Tetra IDBS E-Workbook Connector
The Tetra IDBS E-Workbook is an integration to IDBS’s E-Workbook ELN. The integration is driven by a user external action from within the E-Workbook’s spreadsheets, and can facilitate data transfer between IDBS E-Workbook spreadsheet and the Tetra Data Platform (TDP).
Architecture
The following diagram shows an example workflow for the Tetra IDBS E-Workbook Connector.
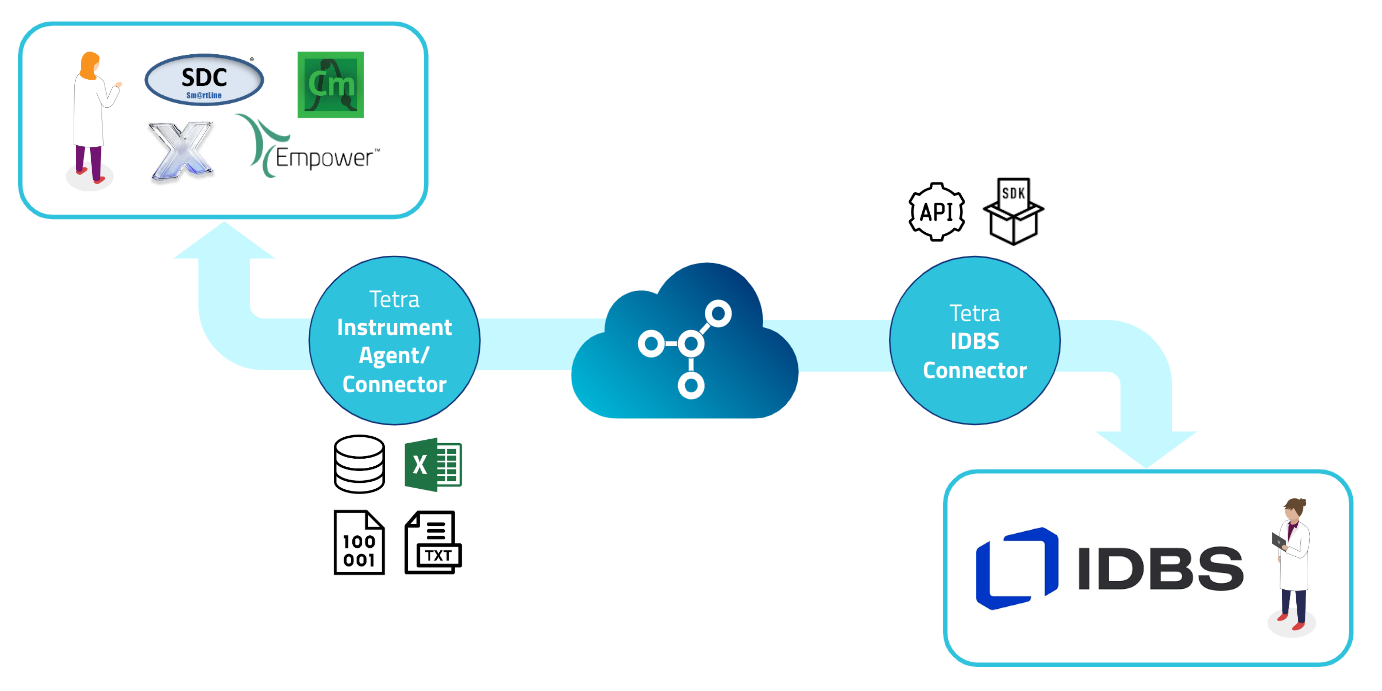
Figure 1. Illustration of data flow from instruments to the Tetra Data Platform (TDP), and to the IDBS E-Workbook
The diagram shows the following process:
- Scientists begin an experiment preparation in their IDBS E-Workbook spreadsheet, and initiates an action to send the spreadsheet data to TDP.
- TDP pipelines transforms this data into an experimental method to be sent to other Tetra Connectors/Agents to be transferred to a compatible instrument control system.
- Scientists starts experiment with method information pre-populated, and initiates data generation from the instruments that are integrated with the TDP.
- Tetra agents and connectors upload the data to the TDP.
- After the data is ingested by TDP and transformed into a harmonized IDS, IDBS E-Workbook users can simply press a custom action button in the IDBS E-Workbook spreadsheet to populate it with data pulled from the TDP.
The Tetra IDBS E-Workbook Connector is responsible for executing steps 1 and 5 above and can be added as External Actions to a spreadsheet via the IDBS Spreadsheet Designer.
These actions are customizable in the Connector configuration via DataWeave scripts. Connector users with suitable privileges (administrator or DataWeave administrator in the connector’s terminology) can modify the DataWeave scripts themselves. The connector provides a user interface for editing and viewing existing DataWeave.
Prerequisites
To install the Tetra IDBS E-Workbook Connector, you must have the following:
- IDBS E-Workbook version 10.5.x or higher (on-premises or cloud based)
- Administrator permissions in both your IDBS E-Workbook and TDP environments
Installation and Upgrades
To install a new Tetra IDBS E-Workbook Connector, or to upgrade to the latest Connector version, see IDBS Connector - Installation and IDBS Connector - Admin Configuration.
Connector Concepts
DataWeave
The DataWeave language is a functional language for performing transformations between different representations of data. As we use it, it can take XML, CSV or JSON data and convert it to one of these formats. This gives us a powerful tool to allow individual customers to programmatically tailor exactly how their data in the TDP should be mapped to specific IDBS spreadsheets while minimizing the security risks that a language like Python might pose.
Actions, Scripts, and Templates
Action: An action is what is to be performed by the trigger of the IDBS E-Workbook Custom Action. An action will execute one or more scripts.
Script: A script holds the code logic (DataWeave or ElasticSearch Query) that is to be executed a part of an action call. A script must be part of a template.
Template: An organizational construct that holds the logical scripts for that specific template type.
A user starts by first selecting from a pre-defined list of template types, then saves their desired business logic encoded into each script, and finally sets up the IDBS E-Workbook Custom Action to call a specific template uuid and the associated action desired.
