra UNICORN Agent accesses the UNICORN HDA service, extracts the new and changed result files, and outputs the data as JSON-based raw files. Note that the Tetra UNICORN Agent prioritizes new result files over the updated result files.
-
Upload The Tetra UNICORN Agent uploads the raw files to the Tetra Data Platform. When the file is successfully uploaded, the Agent removes the raw file from the local folder to save space. For a reuploaded result file, it won't create a new file in the Tetra Data Platform, instead, it creates a new version of the existing result file. The UNICORN Agent uses the result file's HDA tag address as part of the file name.
Does the Tetra UNICORN Agent Interfere with the UNICORN Client if the Tetra UNICORN Agent is Deployed on the Same Machine?
Yes, it can interfere. Please deploy the Tetra UNICORN Agent on a different machine than the one used by the scientists as per the installation instructions.
How Can I Find the UNICORN HDA Address Space?
The address space depends on two things:
- The result files that have been created based on a specific instrument configuration.
- How the result file folder is set up in UNICORN.
TetraScience provides a freeware tool from Advosol Inc to help check the address. Here is how to run it:
-
On the machine that the Tetra UNICORN Agent is installed on, go to
[Tetra UNICORN Agent Installation Folder\Tools\HDATEstClientFW2. -
Run the executable:
HDATestClientNet2.exe.

Advosol Client
- Provide the Host Node (the local machine name, or use localhost, 127.0.0.1) and click Browse Servers.
- Select UNICORN_HDAServer12.1 and then click Connect .
- Click Browse under the BrowseTree Tab
- There have two folders containing the result files. Please be aware the folder name is case sensitive.
\Default\Folders\DefaultHome\Default\Folders\TetraScience
Troubleshooting Issues
If you tried the steps above, and you get a server connection error like the following, the error is usually an installation issue.

Server Connection Error
This error is usually thrown when the OPC Core Component was not installed correctly or the OpcEnum service was not running.
There are a few ways to fix this:
- Check if "OpcEnum" service is started in "Windows Services" window. It must be started and set to automatically start after system boots
- Run "Repair" on OPC Core Component distributable in the software management window.
- Reinstall OPC Core Component executable. Remove it from the installed software and reinstall it using the installer in "Tools" folder (Version
105.1is preferred).
NOTE
Folders can be defined differently based on the UNICORN configuration. The general rule is to start the address from the direct child of Root . For the case above, it is
\Default\.....
How can I Verify Whether the UNICORN OPC HDA Service is Ready?
You can easily verify whether the UNICORN OPC HDA Service is ready by completing the following steps.
- Check the service in the Windows Services Panel.

- Make sure this service is running and set the Startup type as Automatic.

