Tetra Snowflake Integration
IMPORTANT
The Tetra Snowflake Integration is in beta release currently and is activated for customers through coordination with TetraScience. The feature may require changes in future Tetra Data Platform (TDP) releases. For more information, or to activate the Tetra Snowflake Integration in your TDP environment, contact your customer success manager (CSM).
The Tetra Snowflake Integration allows you to access your Tetra Data directly through Snowflake, in addition to the TDP SQL interface.
Architecture
The following diagram shows an example workflow for the Tetra Snowflake Integration.
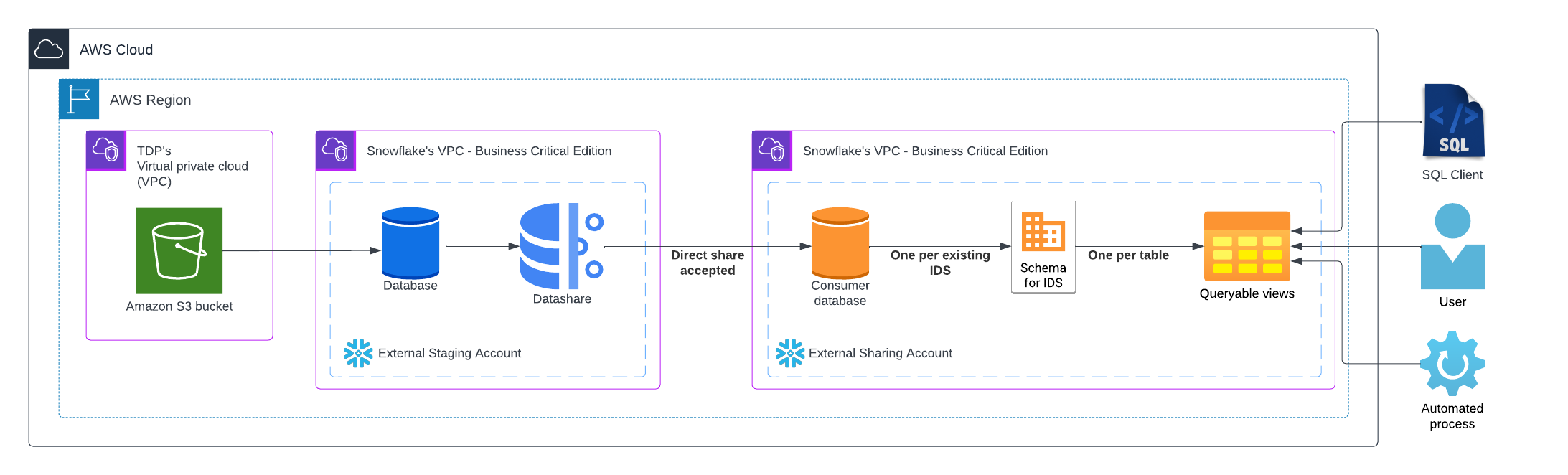
Tetra Snowflake Integration workflow example
The diagram shows the following process:
- Tetra Snowflake Integration components connect to the Amazon Simple Storage Service (Amazon S3) bucket that stores Intermediate Data Schemas (IDSs) and their associated Amazon Athena tables. Tetra Data that’s stored in the Tetra Scientific Data Cloud is exposed to a Snowflake database in a External Staging Account that TetraScience manages.
- A Snowflake database Direct Share securely shares data to a consumer Snowflake database in an External Sharing Account that's managed by the customer. One schema for each IDS version is shared along with a metadata schema. Each schema has its own queryable data views.
- Users can then access their organization’s Tetra Data directly through Snowflake, in addition to the TDP SQL interface.
Prerequisites
To use the Tetra Snowflake Integration, a Business Critical Edition Snowflake account is required in the same AWS Region as your TDP deployment.
Install the Tetra Snowflake Integration
To set up the Tetra Snowflake Integration, do the following.