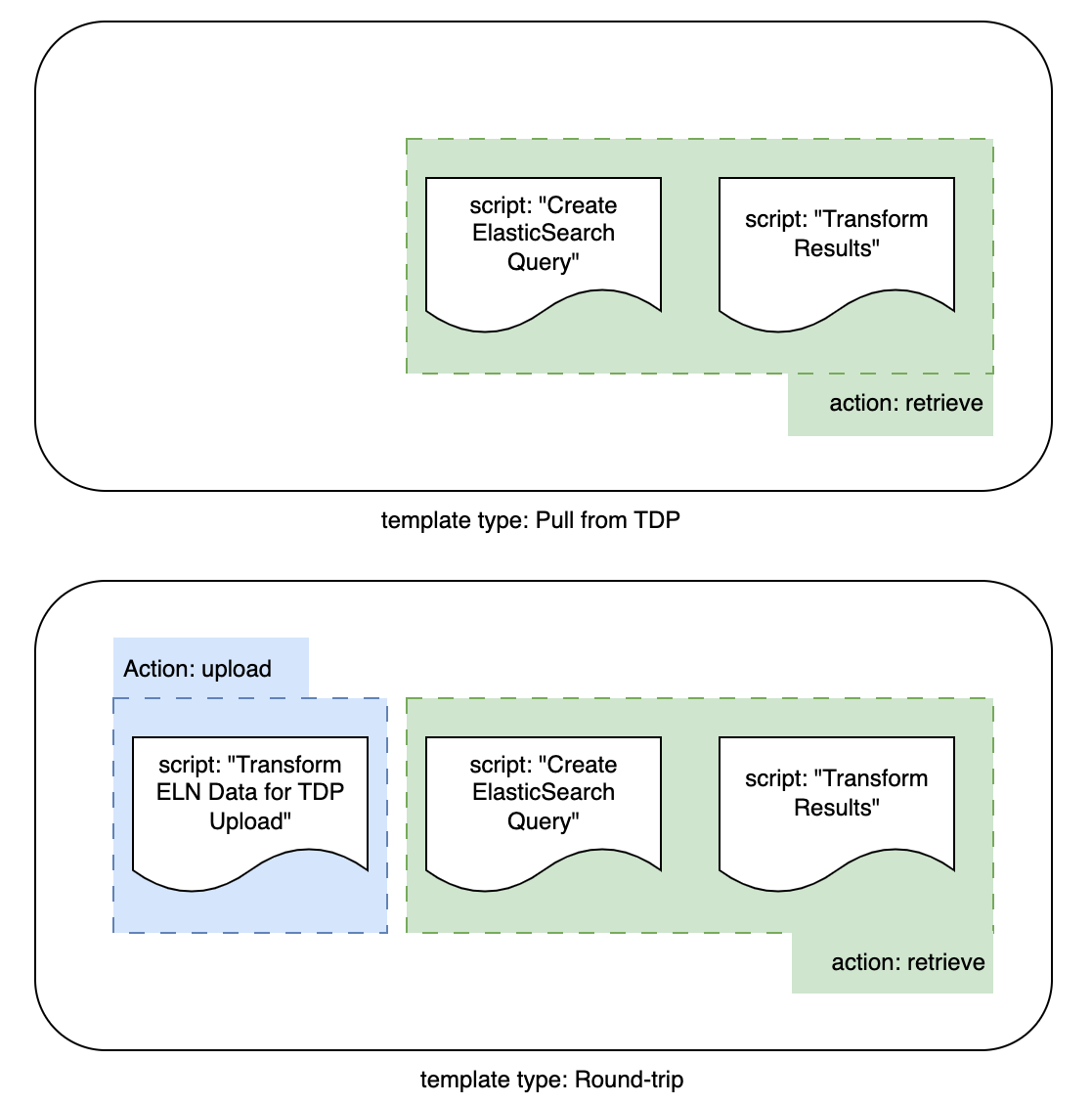
Figure 2. Illustrative representation of the relationship between actions, scripts, and templates
Action Dataflow
When the user performs an action from IDBS, the Connector will open a new tab to display executed activities.
The Connector performs the following activities for a Retrieve action:
- Login: Authenticates with IDBS
- Download: Retrieves spreadsheet data from IDBS
- Query: Uses data from IDBS and dynamically generates an Elasticsearch query to then send to the TDP
- Transform hits: Transforms the results/hits from Elasticsearch to IDBS format
- Resolve: This step allows the user to resolve conflict(s) and errors encountered by the transformation step
- Save: Saves the results in IDBS
Resolve
When conflict(s) and/or errors are encountered during transformation, the Resolve tab will display the information and allow the user to review and confirm selections. The following is an example of a transform that has both a conflict and an error:
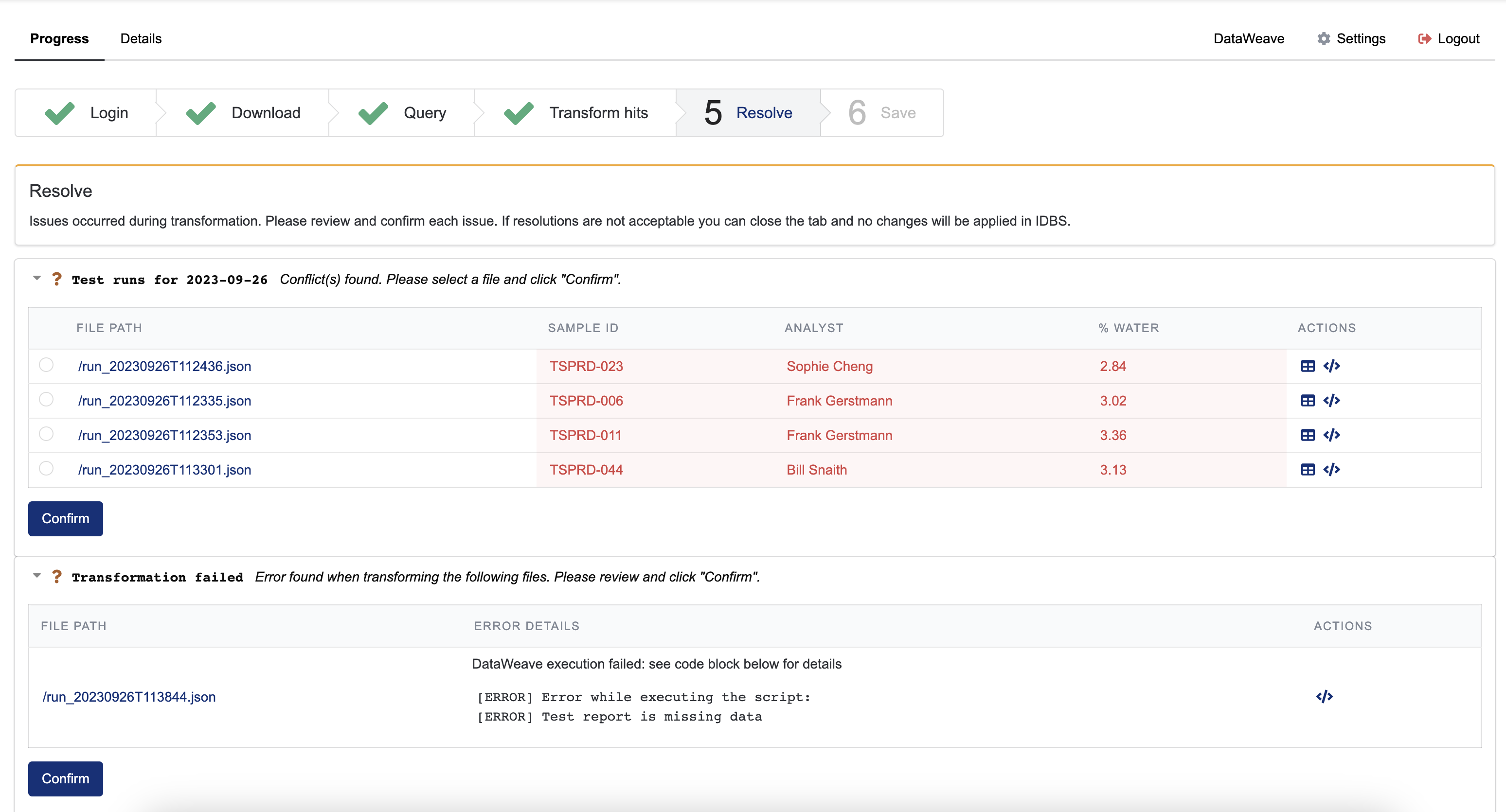
- A conflict occurs when multiple files in the TDP would write conflicting information in one or more cells in the spreadsheet.
