IDS Conventions - schema.json
Location ChangedThe content of this page has been moved to TetraScience Confluence and it's not public-facing anymore. We will revise this page once self-service IDS is available.
IDS: Intermediate Data Schema, the schema itself
IDS JSON: a JSON file produced following an IDS
required: any use of the coded required refers to the required field in schema.json. Usually you don't need to add a field to the required array unless specified by the convention
Table of Content
- Platform Requirements
- TS Convention
- How to Create schema.json
Platform Requirements
| # | Rule | Checked by IDS Validator |
|---|---|---|
| General | ||
| 1 | All field names should be snake case (words connected by underscores, all lowercase) unless specified | Yes |
| 2 | Every object type field should always have "additionalProperties": false to prevent random fields from being added | Yes |
| 3 | If a field is in the required array of an object, it also needs to be defined in the object schema | Yes |
| 4 | Fields with type object or array cannot also have a second type. Fields with any other type may have a second type of null only | Yes |
| Top-level Fields | ||
| 1 | @idsNamespace, @idsType, @idsVersion need to be in the top-level required field value array and must not be null and must have a constant value | Yes |
| 2 | If datacubes is present, it has to have the required fields defined in the IDS Design Conventions - Schema Templates#datacubes-Pattern | Yes |
| 3 | If datacubes is present, maxItems has to equal to minItems, in both datacubes[*].measures and datacubes[*].dimensions | Yes |
| 4 | If datacubes is present, the shape of measures[*].value matches the number of dimensions (e.g. 2 dimensions → 2 layers of array in value) | No |
TS Convention
| # | Rule | Checked by IDS Validator (only for IDS designed by TS) |
|---|---|---|
| General | ||
| 1 | Most of the fields in schema.json should be nullable unless defined to be NOT NULL in Null Section or confirmed with the vendor that cannot be null | No |
| 2 | If a field indicates that it's a scientific measure, like "weight", "mass", "volume", you have to use the exact schema provided in IDS Design Conventions - Schema Templates#Value-Unit-Object | No |
| 3 | All scientific units should come from TS unit library(not accessible publicly) | No |
| 4 | All ID-like fields must be string type, user ID, instrument ID, sample ID, etc. | No |
| 5 | Combine fields that has the common key prefix into one single object by extracting the prefix as the parent key | Yes, warning if not followed |
| 6 | Any IDS field called name should follow this convention: If the value is derived from the raw file, use the raw file's name. If the value does not come from the raw file, use all lower case and separate words with spaces | No |
| 7 | Make the field name singular if its value is not an array | No |
| 8 | Make the field name plural if its value is an array | No |
| 9 | For fields with a value that is a non-scientific number, you don’t need to make it an object with a value-unit pair. For example, index of something or count of something | No |
| 10 | Spell out acronyms and abbreviations as the full names if possible to avoid ambiguities | No |
| 11 | Add fields in required to objects when the fields must be present in the IDS JSON | No |
| 12 | Avoid using JSON schema keywords as field names like type, properties, enum, const, title | No |
| Top-level Fields | ||
| 1 | samples schema must present for IDS designed by TS. You have to use the exact schema provided in IDS Design Conventions - Schema Templates#Samples. | Yes |
| 2 | users schema must present for IDS designed by TS. You have to use the minimal schema.json defined in IDS Design Conventions - Schema Templates#Users and build on top of that. You cannot change what's already in the template. | Yes |
| 3 | If you want to use related_files, you have to use the exact schema defined in IDS Design Conventions - Schema Templates#Related-Files. | Yes, if used |
| 4 | If you want to use systems, you have to use the minimal schema.json defined in IDS Design Conventions - Schema Templates#Systems and build on top of that. You cannot change what's already in the template. | Yes, if used |
Common IDS Fields
GSF: Globally-Shared Field
DSF: Domain-Shared Field
required: the field must be present in every IDS JSON, i.e. this field must be defined in "required":[] array.
Not Null: the value of this field must have a value and cannot be null. Fields do not have this condition are nullable.
Non-Extendable: the fields in the object are a fixed set. You can't add arbitrary fields to this object. So in the schema.json, additionalProperties for this object must be set to false. It does not apply to nested objects.
What is GSF and DSF?
There are 3 levels of scope where an IDS field can belong to:
- GSF - shared across all instruments.
- DSF - shared across all instruments of the same type (i.e. liquid scintillation counter). A fixed set of strings.
- Regular field - lives only in one instrument IDS. It's an arbitrary string.