Share Your Snowflake Account Information with TetraScience
TetraScience runs the automations required to set up the Tetra Snowflake Integration in your environment. To coordinate the deployment, contact your CSM and provide them with the following information about your Snowflake environment:
- Snowflake Organization ID
- Snowflake External Sharing Account ID
- Snowflake External Sharing Account AWS Region
Accept the Direct Share
To view Tetra Data in Snowflake after the integration is activated, you must explicitly accept the Direct Share from the integration by doing the following:
- Sign in to Snowsight with your Snowflake External Sharing Account as a user with ACCOUNTADMIN permissions.
- Select Data. Then, choose Private Sharing.
- Choose Shared With You.
- In the Direct Shares section, find the following Direct Share:
TDP_EXT_VIEW_SHARE_[ORG-SLUG] - Next to the name of the Direct Share, select the blue button. A Get Data dialog appears.
- In the Get Data dialog, for Database name, enter a short name for the shared database (for example, TETRA_SHARE). This is the database that’s used to query IDS data.
- For Which roles, in addition to ACCOUNTADMIN, can access this database?, select any additional roles in your Snowflake account that you want to grant database access to.
- Select the Get Data button. You can now query Tetra Data in Snowflake by using the shared database.
Access Tetra Data in Snowflake
You can access your Tetra Data in Snowflake after the Tetra Snowflake Integration is set up by using any of the available Snowflake database connection options.
For a complete list of connection options, see Connect to Snowflake in the Snowflake Documentation.
Schema Types
The Tetra Snowflake Integration creates two schemas in Snowflake for each IDS version:
- IDS schemas: Contain queryable views of each IDS version’s data that map 1:1 to the existing SQL tables in the TDP through Amazon Athena (available views differ between each IDS)
NOTE
IDS schema names in Snowflake use the following format:
<CLIENT | COMMON | PRIVATE>_<IDS-NAME>_<IDS-MAJOR-VERSION>_DATA
- Metadata schemas: Contain queryable views of the TPD metadata (
METADATA_FILE_INFO) and attributes (METADATA_FILE_ATTRIBUTE) associated with each file in the TDP across all file categories
Schema Structure
In the TDP, multiple SQL tables are created for each IDS that you're using, based on the sections (partitions) within each IDS. Knowing how these SQL tables are structured and how they’re converted into views in Snowflake can help you find specific data when running SQL queries.
For more information about how IDS files are converted into SQL tables, see TDP Athena SQL Table Structure. For information about how TDP Athena tables are converted into views in Snowflake, see Differences Between IDS Schema Views and TDP SQL Tables.
Differences Between Schema Views and TDP SQL Tables
To make TDP SQL tables queryable data views in Snowflake, the Tetra Snowflake Integration creates and shares one schema per IDS version along with a metadata schema. Each of these schema types has its own queryable data views that align with the SQL tables in the TDP, but are organized somewhat differently.
IDS and Metadata schema views in Snowflake differ from TDP SQL tables in the following ways:
- Each IDS version has its own schema.
- Each IDS version’s
roottables, subtables,datacubes, anddatacubes_datatables are all converted into views within the same IDS schema. For more information, see IDS-Specific Tables. file_info_v1andfile_attribute_v1tables are converted into views namedMETADATA_FILE_INFOandMETADATA_FILE_ATTRIBUTE, and are located in a single metadata schema for the entire shared database.- The
METADATA_FILE_INFOandMETADATA_FILE_ATTRIBUTEviews include the following additional columns, which aren’t included in their associatedfile_info_v1andfile_attribute_v1tables:file_name: Shows the name of the underlying filefile_modified_at: Shows when was the file info entry was last modifiedloaded_at: Shows when Snowflake registered that the file was created or updated- (For
METADATA_FILE_ATTRIBUTEtables only)org_slug: Shows the organizational slug associated with the file attribute entry
IMPORTANT
TDP SQL table names sometimes appear differently in views, because of Snowflake’s Identifier requirements. For example, in the
METADATAFILE_ATTRIBUTEview, the value column is converted tovalue_,groupdisplays asts_group, and2d_barcodedisplays asts_2d_barcode.
Updated over 1 year ago