- An error occurs when a result can't be transformed, such as problems with downloading files or missing data.
The user can review each issue and confirm the resolution.
Connector Action Configuration
Multi-Dimensional IDBS Spreadsheet Support
Tables in an IDBS spreadsheet can be more than 2-dimensional. Some of the connector features – particularly adding rows to a spreadsheet table – have only been fully tested for 2D tables. In IDBS, this corresponds to them having a single non-data dimension.
The IDBS Connector supports 2 actions that leverages customer provided DataWeave scripts for the business logic:
upload: Uploads the contents of the IDBS Spreadsheet to the TDP Data Lake with a custom file path and metadata / tags.retrieve: Searches the TDP Data Lake with custom elasticsearch queries constructed from the IDBS Spreadsheet contents, and allows for custom transform of the retrieved file content into a IDBS spreadsheet.
Actions
Table 1: Requirements for what scripts are needed per action.
| Actions | Script: Transform ELN Data for TDP Upload | Script: Create ElasticSearch Query | Script: Transform Results |
|---|---|---|---|
upload | ✅ | ||
retrieve | ✅ | ✅ |
upload
uploadSyntax
upload <template-uuid> toDatalake
NOTE
For
<template-uuid>, enter the key associated with the desired DataWeave template in the Connector.
Supported templates
- Round-trip
Description
This action sends a JSON representation of an IDBS spreadsheet to the TDP Data Lake. The file in TDP can have a custom path (or custom tags and metadata) set using one DataWeave script upload.
Maximum File Size Limitation
Upload files supports a maximum file size of 500 MB.
Configuration in IDBS
- Open a spreadsheet in the IDBS Spreadsheet Designer application.
- Go to Tools > Instruction Set Designer.
- Create a “Connect to TDP” action.
- In the Data to pass to Action section of the Instruction Set designer, enter
upload <template-uuid> toDatalake, where<template-uuid>is the key associated with the desired DataWeave template in the Connector.
retrieve
retrieveSyntax
retrieve <template-uuid>
NOTE
For
<template-uuid>, enter the key associated with the desired DataWeave template in the Connector.
Supported templates
- Round-trip
- Pull from TDP
Description
This action uses data from an IDBS spreadsheet to form a set of Elasticsearch queries to find data in TDP. After finding the data, the action then transforms the hits into an appropriate payload to send to IDBS. This action uses two scripts retrieve and query, described below
Configuration in IDBS
- Open a spreadsheet in the IDBS Spreadsheet Designer application.
- Go to Tools > Instruction Set Designer.
- Create a “Connect to TDP” action.
- In the Data to pass to Action section of the Instruction Set designer, enter
retrieve <template-uuid>, where<template-uuid>is the key associated with the desired DataWeave template in the Connector.
Scripts
Transform ELN Data for TDP Upload (upload)
upload)The upload DataWeave script can be used to generate file paths and custom metadata for uploaded files based on information from the IDBS spreadsheet.
Inputs
payload: information about the IDBS spreadsheet that initiated the action, and the experiment that it lives in. The payload will have the following structure:
type UploadPayloadData = {
spreadsheet: {
name: string,
id: string,
modelId: string,
tables: string[],
structure: SpreadsheetStructure
},
experiment: {
name: string, // name of spreadsheet in IDBS
id: string, // ID of spreadsheet in IDBS
path: string[], // path of folders to experiment in IDBS
}
}
type SpreadsheetStructure = {
[tableName: string]: {
dataDimensionName: string,
dimensions: {
name: string,
itemNames: string[]
}[]
}
}
{
"spreadsheet": {
"id": "63da1040857411eea5bd00000a000079",
"modelId": "6614f03085e411eea5bd00000a000079",
"name": "Template.ewbss",
"tables": [
"Cell Counter"
],
"structure": {
"Cell Counter": {
"dataDimensionName": "Data",
"dimensions": [
{
"name": "Data",
"itemNames": [
"Raw Data Lake Link",
"Sample ID",
"Total Cell Conc, 10^5 cells/mL",
"Viable Cell Conc, 10^5 cells/mL"
]
},
{
"name": "S",
"itemNames": [
"1",
"2",
"3"
]
}
]
}
},
"content": {
"tables": [
{
"name": "Cell Counter",
"ranges": [
{
"range": "",
"data": [
{
"S": {
"string": "1"
},
"Sample ID": {
"string": "sample-2023-01"
},
"Total Cell Conc, 10^5 cells/mL": {
"number": 258612
},
"Viable Cell Conc, 10^5 cells/mL": {
"number": 268066
},
"Raw Data Lake Link": {
"string": "https://tetrascience-uat.com/file-details/767948f4-46ae-4697-9b77-61d9fdb9fe84"
}
},
{
"S": {
"string": "2"
},
"Sample ID": {
"string": "sample-2023-02"
},
"Total Cell Conc, 10^5 cells/mL": {
"number": 262140
},
"Viable Cell Conc, 10^5 cells/mL": {
"number": 224281
},
"Raw Data Lake Link": {
"string": "https://tetrascience-uat.com/file-details/aa9ae909-33ca-481d-adc0-2a18a42255e8"
}
},
{
"S": {
"string": "3"
},
"Sample ID": {
"string": "sample-2023-03"
},
"Total Cell Conc, 10^5 cells/mL": {
"number": 249244
},
"Viable Cell Conc, 10^5 cells/mL": {
"number": 263782
},
"Raw Data Lake Link": {
"string": "https://tetrascience-uat.com/file-details/1bdc16db-b41a-4582-acc1-e41f098328ce"
}
}
]
}
]
}
]
}
},
"experiment": {
"id": "dc57d39084e311eea5bd00000a000079",
"name": "IDBS Workshop",
"path": [
"Root",
"Partners",
"Tetrascience",
"Jeremy",
"IDBS Workshop"
]
}
}
Outputs
The expected output from the DataWeave is expected to have the following form:
{
filePath?: string, // TDP file path; defaults to '/idbs/uploads/upload-<random-uuid>' if missing
sourceType?: string, // TDP source type, must be lowercase letters and hyphens; defaults to `idbs-eworkbook` if missing
metadata?: Record<str, str>, // custom metadata, ASCII characters only for key and val
tags?: string[], // custom tags, must be unique, ASCII characters (and no commas)
}
%dw 2.0
output application/json
---
{
"filePath": "idbs/upload-test/experiment/" ++ payload.experiment.name ++ "/spreadsheet-" ++ payload.spreadsheet.name ++ ".json",
"sourceType": "idbs-eworkbook-test",
"metadata": {"developer": "john-doe"}
}
Notice that all fields are optional – if you don’t need any customization, the upload script can return an empty object and use the default values indicated above for filePath and sourceType.