For GSF and DSF:
- The field key is guaranteed to be the same across different IDS
- The field value type is guaranteed to be the same across different IDS
- For DSF, the data inside this field will share a similar structure across different IDS
- For GSF:
- The field does not need to be defined in every IDS unless specified as
required - if it's defined in the IDS, there is usually a set of predefined fields for you to use. So please check those out before defining your own
- if it's defined in the IDS, it can be extended unless specified with Non-Extendable
- The field does not need to be defined in every IDS unless specified as
Common IDS Fields Explained
- @idsType: <string> GSF.
required. Not Null. Not from the raw file. Defined by TetraScience. - @idsNamespace: <string> GSF.
required. Not Null. Not from the raw file. Defined by TetraScience. - @idsVersion: <string> GSF.
required. Not Null. Not from the raw file. Defined by TetraScience. - @idsConventionVersion: <string> GSF.
required. Not Null. Not from the raw file. Defined by TetraScience. - systems[]: <array> GSF. You can create your schema on top of
systemsschema template in IDS Design Conventions - Schema Templates#Systems.- id: <string>
- name: <string> free-form, instrument name from the raw file. It's usually how the users name their instruments.
- vendor: <string> GSF.
required. The manufacturer, like "Perkin Elmer", "Agilent". More about design in systems - vendor, model, type. - model: <string> GSF.
required. The instrument model, like "AKTA". More about design in systems - vendor, model, type. - type: <string> GSF.
required. The type of this instrument, like "plate reader", "liquid chromatography system", "mass spectrometer". More about design in systems - vendor, model, type. - serial_number: <string> you should use string even it's a pure number-based serial
- firmware[]: <array> GSF. See IDS Design Conventions - Schema Templates#Firmware
- software[]: <array> GSF. See IDS Design Conventions - Schema Templates#Software
- component: <object> hardware components belong to this instrument. Each instrument's components will be different so this field cannot be generalized to fit all the IDS
- users[]: <array> GSF. You have to build users schema on top of the template in IDS Design Conventions - Schema Templates#Users.
- samples[]: <array> GSF. Non-Extendable. You have to use the exact schema in IDS Design Conventions - Schema Templates#Samples.
- runs[]: <array> GSF
- name: <string>
- experiment: <object> metadata about the experiment this run is associated with
- logs[]: <array> each item is one log object or string
- instrument_status[]: <array> the status of the components of the instrument
- name: <string> name of the status. If there is a general instrument status, you can use "general"
- value: <string> text-based status like "completed", "failed", "aborted", "errored"
- methods[]: <array> GSF. You have the freedom to define anything here.
- results[]: <array> GSF
- related_files[]: <array> GSF. Non-Extendable. If you use this field, you have to use the exact schema in IDS Design Conventions - Schema Templates#Related-Files. More about the design in File Pointer Pattern.
- datacubes[]: <array> GSF. If you use this field, you have to build your schema on top of IDS Design Conventions - Schema Templates#datacubes-Pattern. More about the design in datacubes Pattern.
- name: <string>.
required - measures[]: <array> GSF. Non-Extendable
- dimensions[]: <array> GSF. Non-Extendable
- name: <string>.
results vs datacubes
datacubes is just another representation of your data and the major difference is you will have dimensionality of your data in datacubes.
results and datacubes can both contain results from the run, the decision is based on
- Do we want to search the data using Elasticsearch? - Yes:
results - Is the data multidimensional? - Yes:
datacubes - Is the data meaningful only if they are analyzed all together? Yes:
datacubes - Is an individual measured data point meaningful by itself? Yes:
results
Non-Top-Level GSFs
Not all GSFs are on the top-level. You sometimes will put GSFs in a nested object.
- comments[]: <array>. Always an array of strings
- time: <object>. More about the design in Date and Time
- start: process/experiment/task start time
- created: data created time
- stop: process/experiment/task stop/finish time
- duration: process/experiment/task duration (this may not be in ISO format)
- lookup: data lookup time
- last_updated: data last updated time of a file/method
- acquired: data acquired/exported/captured time
- modified: data modified/edited time
- maximum: <number>
- minimum: <number>
How to Create schema.json
You need to first create schema.json first. Then you can generate elasticsearch.json and create athena.json.
Although schema.json can be manually created, it's too laborious and requires you to be meticulous to JSON schema syntax. Copying and pasting is also not scalable if you have multiple IDS to create and they share some common fields that you want to reuse.