Service Properties Window
- Verify whether the OPC HDA Service is accessible by following the previous question
- If UNICORN is set up as a centralized database structure, the account running the UNICORN HDA service should have at least read permission access.
If the OPC connection is not successful, what are the next steps?
TetraScience provides a freeware tool from Advosol to test the OPC connection. It can be found in [UNICORN Agent Installation Folder\Tools\HDATEstClientFW2.
If you are not able to see the UNICORN Folders, it is very likely there is an OPC connection issue.
Please check the following items
- Make sure the
Logon Required For HDA clientsis unchecked. The setting can be found from UNICORN Administration -> Tools -> Options -> OPC Settings - UNICORN HDA Service is running (From Windows Service Panel)
- OpcEnum Service is running (From Windows Service Panel)
How does the UNICORN Agent determine whether the result file is updated?
When the Tetra UNICORN Agent is up and running, it scans every resulting file under the address space defined in the Management Console (HDA Service) periodically (time interval). If one of the following data fields is changed, The Agent considers the result file is updated. The Agent will generate the result file and upload it to Tetra Data Platform again. There will have a new version of the file stored in Tetra Data Platform
- Total Length of Evaluation Notes
- Latest Evaluation Log Book Time Stamp
How does the UNICORN Agent determine whether the result file is ready to generate?
OPC Result file address space is created when the method starts. But the Raw data is not generated till the method finishes. To the generated Result file containing the Raw data, the Tetra UNICORN Agent waits till the method run completes. The logic to determine when the method run completes is to check the Run Logbook if it contains:
- End <date_time>
- Record Off <date_time>
What is the impact of "Detect changes for results created in last x Month/Days" on file generation? What dates are considered if this setting is enabled?
NOTE:
Detect Changes for Last x Month is the name of the setting for UNICORN Agent 3.6 and below. This setting name was changed to Detect Changes for Last x Days in UNICORN Agent 3.7 and above.
All of the Result files in the UNICORN HDA address folder will be extracted and uploaded to the Tetra Data Platform.
UNICORN usually accumulates the Result files back to years or even 10+ years. A lot of the old files do not need to be changed. To make the UNICORN agent run more efficiently, the Agent will not rescan the changes for the files back to a certain time. The user can determine what is the proper time for the Agent. If this setting is enabled, the maximum value allowed in 3.7.x is 1000 days.
The Result file has both Result File Creation Date as well as Evaluation Log Change Date. The Agent considers the earlier of the 2 dates and checks if that date is within the (current date - Detect Changes for results created in last X days). There are some edge cases to consider:
- If a result file is imported into UNICORN, the Result File Creation Date is the date of import. In that case the Evaluation Log Change Date is considered for the comparison (since that will be earlier than date of import). Now, if the same result file is updated, and the Evaluation Log Change Date becomes current date, the Result File Creation Date (i.e. the date the result file was imported into this UNICORN system) is considered for the comparison.
How to calculate Peak End value?
Due to a bug in the OPC HDA interface of UNICORN, the Peak "Start" and Peak "End" have the same value. The workaround to address this is to calculate the Peak End as Peak Start + Peak Width (both values are present in "PeakTable" object in UNICORN and RAW JSON).
What are the UNICORN Agent output files and the archive strategy?
| Agent Service | Output File type | Output Folder | Archiving |
|---|---|---|---|
| UNICORN HDA Service | Raw File | Specified by user in Management Console. The default is C:\temp\ | File will be removed after they are successfully uploaded |
| UNICORN HDA Service | Agent Log File | Logs folder under the Agent installation folder | The Agent logs will be archived in every minute. The log files are archived to logs\archive folder. Then the Agent will upload the log files to Platform periodically.When succeeded, the logs will be moved to backup folder which is under the logs\archive\ folder.The log files in the archive folder will be clean up in 72 hours. |
| UNICORN AE Service | Stream File | Specified by user in Management Console. The default is C:\temp\Output | File will be removed after they are successfully uploaded |
| UNICORN AE Service | Agent Log File | Logs folder under the Agent installation folder | The Agent logs will be archived in every minute. The log files are archived to logs\archive folder. Then the Agent will upload the log files to Platform periodically.When succeeded, the logs will be moved to backup folder which is under the logs\archive\ folder.The log files in the archive folder will be clean up in 72 hours. |
How to export result files from UNICORN?
If you need to provide sample result files to TetraScience, export the result file from UNICORN Evaluation.

Here is how to do this:
- Open UNICORN Evaluation
- Select the file(s) from Result Navigator. To select several results, press Shift while you click the results
- Right-click the selected file(s) and select Export ... from Context Menu.
- The Export to Another UNICORN Database dialog opens if one result was chosen. The Browse For Folder dialog opens if several results were chosen.
- The result files are exported as compressed .zip files.
- Click Save in the Export to Another UNICORN database dialog or OK in the Browse For Folder dialog.
- The result is saved as a ZIP file. If several results were exported, each result is saved as an individual ZIP file.
More on the Upload, Scanning, and Generation Processes
Upload Process
The file upload sequence is based on the file age. Younger files are uploaded earlier. When the file is uploaded to TDP successfully, the outputted GZ file will be deleted from the temporary folder.
The file path for uploads in S3 is: /<orgSlug>/<AgentId>/<DomainName>/<ProdId>/<Path_Of_HDA_Result_File>.json
For example: /myOrganization/7659ef3a-95e9-4e4c-9742-eaf18e4a8af8/v3.2/UNICORN_HDAServer12.1/Default/Folders/DefaultHome/myFiles/Pure - Unicorn 6 example result.json
Scanning Process
Running at the pre-defined scanning interval, the UNICORN Agent traverses the OPC Address Path to collect the paths of the Result Files that the Agent has permission to access. By comparing the full OPC Paths, (i.e \Default\Folders\DefaultHome\myOrg\MyFile1720 SPPD-20-0060\MyFile 11Mar2020\ ) the files are fetched from the OPC HDA service and the existing data is stored in the UNICORN Agent's SQLite database.
The Result file name is the combination of the full folder path and the Result file name (i.e. Default\Folders\DefaultHome\MyOrg\MyFile-Unicorn 6). The Agent searches the Result File’s HDA path with the records stored in the SQLite database. If not found, the files are treated as new files.
Result file RAW JSON Generation
The Tetra UNICORN Agent passes user credentials to access OPC HDA as additional parameters when they are available. The Agent generates the Result files based on user credential accesses. During the regeneration process, the new result files are generated if the Result File is complete.
Note that there are two ways to determine file changes.
- Evaluation Logbook change
- Evaluation Notes change
UNICORN Agent updates the Result file’s TraceId/FileId when regenerating the Result File. It creates a new version of the Result file when uploaded to TDP.
Result Files Evaluation Date
This date is either the Result Creation Date or Last Evaluation Logbook time stamp, whichever is earliest.
The UNICORN Result files come from two sources.
- Generated by the experiment run
- Imported from another source
Usually, the Result Creation Date is earlier than the Last Evaluation Logbook date. When the Result files are imported, its Result Creation Date in UNICORN is the current date time. UNICORN doesn’t apply the original Result Creation Date, so the Result Creation Date is later than the Evaluation Logbook date. To provide a more accurate time when the Result time was created originally, we use the Evaluation Date.
A flow chart that shows this process appears below.