The actual contents of the uploaded file will be JSON, and they are the same as the spreadsheet piece of the payload but with the contents restored:
{
name: string,
id: string,
modelId: string,
tables: string[],
structure: SpreadsheetStructure,
content: SpreadsheetContent
}
type SpreadsheetContent = {
tables: {
name: string,
ranges: {
range: string,
data: SpreadsheetTableContent[]
}[]
}[]
}
type SpreadsheetTableContent = {
[dimensionName: string]: {string: string} | {number: number}
}
If you specify a file path that ends with a .json extension, you will be able to use file preview within TDP to inspect this JSON document in the platform.
Create Elasticsearch Query (query)
query)The query DataWeave script is used to dynamically generate one or more Elasticsearch queries to send to the TDP OpenSearch service. All unique hits from these queries will form the results to be transformed by the next step.
Note that for certain IDS types, the full Elasticsearch document returned can be quite large. To improve performance in the connector, consider optimizing your queries to only return the necessary fields for transformation. For documentation, see: https://www.elastic.co/guide/en/elasticsearch/reference/6.4/query-dsl.html4
Inputs
payload: information about the IDBS spreadsheet that initiated the action, and the experiment that it lives in. The payload will have the following structure:
type QueryPayloadData = {
spreadsheet: {
name: string,
id: string,
modelId: string,
tables: string[],
structure: SpreadsheetStructure,
content: SpreadsheetContent
},
experiment: {
name: string, // name of spreadsheet in IDBS
id: string, // ID of spreadsheet in IDBS
path: string[], // path of folders to experiment in IDBS
}
}
type SpreadsheetStructure = {
[tableName: string]: {
dataDimensionName: string,
dimensions: {
name: string,
itemNames: string[]
}[]
}
}
type SpreadsheetContent = {
tables: {
name: string,
ranges: {
range: string,
data: SpreadsheetTableContent[]
}[]
}[]
}
type SpreadsheetTableContent = {
[dimensionName: string]: {string: string} | {number: number}
}
config: holds information about the TDP and IDBS instances being used. The structure is:
type QueryConfigData = {
tdp: {
baseUrl: string,
orgSlug: string
},
idbs: {
baseUrl: string,
username: string // IDBS user who initiated the current external action
}
}
Outputs
The script should output a list of one or more valid Elasticsearch 6.4 queries. All queries in the list will be performed through TDP, and all hits corresponding to unique TDP fileId will be passed on to a later step.
An error will be thrown if:
- any single query in the list fails – for example, a single malformed query will prevent you from proceeding
- all queries combined produce 0 total hits. An individual query may yield 0 hits with no error.
Transform Results (results)
results)The results DataWeave script is used to transform the Elasticsearch hits into the correct form to send to IDBS to update a spreadsheet. By default, all files are downloaded, and each hit is transformed individually, resulting in latency proportional to the number of hits returned by the query. However, there are options available to improve performance:
- Skip Retrieve: If the information in the indexed Elasticsearch document is sufficient, and you don't need to download files from the TDP or access data stored in datacubes, you can skip downloading files from the TDP. The advantage of this option is that individual transforms can fail or succeed separately. If at least one transform succeeds, you still have the option to proceed with writing results to IDBS. The Skip Retrieve option still incurs the overhead of individual DataWeave executions and is not suitable for transforms that combine multiple hits.
- Single Transform: This option skips downloading files and performs transforms in a single DataWeave execution, providing the highest performance. In single transform mode, all of the Elasticsearch hits are provided to a single DataWeave execution and transformed at once. However, the entire transform either succeeds or fails as a unit, and no individual file/hit error handling is available.
Special options can be enabled by using special comments in the DataWeave script. These comments can be placed anywhere that a comment is syntactically valid in DataWeave, but it's recommended to place them in the header section, just beneath the %dw 2.0 line.
The comments must have the following form:
- To enable single transform, use
//@ts-single-transform - To enable skip retrieve, use
//@ts-skip-retrieve
NOTE
If you use both options,
//@ts-single-transformtakes precedence.
Inputs
Default (download all files, multi-transforms):
payload_1: A single hit from Elasticsearchpayload_2: The full file corresponding to the hit given inpayload_1payload_3: The contents of the IDBS spreadsheet that initiated the action
If using Skip Retrieve or Single Transform:
payload_1: The list of hits from Elasticsearch. For Skip Retrieve, this will be a list containing a single hit. Looking at the body of the Elasticsearch response, this corresponds tohits.hits.payload_2: The contents of the IDBS spreadsheet that initiated the action. This will have the typeGetADTResponseBody.
Output
This script should put out a list of spreadsheet updates. The expected format of these is:
type SpreadsheetUpdate = {
id: string // see below for significance of this field
fileId: string, // TDP fileId related to this spreadsheet update
filePath: string, // TDP file path related to this spreadsheet update
tables: SpreadsheetUpdateContent[], // Spreadsheet update table content
summary?: any // see below for significance of this field
};
// Note that the actual format of `tables` is more restrictive than this.
// Entries of tables should alternate between names and content
type SpreadsheetUpdateContent = SpreadsheetUpdateTableName | SpreadsheetTableContent[];
type SpreadsheetUpdateTableName = {
name: string,
range?: string
};
// `dimension` in IDBS means an index for a cell. Right now, if you want to
// add rows to a table, you do so by referencing the row's index and setting
// it to null. The connector interprets this as needing to add a row along
// that non-data dimension.
type SpreadsheetTableContent = {
[dimensionName: string]: {string: string} | {number: number} | {index: number | null}
};
After the updates are created, the connector will run them through a validator to make sure that they have the correct format. The updates will also be checked for conflicts, where a conflict is defined to be a place where the connector is attempting to write two or more inconsistent values to a given table cell. The connector provides a conflict resolution interface to allow the user to choose which value should apply.