Thanks to Pydantic, there is a programmatic way to create IDS using Python and many great features Python provides. The tutorial for Pydantic will be coming Q1, 2022.
Top-Level Fields
To create an IDS, first you can roughly categorize the raw data into 3 high-level categories: metadata, input, and output. Then for each category, you should decide which top-level field your data belongs to. Below are the top-level fields for each category:
metadata: the facts about the world
systems[]: contains the instrument or the sensor information. It only contains information regarding which instruments we use, but not how those instruments are configured for the experiment, which goes to "runs".users[]: contains user information.samples[]: contains sample information.runs: contains run metadata, i.e. the “fact” of this run. e.g. run status, experiment metadata, and calibration. Each run can have its own metadata so it’s an array of objects.related_files[]: contains file pointers to files that are parsed from the raw file and stored in the data lake, for example, image files. Some raw data has metadata about some other files, which should not be added to this field because they are not in the data lake thus no file pointer. Instead, you can add it to fields like "runs", "methods", etc.
input: user-defined inputs
methods[]: refers to the method or protocols or parameters used. It contains the user configuration to a run. Each run can have its own parameters so it’s an array of objects. It varies and depends on the type of instrument, and the type of experiment you are running.
output: run results
results[]: contains the "output" of the run. It varies and depends on the type of instrument, and the type of experiment you are running.datacubes[]: It also contains the "output" of the run. But "datacubes" stores data in a different format than "results". It's a multi-dimensional matrix. e.g. chromatogram data or spectrum graphs. Because TetraScience will do some special processing when storing "datacubes" data in Athena, "datacubes" has to follow a specific pattern. Please see datacubes Pattern.
Basic Types
Null
When do we include fields with null values? Here is the rule you can follow:
| Property name example | Top level property? | GSF or DSF? | Property exists in raw files? | Include in IDS JSON? | Include in schema.json? |
|---|---|---|---|---|---|
abc | No | No | Always | Yes | Yes |
abc | No | No | Sometimes | Yes, null when needed | Yes |
users | Yes | Yes | Always | Yes | Yes |
users | Yes | Yes | Sometimes | Yes, null when needed | Yes |
users | Yes | Yes | Never | No | Yes (because users field is special and we need to include it in every instrument IDS) |
users[*].* | No | Yes | Always | Yes | Yes |
users[*].* | No | Yes | Sometimes | Yes, null when needed | Yes |
users[*].* | No | Yes | Never | No | Yes (because users field is special and we need to include it in every instrument IDS) |
methods[*].mode_A | No | No | Sometimes, only when mode A is selected | Yes, when mode A is selected. No if not. | Yes, optional |
samples[*].* | No | Yes | Always | Yes | Yes |
samples[*].* | No | Yes | Sometimes | Yes, null when needed | Yes |
samples[*].* | No | Yes | Never | No | Yes (because samples field is special and we need to include it in every instrument IDS) |
Boolean
Any field with the value of "True" or "False" and "Yes" or "No" (case-insensitive) is set as a "boolean" data type. They will all be converted to true or false respectively.
String
Avoid using format for fields with string type. This will make the schema.json fragile in the following situations
- timestamp
<https://github.com/epoberezkin/ajv#redos-attack>
Object
All fields with object type should only be with object type.
YES: "type": "object"
NO: "type": ["object", "null"]
Array
All fields with array type should only be with array type.
YES: "type": "array"
NO: "type": ["array", "null"]
For each field that has type array, you have to make sure the items in the array all share the same type, null is allowed.
Example
YES: ["a", "b", "c"]
YES: [12, 34, 56]
YES: [12, 34, null]
YES: ["a", "b", null]
NO: ["a", "b", 124]
Multiple types
Sometimes a value can have multiple types. For example, it can be a "string" or "null". In this case, you have to specify ["string", "null"] as the type. But you can't have two literal types like ["string", "number"]
Data Field
$id
Make sure it follows the same convention as other IDS. Each JSON schema should have a $id on the root level that looks like
"$id": "https://ids.tetrascience.com/common/instrument-a/v1.0.0/schema.json"$schema
Since JSON Schema is itself a JSON file, it’s not always easy to tell when something is JSON Schema or just an arbitrary chunk of JSON. The $schema keyword is used to declare that something is JSON Schema. We include it in every schema.json we have:
"$schema": "http://json-schema.org/draft-07/schema#"@idsNamespace, @idsType, @idsVersion, @idsConventionVersion
It is important for the schema.json and the IDS JSON itself to indicate which IDS type and IDS version the file is about, this way it's self-explanatory. For every IDS schema.json, include the following at the top of the schema. @idsType refers to the schema name, such as qpcr-thermofisher-viia7.