Generation Flow Chart
Note that the format of the can vary, depending on the Region Setting in Windows where the Result files were captured. The following formats are supported by UNICORN Agent.
| Date time format | Example |
|---|---|
| MMM dd yyyy | Jan. 15 2022 |
| MMM dd, yyyy | Jan. 15, 2022 |
| dd-MMM-yyyy | 15-Jan.-2022 |
| dd/MMM/yyyy | 15/Jan./2022 |
| MMM dd yy | Jan. 15 22 |
| MMM dd, yy | Jan. 15, 22 |
| dd-MMM-yy | 15-Jan.-22 |
| dd/MMM/yy | 15/Jan./22 |
| MM.dd.yyyy | 01.15.2022 |
| MM-dd-yyyy | 01-15-2022 |
| MM dd yyyy | 01 15 2022 |
| MM/dd/yyyy | 01/15/2022 |
| dd.MM.yyyy | 15.01.2022 |
| dd/MM/yyyy | 15/01/2022 |
| dd-MM-yyyy | 15-01-2022 |
| dd MM yyyy | 15 01 2022 |
| M/dd/yyyy | 1/15/2022 |
| M.dd.yyyy | 1.15.2022 |
| M-dd-yyyy | 1-15-2022 |
| M dd yyyy | 1 15 2022 |
| yyyy/MM/dd | 2022/01/15 |
| yyyy-MM-dd | 2022-01-15 |
| yyyy.MM.dd | 2022.01.15 |
| yyyy MM dd | 2022 01 15 |
| dd.M.yyyy | 15.1.2022 |
| dd-M-yyyy | 15-1-2022 |
| dd M yyyy | 15 1 2022 |
| dd/M/yyyy | 15/1/2022 |
| yyyy/M/dd | 2022/1/15 |
| yyyy-M-dd | 2022-1-15 |
| yyyy.M.dd | 2022.1.15 |
| yyyy M dd | 2022 1 15 |
| d-M-yy | 1-15-22 |
| d/M/yy | 1/15/22 |
| d.M.yy | 1.15.22 |
| d M yy | 1 15 22 |
| yy-MM-dd | 22-01-15 |
| yy.MM.dd | 22.01.15 |
| yy/MM/dd | 22/01/15 |
| yy MM dd | 22 01 15 |
| M/dd/yy | 1/15/22 |
| M.dd.yy | 1.15.22 |
| M-dd-yy | 1-15-22 |
| M dd yy | 1 15 22 |
The JSON-based Raw file is generated and output to a temporary folder defined in Management Console. The file is compressed to GZ format.
Update Metadata or Tags
You can configure one or more metadata instances for ingested Result Files from the Address Paths in the Management Console.
-
Metadata is a key/value pair i.e. "{"instrument_name":"akta","instrument_id":"A001"}"
-
Tags are comma-separated strings, i.e. tag1,tag2,tag3
-
When the metadata is updated in Agent Management Console:
- It won’t impact the RAW JSON files already uploaded to TDP, It won't trigger reuploading the Result files.
- If the RAW JSON file has not been uploaded yet, the Agent will update the RAW JSON with the new metadata when uploading to TDP.
-
The user can set metadata on the Agent level from TDP too. Those metadata will apply to all of the files ingested from that Agent. When the RAW JSON is uploaded, the metadata from both TDP and Agent local will be merged.
If the same metadata (key) is defined in both places, the metadata configured in Agent Management Console will replace the one from TDP.
Consider the following example:

The Result files can be ingested from both paths. The metadata uploaded to TDP will be {"Test":"Path2"}.
What settings to impact result generation latency and number of OPC HDA logins into UNICORN?
For the agent, latency is the duration of time between the result completion in UNICORN and the corresponding RAW JSON getting ingested in TDP. Every time the agent needs to scan for result files or generate RAW JSON for new (or modified) result files, it connects to UNICORN through OPC HDA protocol. This results in a login and logoff event getting recorded in UNICORN System Audit Trail. Because the agent service continuously scans and generates, there may be a large number of such UNICORN System Audit Trail entries.
There are 4 levers that can be used to optimize the agent for result generation latency or the number OPC HDA logins it makes into UNICORN.
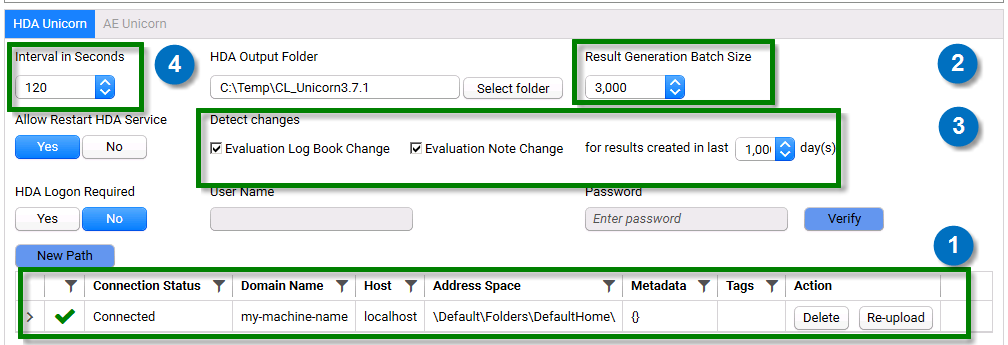
- The result files present in the address space specified has the biggest impact on latency. The larger the number of files, the greater is the latency.
- Result Generation Batch size - The Agent batches the generation of result files to optimize the number of OPC HDA connections it has to make to UNICORN. The default value is 1000 (i.e. using one OPC HDA login/logoff, the Agent will generate 1000 result RAW JSONs). Based on every UNICORN setup, this number may be tweaked from few hundreds to several thousands. OPC HDA has memory limitations and if the batch size is beyond several thousands, latency of result file generation will increase. A larger batch size will increase latency but it can also decrease the number of System audit Trail entries. To maintain a balance between both, we recommend using a value between 500 and 1000 during initial ingestion and 1000 to 2000 after that for the Result Generation Batch Size setting. This will reduce the number of System Audit Trails while maintaining latency.
- Detected change in X days - As UNICORN is used over time, the number of result files will continue to increase. To keep the number of result files the Agent needs to generate, this setting allows the user to define a threshold of last X of days, and if result files have changes during that time, the Agent will generate RAW JSON for those. Other, older files which have not been modified, will not be ingested. If this setting is enabled, the maximum value is 1000 days. If this setting is disabled, all result files in the address space specified will be candidate for generation.
- Interval in Seconds - This is interval after which the scan job will run again. The default time interval for the Agent to scan for changes is set to 60 seconds. If the client prioritizes low latency times, do not modify this value. However, in a “light” environment where there are fewer than 10000 Result files, the number of files generated per day is low, and there is a requirement to have fewer UNICORN System Audit Trails, this value can be adjusted to 30 minutes to an hour.
Explain HDA Logon Required setting
In UNICORN, for security, HDA logon can be enabled for any client (e.g. the TetraScience UNICORN Agent). This can be enabled or disabled in UNICORN by checking or unchecking Logon required for HDA clients setting in UNICORN Administration → Tools → Options → OPC Settings.
The Agent also has a corresponding setting in the management console called HDA Logon Required. Once the Logon required for HDA clients setting in UNICORN is enabled, remember to enable HDA Logon Required in Agent.

This table shows the connection behavior under different scenarios when the settings are enabled/disabled in UNICORN software or Agent and correct or incorrect username/password is configured in Agent.
| UNICORN setting for: Logon required for HDA clients | Agent setting for: HDA Logon required | User name/password configured in Agent | Status on clicking Verify | Connection Status for Address Spaces |
|---|---|---|---|---|
| No | No | Not applicable | Not applicable | Connected |
| No | Yes | Incorrect user name/password | Invalid | Not Connected |
| No | Yes | Correct user name/password | Valid | Connected |
| Yes | No | Incorrect user name/password | Valid | Not Connected |
| Yes | No | Correct user name/password | Valid | Not Connected |
| Yes | Yes | Incorrect user name/password | Invalid | Not Connected |
| Yes | Yes | Correct user name/password | Valid | Connected |
What happens when the HDA user is locked in UNICORN?
If the HDA user is locked in UNICORN, then upon providing the user name/password (even if it is valid) in the Agent management console, the Invalid message will appear when Verify button is clicked. Any paths configured for Address Spaces, will show a red icon and Not Connected status. The Agent will not be able to scan/generate any files when the HDA user is locked in UNICORN.
Explain impact in “Total Generated” number in Summary tab when Address Space is changed
In the Summary tab of the Agent management console, the Total Generated is the total number of result files that the Agent has generated from the address spaces that have been configured and the Agent has access to. If any of the address spaces are changed to a different path, the Total Generated value will be the sum of result files from the previous address space and the new address space.
Updated about 1 year ago