- The
idfield above is used by the connector to group updates that might possibly conflict. Put differently, if two updates in the list have a different id, the conflict checker will not examine them for possible conflicts. DataWeave writers should adopt a convention where, for example, writes to the same table use a consistentid. - The
summaryfield controls what is shown in the connector’s Progress tab. For each result, the keys ofsummaryset the columns of the table displayed when you click on the result in the Progress tab; the values are what are displayed in that result’s cells. It is useful to provide values here that you can quickly inspect to handle any conflict resolution that is needed.
Templates
The actions supported by the IDBS Connector each use separate DataWeave scripts at different steps of the process. Templates help organize DataWeave scripts into logical groupings as guided by business or scientific workflows. Two distinct types of templates are available:
- Pull from TDP: this template supports the retrieve external action from IDBS, and as the name suggests, is used to pull data from TDP into IDBS.
- Round-trip: this template supports both the upload and retrieve external actions from IDBS. The upload action gathers data from an IDBS spreadsheet and allows the user to upload the spreadsheet contents as a JSON file to the TDP Data Lake.
We describe the expected DataWeave interface for these individual scripts below.
IDBS Spreadsheet Table Whitelisting
IDBS spreadsheets may have a very large number of tables, many of which are not relevant to the operation of the connector in a particular scenario. For each template, the Table Whitelist allows for specification of a list of tables that are necessary for the actions of interest to be used, improving the performance of the connector.
- If populated, only the tables listed in the whitelist field will be downloaded into the connector and made available to the DataWeave scripts.
- Any tables listed in the whitelist that do not exist in the spreadsheet will be ignored silently, i.e., no error will be raised.
- If the table whitelist is left blank, all tables will be downloaded. This is the same behavior as earlier versions of the connector.
Unsupported Table Names for Whitelisting
Table Whitelist does not support table names that contain commas.
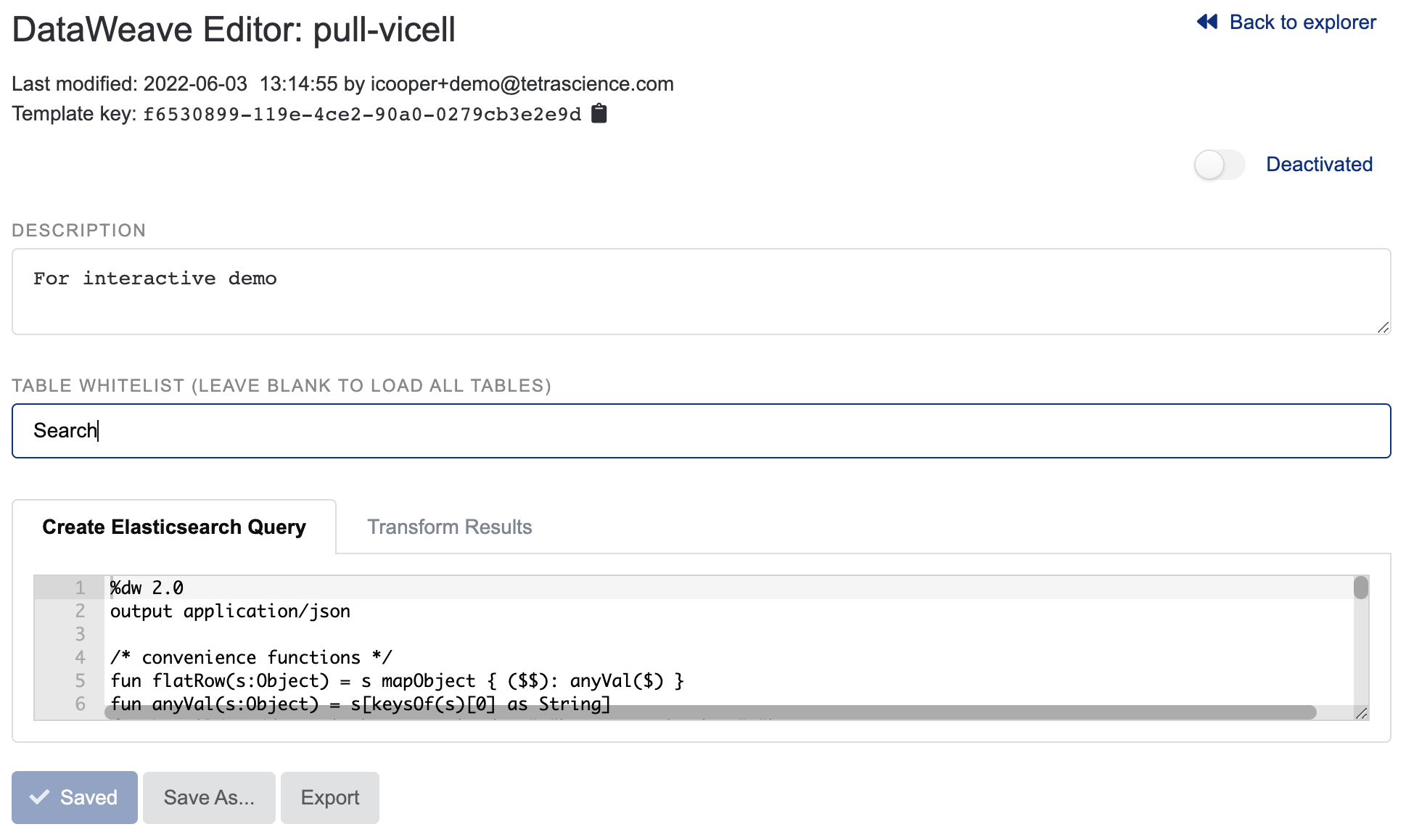
Figure 3. The DataWeave Editor with Table Whitelist Example
DataWeave Explorer
From the Connector Homepage, click on the DataWeave tab next to Settings on the menu to go to the DataWeave Explorer.
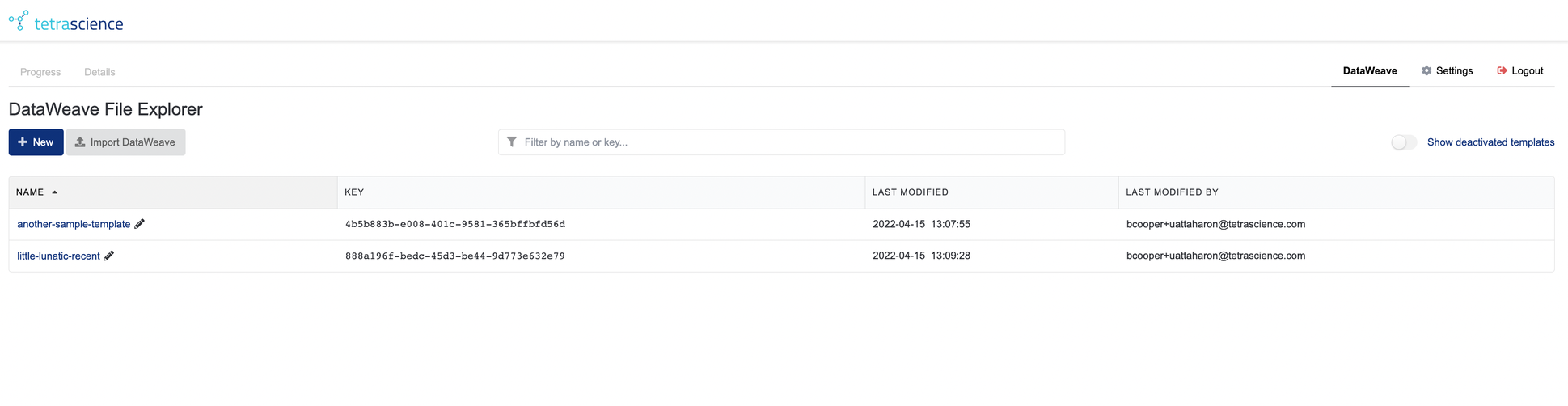
Figure 4. The DataWeave File Explorer with a few templates created
Each row represents an individual template. On the left is a descriptive name for the template; this is a link that will take you to an editor (described below) where you can change the contents of the template. The pencil icon next to each name allows you to rename templates. Template names may use lowercase letters, digits, and hyphens, and names must be unique. If you attempt to reuse an existing name, a small integer will be appended to the end of the name (similar to what a web browser does when saving downloads).