Example
{
"type": "object",
"required": [
"@idsNamespace",
"@idsType",
"@idsVersion",
"@idsConventionVersion"
],
"properties": {
"@idsNamespace": {
"type": "string",
"const": "common"
},
"@idsType": {
"type": "string",
"const": "example"
},
"@idsVersion": {
"type": "string",
"const": "v1.0.0"
},
"@idsConventionVersion": {
"type": "string",
"const": "v1.0.0"
}
}
}description
description is a JSON schema keyword.
It must be a string. description will provide more explanation about the field. This description should consist of full, grammatically correct, and formatted sentences (capitalization, period, etc).
Some common usages of description are
- the mapping of raw data to schema - where in the raw data file you can find this field
- explain why certain unit is chosen. For example, raw unit be converted to QUDT unit
- give the fully-spelled out version of an abbreviation or an acronym
Be aware the keyword is description, not $description.
id and name
id is a string. It's machine-readable. It's usually a unique value across all the data produced by the same instrument
name is human-readable and has actual meaning. It's usually defined by human and there is no guarantee it will be unique across all data
Date and Time
Use Cases
- Time will be searchable once it’s parsed into ISO UTC format (see ElasticSearch built-in date format) otherwise we can’t guarantee instrument native date format can be understood by ES
- Parsing time into ISO UTC format unifies the format in IDS so there is no ambiguity on the date format
- There is MM-DD-YYYY format and DD-MM-YYYY format and we cannot tell if 01-02-2020 is Jan 02 or Feb 01. But ISO format is very clear.
Format
- Date time is parsed into ISO 8601 format with UTC, e.g. 2021-01-26T23:19:09Z. Use UTC (Zulu) time. Convert time zones to Zulu time.
- ES date detection is currently disabled by TS. This means dynamic mapping is disabled. We do this because we don’t want ES index to fail if some malformed date format is used. So we are indexing every string type as keyword type.
- However, you can still use range query to search date (Evan confirmed this. But this is in contradiction with the range query ES doc)
- We don’t plan to store the original date time value in the IDS JSON because it can be confusing and it’s also redundant information if we already have the parsed value stored.
- If there is no timezone or time offset information, the util function will convert the time to ISO without timezone, e.g. "Aug 22 2020 03:30:00 PM" will be converted to "2020-08-22T15:30:00.000"
- Do not use the JSON Schema format:
date-timein the IDS. If you can not convert timestamp to ISO timestamp, keep the original timestamp format in the IDS JSON. It's better to keep more information, especially there can be all sorts of timestamp spellings.
Parse
- Use convert_datetime_to_ts_format util function in
ts-task-script-utilsrepo to convert datetime strings to TS format. - If in the date-time string "time" is not available, just use "date" as the value (still following the ISO format, e.g. "2020-09-29"). Vice versa if only "time" is available, e.g. "12:00:38.012".
- If you don't know the timezone or time offset, it is a "local time" which can't be converted to Zulu time so don't include the "Z" at the end of the string, e.g. "2020-09-29T12:00:38.000". Note the util function will add "Z" so you need to remove that yourself.
Unit
Non-scientific measurements should just be regular numbers
If the unit is available from the raw data file, you should convert it to QUDT units.
Use ArbitraryUnit when there should be a unit, but the unit doesn't mean anything outside of instrument scope. For example, light absorbance.
Use Unitless for fields with no explicit unit, for example: pH
Use null when there should be a unit, but you are not able to find it in the raw file. Or, if you are very certain what unit should be used, you can hardcode the QUDT unit.
Use Percent for percentages
Example
{
"name": "some string",
"ph": {
"value": 7.1,
"unit": "Unitless"
},
"weight": {
"value": 2.3,
"unit": "Gram"
},
"numerical_variable_with_unknown_unit": {
"value": 102,
"unit": null
}
}QUDT Unit
How to Find QUDT Unit
QUDT.org is a 501(c)(3) not-for-profit organization founded to provide semantic specifications for units of measure, quantity kind, dimensions and data types. QUDT is an advocate for the development and implementation of standards to quantify data expressed in RDF and JSON. Our mission is to improve the interoperability of data and the specification of information structures through industry standards for Units of Measure, Quantity Kinds, Dimensions and Data Types.