Other features of interest:
- Each row contains the template key (a system-generated UUID) used internally to refer to the template. This is the value that must be inserted when configuring the instruction set in the IDBS Spreadsheet Designer. Unlike the name, this cannot be changed.
Filter by name or keyallows the user to type characters, and will show all rows where either the name or key match those characters.Show deactivated templates, if active, will allow templates that have been deactivated to appear in the file explorer. A deactivated template is read-only and will result in an error if a spreadsheet attempts to use it for actual work. Templates can be deactivated (or reactivated) from the editor screen.
If you have no scripts, you can either create a new one or use the button to import an existing one (typically this will come from the connector export function from a different environment).
Clicking the New button will prompt you to first select a template type:
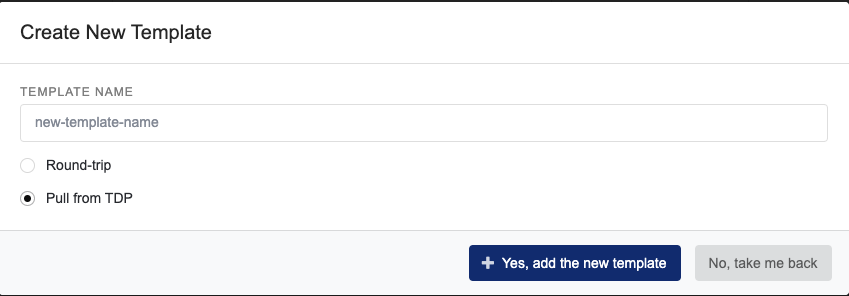
Figure 5. Create New DataWeave Template
Clicking the Import DataWeave button produces the following modal with text area for pasting in the exported JSON:
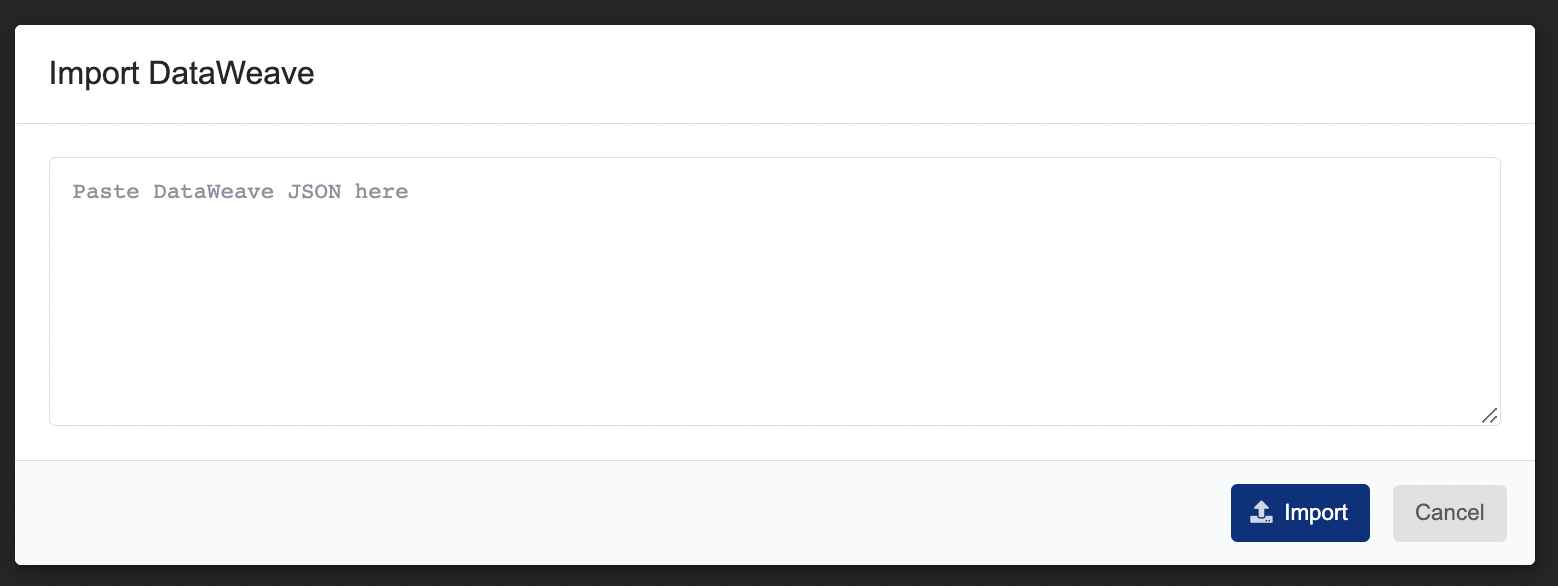
Figure 6. Import DataWeave Template Modal
DataWeave Editor
The DataWeave Editor allows users with appropriate permissions to modify and save the DataWeave scripts used by the connector. The editor has two panes: Create Elasticsearch Query, which extracts data from the IDBS spreadsheet and forms a query string to send to TDP’s Elasticsearch service; and Transform Results, which converts the results of this search back into IDBS spreadsheet updates.
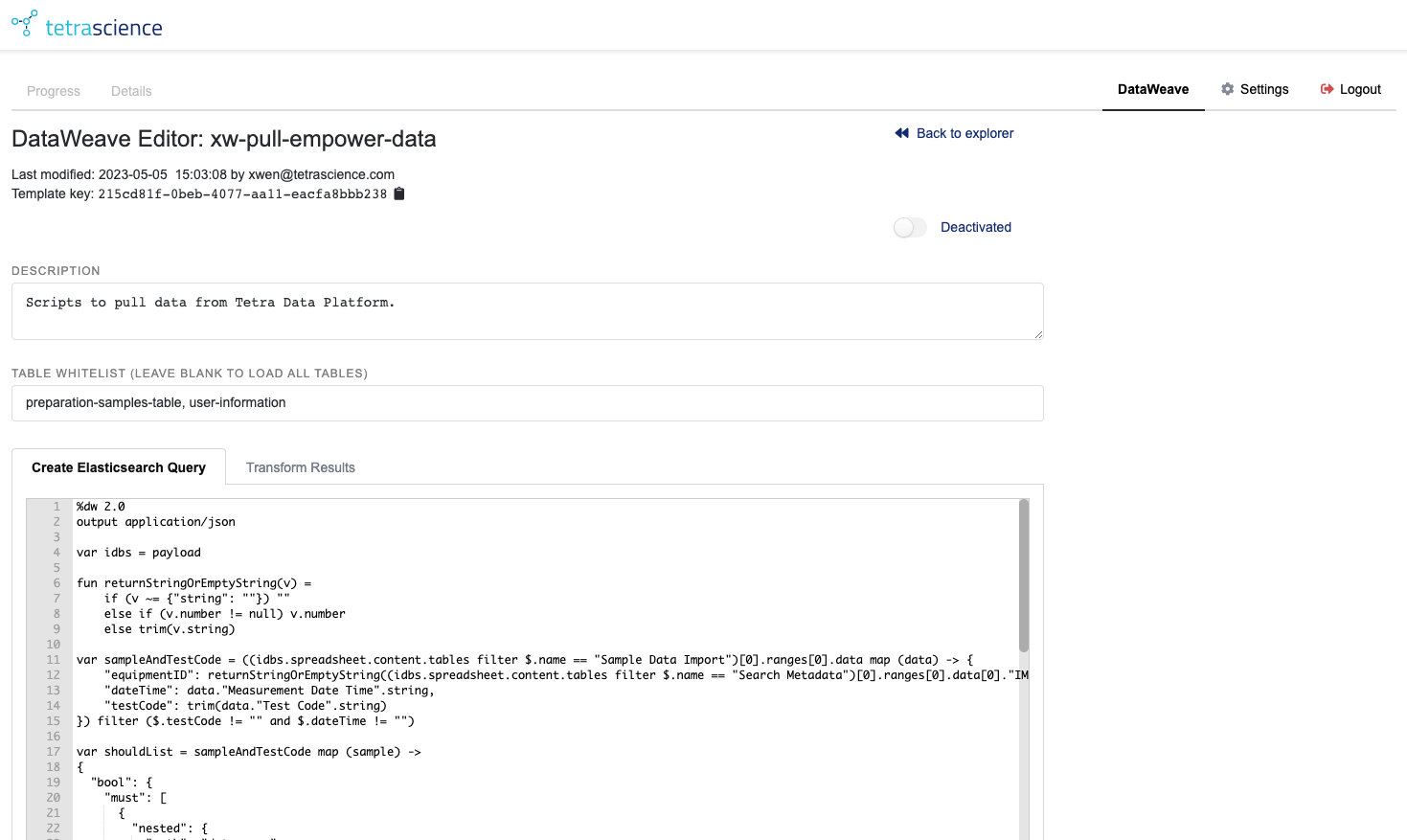
Figure 7. The DataWeave Editor
Feature highlights of the editor include:
- The name, template key, and last modified information of the current template are displayed in the upper left corner. In the upper right is a link to return to the DataWeave Explorer.
- The user may enter a description of the template in the Description text area. This description is visible in the explorer when an individual row is clicked.
- Above the description is a toggle that allows the user to deactivate (or reactivate) the template.
- Whenever the description, table white list, or script code is changed, the user must click Save in the bottom left to keep the changes. If there are unsaved changes and the user attempts to navigate away, the connector will prompt the user to ask if they wish to leave despite having unsaved data
Save As... allows the user to save a copy the template under a different name; this will also generate a new template key for the copy.Exportwill download the current template information to a filedataweave-export-<template-name>.json. The text from this can be copied and pasted into the text area in the import modal to move DataWeave templates between environments.
Connector Logs
The connector comes with two logs: an Audit Log, and a System Log. The Audit Log is not intended for troubleshooting, but rather exists for compliance reasons.
Audit Log
Audit Log Future Location Move
In a future major version release of the IDBS Connector, the Audit Log will be transferred to TDP automatically and viewable there along with all of the other agent and connector Audit Logs.
The Audit Log is intended to capture all changes to the connector that might affect how data is moved, including:
- connector version changes
- configuration changes
- login and logout information
- changes to DataWeave templates
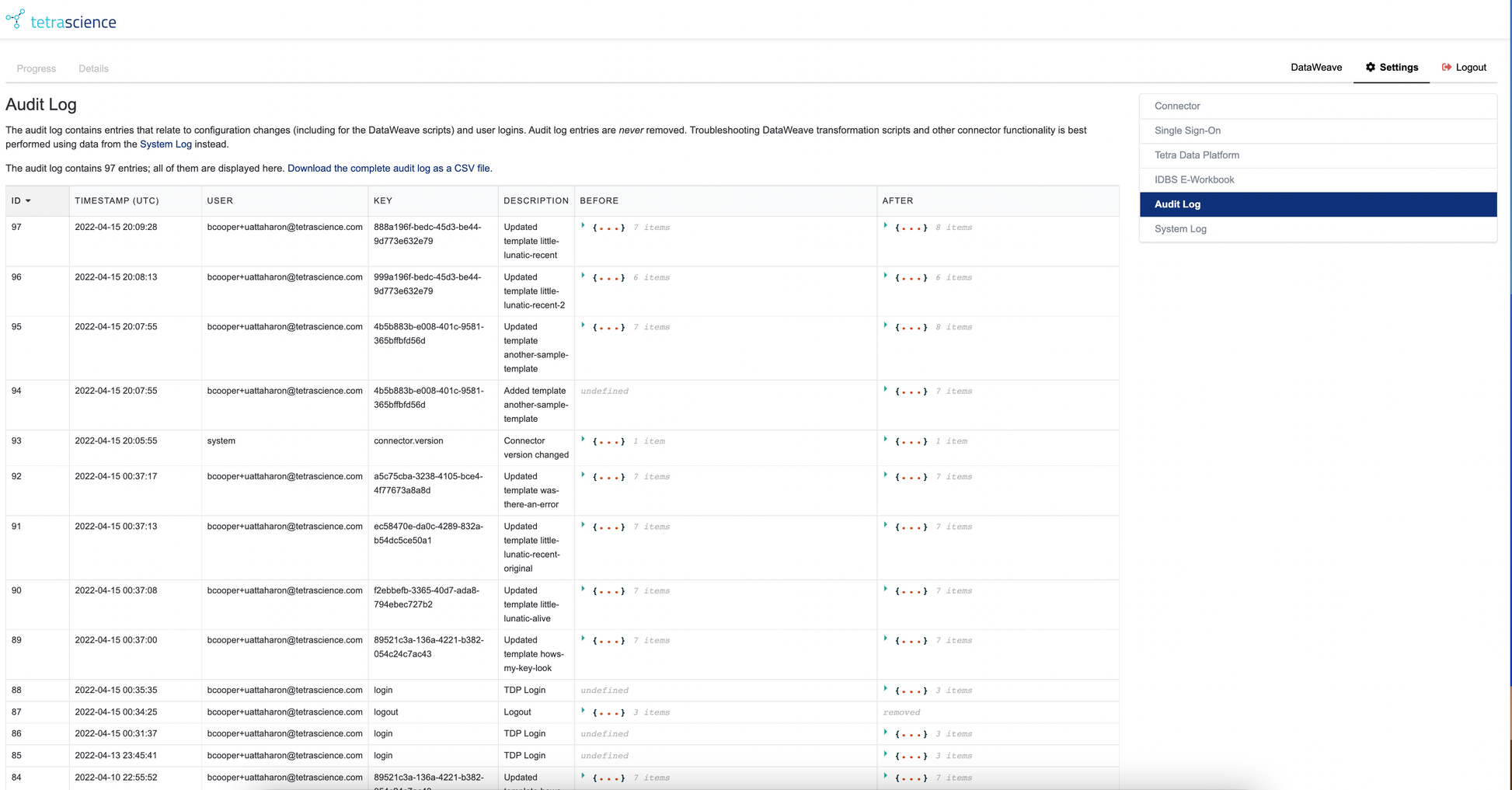
Figure 8. Connector Audit Log Screen
The Audit Log is never truncated, however, only the most recent 1000 entries will be shown in the browser. The link at the top of the audit log provides access to the full log. Currently, this lives in audit.db in the configuration volume of the connector.