To find the spelling in QUDT for the unit you want to use, follow the steps below
- Download qudt-ext.ttl
- Download Protege, an open source tool to browse ontology.
- Load qudt-ext.ttl into Protege and then search for "second".
It will return the following search results and in the ontology "second" is represented by Second <http://qudt.org/vocab/unit#SecondTime>, thus we will use "SecondTime" in the IDS JSON, namely whatever that comes after the "#".
If the following window does not show automatically, go to "Window"→"Tabs" and make sure "Entities" is selected; then in the main UI, go to the "Entities" tab and select the "Individuals" subtab.
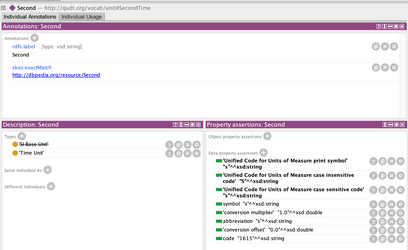
Screenshot: Protege QUDT Window
Allotrope unit can be searched here: <http://purl.allotrope.org/ontology/qudt-ext>
Unit of molecular weight: in the chemistry field, "g/mole" is commonly used as the molecular weight unit, however, the unit of molecular weight in QUDT is "KilogramPerMole". We will use "GramPerMole" for now, need to revisit later.
definitions
definitions is a JSON schema keyword
If you find yourself writing the same schema over and over again in the IDS, you can create JSON schemas definitions and use that with $ref. It can not only save your time, but also greatly reduce number of lines in the file and improve readability. You can find some examples from IDS - Schema Templates.
systems - vendor, model, type
Schema template available in IDS Design Conventions - Schema Templates#Systems
How to decide what value to use for each field:
TetraScience is following an internal document containing vendor/model/type values. So all IDS JSONs will use the same consistent value. This internal document is not available to the public.
If the vendor/model/type is not available from the raw file but it's known this parser will only be used by one model or several models from the same vendor, it is ok to hardcode the value using the values from the internal doc.
If the value is not available from the raw file and the parser will be used by different vendor instruments, use "null".
samples - batch, set, lot
Schema template available in IDS Design Conventions - Schema Templates#Samples
These terms are used somewhat interchangeably. However, they mean discrete things to scientists, especially in processes that operate under 21 CFR 210.3
- batch
- 21 CFR 210.3 definition: a specific quantity of a drug or other material that is intended to have uniform character and quality, within specified limits, and is produced according to a single manufacturing order during the same cycle of manufacture
- It is a concept in drug development and more macro compared to
set. Specifically, a batch is the amount of a product at the end of a given process, with uniform character and quality, produced in a single manufacturing operation.
- set
- It is like a sequence, representing a small group of items used in one transaction. An example from scientific usage involves a dissolution or solubility study; the "sample set" is the specific collection of tubes a scientist analyzes to obtain aggregate statistics about the sample (SD, mean/median, variability, etc)
- lot
- 21 CFR 210.3 definition: a batch, or a specifically identified portion of a batch, having uniform character and quality within specified limits; or, in the case of a drug product produced by continuous process, it is a specific identified amount produced in a unit of time or quantity in a manner that assures its having uniform character and quality within specified limits.
- A lot as defined in the CFR is like a "sub-batch" - it's an amount of material produced per unit time in a continuous process. Think about cookies. If you baked a single bowl of batter and got a tray, it would be a
batchof cookies. However, if you had a conveyer belt oven continuously producing cookies, then alotwould be the amount of cookies produced between 10:15-10:20 AM last Tuesday. Properties would be measured and assigned to each lot to gauge consistency and QC.