The Audit Log records:
- a UTC timestamp of when changes occurred;
- what user made the change;
- what item changed (typically this corresponds to a key in the configuration database);
- a verbal description of what kind of change occurred; and
- the before and after status of the change. The JSON data associated with before and after versions can be inspected within the table.
Sensitive Information Stripping
Certain types of sensitive data (e.g. application secrets) are masked when writing to the Audit Log.
System Log
There System Log serves as a diagnostic tool for users to look for more information when they encounter a problem. Within the System Log screen, the Details tab is available when the connector session has data from a recent request from IDBS. The System Log looks very similar to the Audit Log:
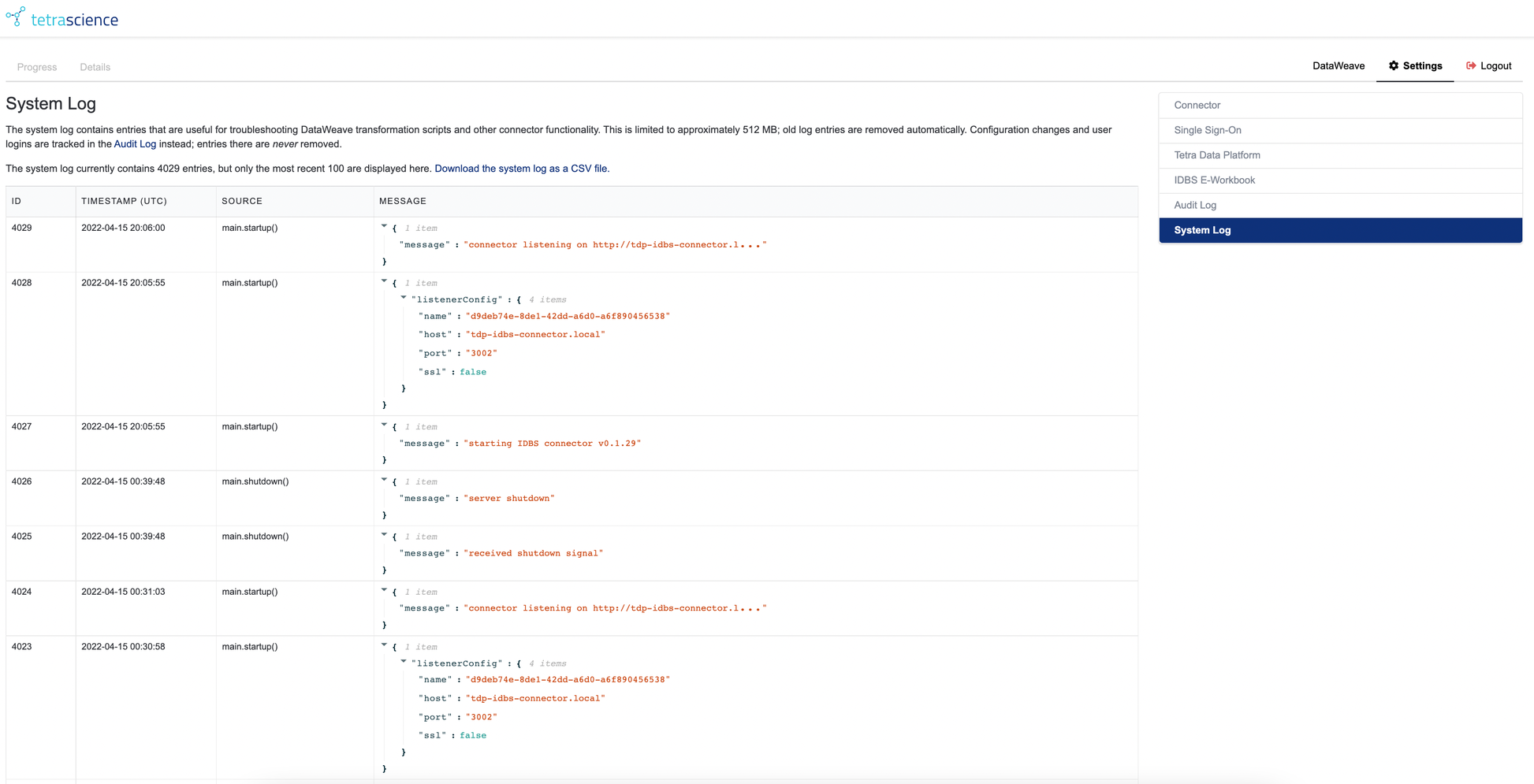
Figure 9. Connector System Log Screen
The System Log captures a large amount of internal data during the data retrieval process.
- Unlike the Audit Log, the System Log is regularly truncated to maintain a manageable size.
- Whenever the log exceeds 512 MB, the oldest entries are trimmed until the size is valid again.
The Details tab contains information about the current data retrieval job.
- It includes a variety of expandable sections which show things such as which DataWeave scripts are being used, the Elasticsearch query sent to TDP, the results of the DataWeave transforms, and other technical details about the transaction.
- It is very useful for developing new DataWeave scripts.
Updated about 1 year ago