Patterns
datacubes Pattern
Schema template available in IDS Design Conventions - Schema Templates#datacubes-Pattern
datacubes is a reserved key and has a specific structure in the IDS:
nameof each datacube should be unique to accommodate grouping in ADF filesdatacubes[*].dimensions[*].scaletype can only benumberor["number", "null"]- Dimensions relate to measure in an "outside-in" relationship. i.e. accessing data from measures follows
datacubes[*].measures[*].value[dim_0_idx][dim_1_idx]...[dim_n_i] - You have to specify
minItemsandmaxItemsfor measures and dimensions like the example below to describe the dimensionality of yourdatacubes. The number of items in the datacube has to be fixed byminItemsandmaxItems, namely minItems and maxItems have to be the same value and equal, otherwise Athena won't work. This is a known limitation. - All the data cubes should have the same structure. Namely, the same number of
measuresanddimensions. For example, if there are two datacubes, they can NOT be a 2-dimensional cube and a 3-dimensional cube
Example datacubes:
datacubes Pattern - Example
"datacubes": [{
"name": "3D chromatogram",
"description": "More information about the data cube. (Optional)",
"id": "optional identifier",
"measures": [{
"name": "intensity",
"unit": "ArbitraryUnit",
"value": [
[111, 112, 113, 114, 115],
[221, 222, 223, 224, 225],
[331, 332, 333, 334, 335]
]
}],
"dimensions": [{
"name": "wavelength",
"unit": "Nanometer",
"scale": [180, 190, 200]
}, {
"name": "time",
"unit": "MinuteTime",
"scale": [1, 2, 3, 4, 5]
}]
}]You can check the public-facing document for more details on datacubes:
- How IDS JSONs will be indexed into SQL tables: https://developers.tetrascience.com/docs/sql-tables
datacubesoverview: https://developers.tetrascience.com/docs/understanding-data-cubes
Advanced Material
datacubes - Advanced Material
The data cube structure is designed to maximize storage efficiency. It will be converted to a CSV that looks like the following
wavelength, time, intensity 180 1 111 180 2 112 180 3 113 190 1 221 190 2 222 190 3 223 200 1 331 200 2 332 200 3 333
The conversion to CSV/Parquet will make the size the file larger, and here is the comparison for a 2-dimensional data cube of size N * M, for example, intensity vs wavelength & time
In the IDS JSON, the size is proportional to O(N * M) + O(M) + O(N) ~ O(N * M), when N and M are large
In the CSV/Parquet structure, the size is proportional to O(3 * N * M)
Thus expect a 3 times increase in file size. But of course, Parquet/CSV has higher potential to compress.
Parameter Pattern
For user-defined parameters, like scouting_variables in AKTA, custom_fields in Empower, sample_properties, we have a pattern for it: IDS Design Conventions - Schema Templates#Parameter-Pattern
Example:
Parameter Pattern - Example
"properties": [
{
"key": "concentration",
"value": "128 mg/ml",
"value_data_type": "number",
"string_value": null,
"numerical_value": 128,
"numerical_value_unit": "MilligramPerMilliliter",
"boolean_value": null
}
]File Pointer Pattern
Some RAW files contain large data sets that cannot be parsed or should not be parsed, such as associated image files or large proprietary large files. These files can be referenced within the IDS file through a pointer. A pointer always contains the following information:
{
"fileId": "<the uuid for each file in ts data lake, uuid>",
"fileKey": "<s3 file key>",
"version": "<s3 file version number>",
"bucket": "<the s3 data lake bucket>",
"type": "s3file"
}The structure of this information is critical for two reasons:
- It can easily be passed to
context.read_filefor reading from AWS S3 - These keys are used to identify files that are pointed to when converting IDS to ADF.
Modifier Pattern
Sometimes the array value type varies depends on the experiment and there is a "modified" before the number. So something like ["<1.0E-12", 6.026e-07] is possible to get from instrument files. The way we can support it is to change it using the Modifier Pattern.
Example:
Modifier Pattern - Example
[
{
"value": 1.0E-12,
"modifier": "<"
}, {
"value": 6.026e-07,
"modifier": null
}
]And your schema will be like
{
"value": {
"type": "number"
},
"modifier": {
"type": ["string", "null"],
"enum": ["<", ">", "<=", ">=", null]
}
}Ontology Pattern
Optional fields such as @type, @prefLabel and @id can be added in IDS to encode Linked Data defined by Allotrope Foundation. At the moment, these are only defined in the following IDS: cell-counter, conductivity-meter, blood-gas-analyzer, and pH-meter.
@type: for the Allotrope parameters URI, which are the standard vocabulary for the representation of laboratory analytical processes, including metadata, process, and results@prefLabel: the preferred label for Allotrope Data Format (ADF)@id: URI for QUDT unit
Example:
Ontology Pattern - Example
"osmolarity": {
"@type": "http://purl.allotrope.org/ontologies/result#AFR_0001586",
"@prefLabel": "osmolality",
"type": "object",
"properties": {
"value": {
"type": "number"
},
"unit": {
"@id": "http://purl.allotrope.org/ontology/qudt-ext/unit#OsmolesPerLiter",
"@prefLabel": "osmoles/liter",
"type": "string",
"const": "OsmolesPerLiter"
}
}
}Updated 5 days ago